Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg. Очередная попытка унификации пакетной и потоковой парадигмы Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике,...

Недавно мы писали про Apache NiFi 1.18. А 28 ноября опубликован новый выпуск - 1.19.0 и спустя немного времени первый баг-фикс к нему. Разбираемся с новинками свежего релиза самого популярного потокового ETL-маршрутизатора: новые процессоры, исправления ошибок и улучшения, о которых следует знать дата-инженеру и администратору кластера. Главные новости Apache NiFi...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...
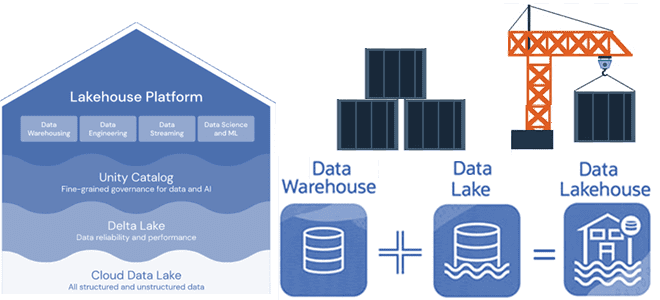
Недавно мы писали про новую гибридную архитектуру Lakehouse, которая объединяет лучше из мира озер и хранилищ данных. Сегодня разберем принципы работы и особенности построения этой архитектуры данных, включая технологии ее реализации с точки зрения дата-инженера и уделим внимание организации конвейеров аналитики больших данных. Архитектурная парадигма Lakehouse Напомним, Lakehouse — это...
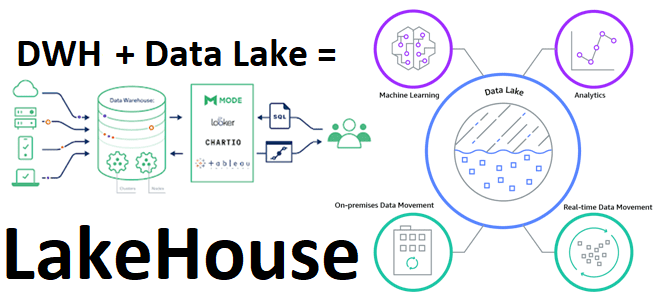
В рамках обучения дата-инженеров и архитекторов корпоративных платформ и приложений аналитики больших данных, сегодня рассмотрим, что такое LakeHouse. Как эта новая гибридная архитектура управления данными объединяет 2 разнонаправленные парадигмы хранения информации, а также чего от нее ожидают бизнес-пользователи, дата-инженеры, аналитики и ML- специалисты. Историческая справка: от DWH к Data Lake...
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone...