Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS.
DLQ для Apache Kafka в Spark-приложении
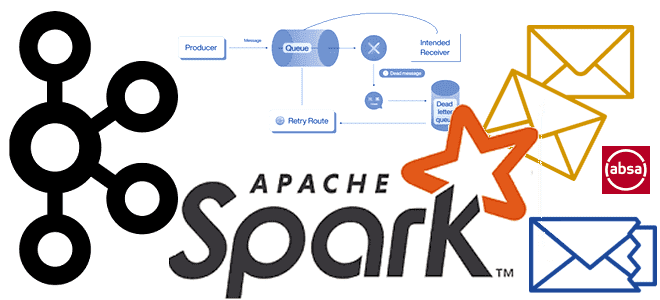
Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается. Обычно дата-инженер узнает об этом уже по факту, когда нижестоящие компоненты конвейера, т.е. приложения-потребители перестают получать данные. Избежать такой ситуации поможет так называемая использовать очередь недоставленных сообщений (Dead Letter Queue, DLQ), где будут скапливаться сообщения, которые не могут быть обработаны потребителем, чтобы избежать потери данных и остановки всего конвейера.
Изначально Apache Kafka, в отличие от RabbitMQ, не позволяет организовать такую DLQ-очередь средствами самой платформы. Проверка корректности сообщения реализуется в коде приложения-потребителе с помощью блока try-cath для обработки ожидаемых или непредвиденных исключений. А отправка таких некорректных сообщений в DLQ-топик реализуется через вызов метода send() API продюсера. Подробнее об этом мы писали здесь и здесь.
Однако, реализовать это на практике не так просто. Рассмотрим пример приложения Spark Streaming, которое читает поток данных из топика Kafka одним из способов, описанных в этой статье. Предположим, в этот топик данные в формате AVRO публикуют несколько продюсеров. Приложения-продюсеры управляются разными группами разработчиков, а реестр схем Apache Kafka используется для эволюции схемы данных, гарантируя, что продюсер и потребитель хранят данные в одной и той же структуре. Schema Registry получает схему на стороне продюсера, преобразуя эти данные в двоичный формат. На стороне потребителя реестр схем используется для анализа двоичных данных в читаемые данные. О том, как работает реестр схем, мы рассказывали в этом материале.
Но если один из продюсеров публикует данные, которые не укладываются в согласованную схему, может возникнуть проблема. Потребитель Spark Streaming считывает пакет данных из топика Kafka и должен анализировать полезную нагрузку. Но если текущая версия схемы данных несовместима с ожидаемой, синтаксический анализ пакета завершается неудачно. Поскольку пакеты обрабатываются последовательно, приложение-потребитель перестает обрабатывать новые данные. А в связи с моделью отложенных вычислений, характерной для Spark, преобразования данных выполняются только в будущем, при вызове действий. Поэтому приложение терпит сбой, поскольку не может выполнить объявленную операцию. Это чревато потерей данных и задержке всего потокового конвейера.
Чтобы избежать такой ситуации, необходимо предусмотреть возможность валидации полезной нагрузки сообщения, отправленного в Kafka. При работе с форматом AVRO пригодится библиотека ABRiS (Avro Bridge for Spark), которая обеспечивает мост между строковым бинарным форматом AVRO и структурами данных Spark. ABRiS предоставляет функцию from_avro, которую можно вызвать внутри Spark-приложения. Эта функция принимает столбец структуры данных Spark, содержащий двоичные данные AVRO и некоторую конфигурацию, и возвращает столбец struct со всеми проанализированными данными AVRO. Вот пример Java-кода, который показывает, как Spark-приложение может использовать ABRiS для анализа данных AVRO:
val abrisConfig = AbrisConfig.fromConfluentAvro.downloadReaderSchemaByLatestVersion
.andRecordNameStrategy(schemaName, "com.riskified.tests")
.usingSchemaRegistry(schemaRegistryUrl)
df.withColumn("parsed_value", from_avro(col("value"), abrisConfig))
Примечательно, что ABRiS поддерживает полную интеграцию с платформой Confluent, включая реестр схем со всеми доступными стратегиями именования и эволюцией схемы. Библиотека позволяет конвертировать записи AVRO из любого места (Kafka, Parquet, HDFS и т.д.) в структуры данных Spark и преобразовывать датафреймы в записи AVRO, даже без указания схемы. Как это работает, рассмотрим далее.
Возможности и примеры использования библиотеки ABRiS
API библиотеки ABRiS почти идентичен встроенной поддержке Spark для AVRO, но предоставляет дополнительные функции. В основном это поддержка реестра схем, а также бесшовная интеграция со форматом данных AVRO в Confluent. API состоит из двух выражений Spark SQL: to_avro и from_avro, а также гибкого конфигуратора AbrisConfig, который позволяет выбрать один из четырех основных типов конфигурации: toSimpleAvro, toConfluentAvro, fromSimpleAvro и fromConfluentAvro. Это позволяет получить нужную схему AVRO, например:
val abrisConfig = AbrisConfig
.fromConfluentAvro
.downloadReaderSchemaByLatestVersion
.andTopicNameStrategy("topic123")
.usingSchemaRegistry("http://localhost:8081")
import za.co.absa.abris.avro.functions.from_avro
val deserialized = dataFrame.select(from_avro(col("value"), abrisConfig) as 'data)
В ABRiS есть метод, который позволяет автоматически генерировать схему из столбца lfnfahtqvf Spark:
val schema = AvroSchemaUtils.toAvroSchema(dataFrame, "input")
Можно использовать SchemaManager напрямую для выполнения операций с реестром схем. Конфигурация идентична клиенту реестра схем. SchemaManager — это просто оболочка для клиента, предоставляющая полезные методы и абстракции, например:
val schemaRegistryClientConfig = Map( ...configuration... )
val schemaManager = SchemaManagerFactory.create(schemaRegistryClientConfig)
// Downloading schema:
val schema = schemaManager.getSchemaById(42)
// Registering schema:
val schemaString = "{...avro schema json...}"
val subject = SchemaSubject.usingTopicNameStrategy("fooTopic")
val schemaId = schemaManager.register(subject, schemaString)
// and more, check SchemaManager's methods
Стратегии именования RecordName и TopicRecordName позволяют одному топику получать полезную нагрузку сообщений с разной схемой данных, которые не обязательно должны быть совместимы. При потреблении данных из Kafka, они будут храниться в виде двоичного столбца в датафрейме Spark, но после преобразования в типы данных Spark должны быть разделены на несколько датафреймов, поскольку все строки в датафрейме должны иметь одинаковую схему. Поэтому при наличии несовместимых типов данных AVRO в датафрейме, следует их сперва разделить по нескольким датафреймам, каждый из которых имеет свою схему данных. Для этого как раз и пригодится библиотека ABRiS, которая также предоставляет удобные методы преобразования между схемами AVRO и Spark. Предположим, есть схема AVRO, которую надо преобразовать в схему Spark SQL:
val avroSchema: Schema = AvroSchemaUtils.load("path_to_avro_schema")
val sqlSchema: StructType = SparkAvroConversions.toSqlType(avroSchema)
Выполнить обратную операцию поможет следующий код:
val sqlSchema = new StructType(new StructField .... val avroSchema = SparkAvroConversions.toAvroSchema(sqlSchema, avro_schema_name, avro_schema_namespace).
Если необходимо использовать пользовательскую логику для преобразования AVRO в Spark, можно реализовать трейт SchemaConverter. Пользовательский класс загружается в ABRiS с помощью SPI-интерфейса провайдера сервисов. Поэтому разработчику необходимо зарегистрировать свой класс в каталоге ресурсов META-INF/services. Затем можно настроить пользовательский класс с его кратким именем или полным именем, например:
package za.co.absa.abris.avro.sql
import org.apache.avro.Schema
import org.apache.spark.sql.types.DataType
class CustomSchemaConverter extends SchemaConverter {
override val shortName: String = "custom"
override def toSqlType(avroSchema: Schema): DataType = ???
