
Отвечая на вопрос, что такое большие данные для чайников, сегодня мы рассмотрим 3 практических примера использования технологий Big Data в малом и среднем бизнесе. Никакой Rocket Science, только понятные кейсы, которые актуальны для любой современной компании, даже если она состоит из пары человек: аналитика больших данных и машинное обучение для...
В прошлый раз мы говорили о методах NLP в PySpark. Сегодня рассмотрим методы нормализации и стандартизации данных модуля ML библиотеки PySpark. Читайте в нашей статье: применение Normalizer, StandardScaler, MinMaxScaler и MaxAbsScaler для нормализация и стандартизации данных. Нормализация и стандартизация — методы шкалирования данных Нормализация (normalization) и стандартизация (standardization) являются методами...
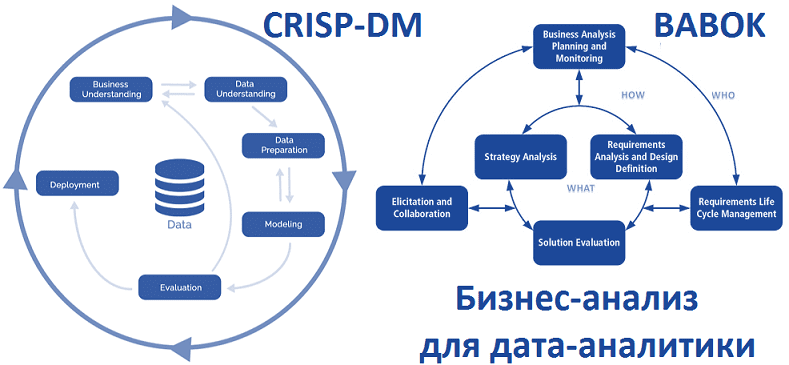
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...

В этой статье мы расскажем, что такое функционально-стоимостный анализ, как он связан с концепцией бережливого производства (Lean) и каким образом позволяет оценить и оптимизировать бизнес-процессы. Также рассмотрим, почему этому методу стоит уделить внимание при изучении основ цифровизации, а также в рамках проектов по внедрению технологий больших данных (Big Data). Что...
Сегодня мы рассмотрим, что такое расширенная аналитика и дополненное управление данными, как они связаны с цифровизацией бизнеса и почему исследовательское бюро Gartner включило эти технологии в ТОП-10 самых перспективных трендов 2020 года. Читайте в нашей статье, как машинное обучение (Machine Learning) помогает аналитикам и руководителям находить во множестве больших данных...
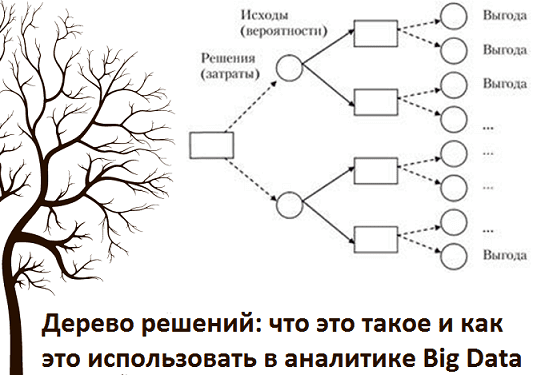
Продолжая насыщать курс Аналитика больших данных для руководителей важными понятиями системного анализа, сегодня мы рассмотрим, что такое дерево решений (Decision Tree). А также расскажем, как этот метод Data Mining и предиктивной аналитики используется в машинном обучении, экономике, менеджменте, бизнес-анализе и аналитике больших данных. Как растут деревья решений: базовые основы Начнем...

Даже после очистки и нормализации данных, выборка еще не совсем готова к моделированию. Для машинного обучения (Machine Learning) нужны только те переменные, которые на самом деле влияют на итоговый результат. В этой статье мы расскажем, что такое отбор или выделение признаков (Feature Selection) и почему этот этап подготовки данных (Data...

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их...

Нормализация данных – это одна из операций преобразования признаков (Feature Transformation), которая выполняется при их генерации (Feature Engineering) на этапе подготовки данных (Data Preparation). В этой статье мы расскажем, почему необходимо нормализовать значения переменных перед тем, как запустить моделирование для интеллектуального анализа данных (Data Mining). Что такое нормализация данных и чем она...

Извлечение признаков (Feature Extraction) из текста – часто встречающаяся задача Data Mining, а именно этапа генерации признаков. Интеллектуальный анализ текста получил название Text Mining. В этом случае Feature Extraction относится к сфере NLP, Natural Language Processing – обработка естественного языка. Это отдельное направление искусственного интеллекта и математической лингвистики [1]. Здесь...

Генерация признаков – пожалуй, самый творческий этап подготовки данных (Data Preparation) для машинного обучения (Machine Learning). Этот этап еще называют Feature Engineering. Он наступает после того, как выборка сформирована и очистка данных завершена. В этой статье мы поговорим о том, что такое признаки, какими они бывают и как Data Scientist...

Выборка, полученная в результате первого этапа подготовки данных (Data Preparation), еще пока не пригодна для обработки алгоритмами машинного обучения, поскольку информацию необходимо очистить. Сегодня мы расскажем, что такое очистка данных (Data Cleaning) для Data Mining, зачем она нужна и как выполнять этот этап Data Preparation. Что такое очистка данных для...
Мы уже рассказывали о важности этапа подготовки данных (Data Preparation), результатом которого является обработанный набор очищенных данных, пригодных для обработки алгоритмами машинного обучения (Machine Learning). Такая выборка, называемая датасет (dataset), нужна для тренировки модели Machine Learning, чтобы обучить систему и затем использовать ее для решения реальных задач. Однако, поскольку в...

CRISP-DM, SEMMA и другие стандарты Data Mining не случайно выделяют подготовку данных в отдельную фазу. Data Preparation - весьма трудоемкий итеративный процесс, который занимает до 80% всех затрат ресурсов и времени в жизненном цикле Data Mining и включает следующие задачи обработки исходных («сырых») данных [1]: Выборка данных – отбор признаков...

Как измерить управленческий опыт, предсказать и предотвратить профессиональное выгорание, быстро найти подходящего кандидата и сформировать высокоэффективную команду с помощью Big Data – разбираемся в HR-аналитике и других важных вопросах «умного» управления персоналом. Откуда в HR большие данные ? Согласно исследованию аудиторской компании KPMG, Big Data используются примерно в 60% HR-департаментов различных организаций...