
Как оптимизировать многопоточную обработку в ClickHouse и эффективно распределить ресурсы ЦП между разными пользователями и запросами, спланировав рабочую нагрузку. Настройка многопоточной обработки в Clickhouse Чтобы эффективно утилизировать ресурсы для аналитической обработки огромных объемов данных, в ClickHouse можно спланировать рабочую нагрузку, определив приоритеты использования памяти, диска и ЦП для разных видов...
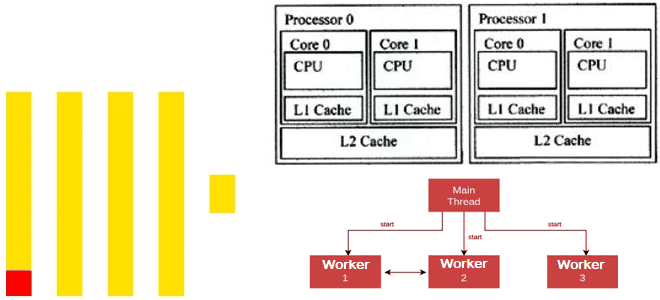
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД. Особенности многопоточной обработки в Clickhouse Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача....

Почему провайдерам Kafka как сервиса недостаточно многоуровневого хранилища (KIP-405) и зачем они предложили новое улучшение KIP-1150, меняющее архитектуру хранения и репликации данных напрямую в объектные системы. Кому и зачем понадобилась бездисковая Kafka: что не так с KIP-405 Одной из наиболее интересных тем вокруг Apache Kafka в апреле 2025 года стало...
Зачем в ClickHouse 25.4 добавлена отложенная материализация и как ленивые вычисления позволяют ускорить работу аналитической СУБД благодаря сокращению объемов читаемых данных и снижению количества операций дискового ввода-вывода. Еще раз о пользе ленивых вычислений Отложенные или ленивые вычисления (lazy evaluation), которые выполняются не сразу, а откладываются до момента, когда их результат...
Зачем нужен каталог метаданных и как он работает: построение платформы данных и управление метаданными по DAMA DMBOK. Unity Catalog и другие решения для учета источников данных и непрерывного обеспечения их актуальности. Управление метаданными по DMBOK Методологически создание и внедрение платформ данных основано на положениях DAMA DMBOK – своде знаний по...
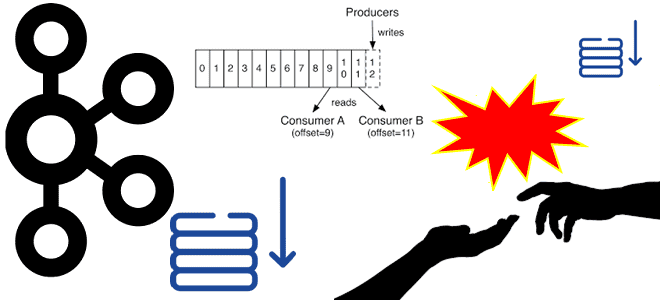
Когда и зачем фиксировать смещение потребителей Kafka вручную, с какими проблемами можно при этом столкнуться и как улучшение KIP-1094 обеспечивает целостность потоков данных в распределенных средах. Когда и зачем фиксировать смещения потребителей в Kafka вручную Недавно мы разбирали, как выполняется автоматическая фиксация смещений потребителей в Apache Kafka. Она выполняется периодически....
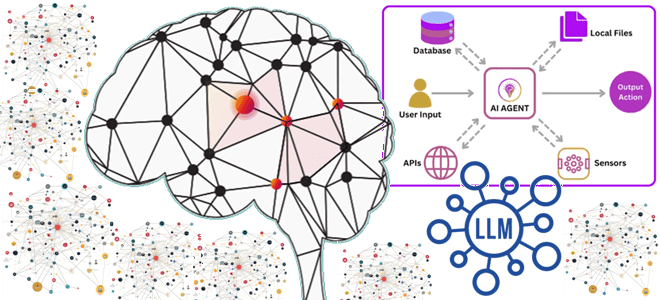
Что не так с векторным RAG: обогащение LLM данными из графовых баз с помощью MCP-протокола, вычислительных движков и коннекторов для построения ML-системы агентского ИИ. Что такое графовый RAG для LLM и ИИ-агентов Большие языковые модели (LLM, Large Language Model) и основанные на них системы агентского ИИ активно используют векторные базы...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...

Что общего у StarRocks с Trino, чем они отличаются, когда и что выбирать для практического использования: сравниваем движки для быстрой аналитики больших данных из Data Lake. Чем похожи StarRocks и Trino Вчера мы разбирали, что такое StarRocks, как устроена и где пригодится эта высокопроизводительная аналитическая база данных с открытым исходным...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...