}
Конфигурация ABRiS может выглядеть так:
val abrisConfig = AbrisConfig
.fromConfluentAvro
.downloadReaderSchemaByLatestVersion
.andTopicNameStrategy("topic123")
.usingSchemaRegistry(registryConfig)
.withSchemaConverter("custom")
Благодаря наличию в библиотеке ABRiS класса DeserializationExceptionHandler, можно расширить его и решить переопределить метод дескриптора, который будет вызываться при возникновении ошибки сериализации, например, слишком большое число, приводящее к переполнению:
class DlqRecordExceptionHandler extends DeserializationExceptionHandler {
def handle(exception: Throwable,
deserializer: AbrisAvroDeserializer,
readerSchema: Schema): Any = {
println("Malformed record detected. Replacing with default record.", exception)
val recordBuilder = new GenericRecordBuilder(readerSchema)
.set("id", -1L)
.set("time", 0L)
deserializer.deserialize(recordBuilder.build())
}
}
Конфигурация ABRiS для этого случая будет выглядеть так:
val abrisConfig = AbrisConfig.fromConfluentAvro.downloadReaderSchemaByLatestVersion .andRecordNameStrategy(schemaName, "com.riskified.tests") .usingSchemaRegistry(schemaRegistryUrl) .withExceptionHandler(new DlqRecordExceptionHandler)
В следующем коде фильтруются строки с идентификатором -1, который является сигнальным значением созданного DeserializationExceptionHandler. Приложение Spark Streaming отправляет некорректные строки в DLQ-топик Kafka, продолжая обрабатывать сообщения с допустимой схемой данных:
val parsedAvroDf = df.withColumn("parsed_value", from_avro(col("value"), abrisConfig))
parsedAvroDf.writeStream
.foreachBatch {
(batchDF: DataFrame, batchID: Long) =>
val malformedRowsDF = batchDF.filter(col("parsed_value.id") === -1)
.drop("parsed_value")
malformedRowsDF
.write
.format("kafka")
.option("kafka.bootstrap.servers", kafkaServerUrl)
.option("topic", "malformed.dlq")
.save()
val validRows = batchDF.filter(col("parsed_value.id") =!= -1)
.select(col("parsed_value.*"))
validRows
.write
.format("console")
.mode("append")
.save()
}
.start()
.awaitTermination()
Таким образом, библиотека ABRiS позволяет получить базовую реализацию приложения Spark Structured Streaming, которая не будет давать сбой, когда полезная нагрузка от продюсера, опубликованная в Kafka, не соответствует ожидаемой схеме. Однако, для использования этого пакета в производственном развертывании надо учесть производительность процесса проверки каждой строки после синтаксического анализа, поскольку Apache AVRO является строковым форматом данных. Процесс синтаксического анализа каждой строки довольно ресурсоемкий, поэтому использовать этот прием целесообразно с учетом доли некорректных записей от их общего количества и количества нижестоящих потребителей. Для повышения эффективности и универсальности решения с ABRiS-библиотекой ее можно использовать не постоянно, а в зависимости от наступления определенных условий, например, превышение лимита некорректных записей.
Это можно обернуть в обработчик, который для каждой заданной схемы будет генерировать допустимую запись, включающую сигнальное значение, активируя механизм DLQ для этого конкретного потока. При этом необходимо, чтобы разработчики приложений-продюсеров использовали этот специальный столбец метаданных в своем коде при формировании и отправке сообщений в Kafka. Такой способ отлично подходит при работе с внутренними системами, что соответствует большинству сценариев использования Apache Kafka в качестве средства асинхронной интеграции нескольких приложений.
Читайте в нашей новой статье, как организовать обработку и логирование ошибок в потребителе Kafka без остановки конвейера, если продюсер изменил структуру данных с примерами кода на Python.
Узнайте больше про использование Apache Spark и Kafka для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Apache Kafka для инженеров данных
- Потоковая обработка в Apache Spark
- Администрирование Arenadata Streaming Kafka
- Анализ данных с Apache Spark
Источники