
В поддержку нашего нового курса для дата-инженеров Школа Больших Данных проводит очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Trino – это распределенный SQL-движок с массово-параллельной архитектурой и открытым исходным кодом. Он предназначен для работы с большими объемами данных в...
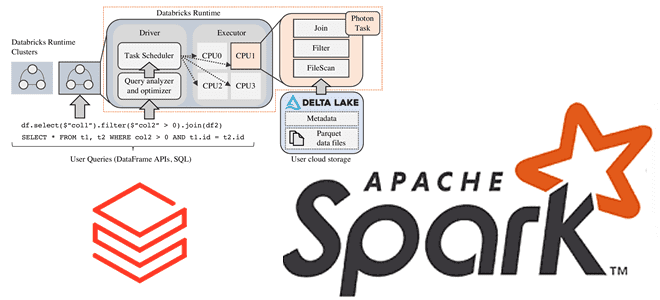
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...
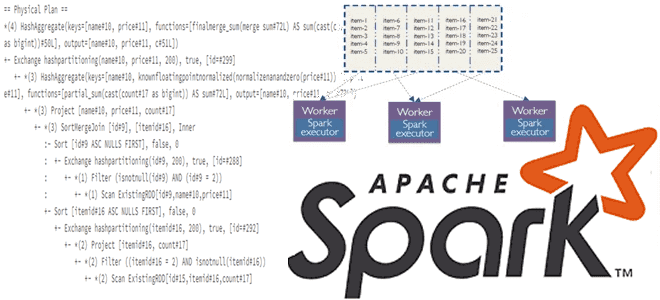
Что такое Dynamic Partition Pruning в Spark SQL, как работает этот метод оптимизации пакетных запросов, зачем его использовать в задачах аналитики больших данных, и каким образом повысить эффективность его практического применения. Что такое Dynamic Partition Pruning и зачем это нужно в Spark SQL Параллельная обработка данных в Apache Spark обеспечивается...

Как размер пакета, режим вывода и интервал срабатывания триггера потоковой обработки влияют на скорость вычислений в приложении Apache Spark Structured Streaming и как настроить эти параметры. Размер пакета при потоковой обработке данных в Spark Streaming Хотя скорость обработки данных средствами Apache Spark Streaming зависит от многих факторов, включая саму структуру...
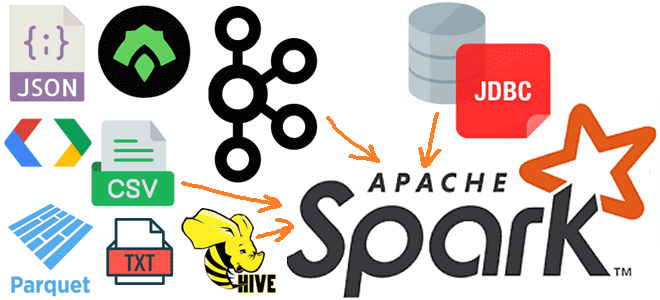
Какие источники исходных данных поддерживает Apache Spark для пакетной и потоковой обработки, обеспечивая отказоустойчивые вычисления в большом масштабе средствами SQL и Structured Streaming. Источники данных Apache Spark SQL и структурированной потоковой передачи Будучи фреймворком для создания распределенных приложений обработки больших объемов данных, Apache Spark может подключаться к разным источникам этих...

С версии 3.5.0Apache Spark поддерживает Datasketches – программную библиотеку стохастических потоковых алгоритмов. Разбираемся, что это такое, и при чем здесь алгоритм HyperLogLog. Что такое Apache Datasketches и зачем это нужно В аналитике больших данных часто возникают проблемные запросы, которые не масштабируются, поскольку требуют огромных вычислительных ресурсов и времени для получения...

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...

13 сентября 2023 года вышел Apache Spark 3.5. Знакомимся с самыми важными новинками свежего релиза: расширения Spark Connect и SQL, поддержка DeepSpeed, улучшения потоковой передачи и свежие UDF-функции Python. ТОП-5 новинок Apache Spark 3.5.0 В Apache Spark 3.5. добавлено много исправлений и улучшений, а также реализованы новые функции. Наиболее интересными...

Сегодня рассмотрим, какие улучшения Apache Spark опубликованы в 2023 году и как подать свое предложение по улучшению самого популярного вычислительного движка в стеке Big Data. Что такое SPIP и как подать свое предложение по улучшению фреймворка В любом продукте помимо ошибок есть также предложения по улучшению. В Apache Spark они...

Чем отличается оркестрация ETL-процессов в Databricks и Apache AirFlow: принципы работы, достоинства и недостатки, а также что выбирать дата-инженеру для решения практических задач. Apache AirFlow vs Spark в Databricks: сходства и отличия Облачная платформа Databricks, основанная на Apache Spark, предлагает пользователям единую среду для создания, запуска и управления различными рабочими...

Как получать результаты обработки данных с помощью Apache Spark, адресуя ИИ бизнес-запросы на английском языке: знакомимся с English SDK от Databricks. Настоящий Low Code с PySpark-AI. English SDK for Apache Spark и PySpark-AI: как это работает Большие языковые модели (LLM, Large Language Model), основанные на генеративных нейросетях, применимы не только...
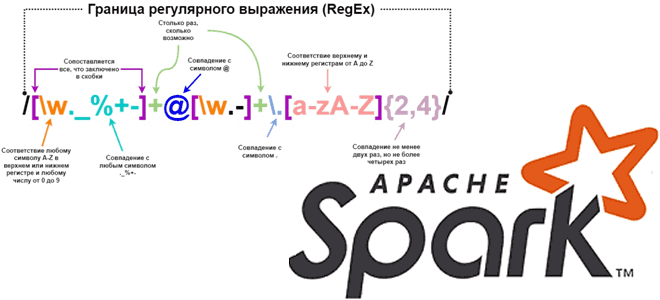
Каждый дата-инженер и аналитик данных активно использует регулярные выражения для поиска значений в тексте по заданному шаблону. Сегодня рассмотрим, как это сделать с функциями regexp_replace(), rlike() и regexp_extract в Apache Spark на примере небольшого PySpark-приложения. Как работает функция regexp_replace() Регулярным выражением называется последовательность символов, задающая шаблон соответствия в тексте. Например,...
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...

23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...
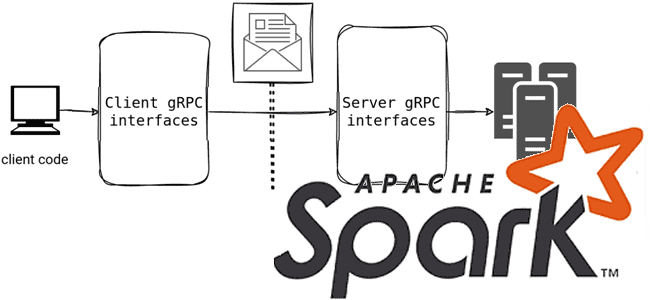
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....
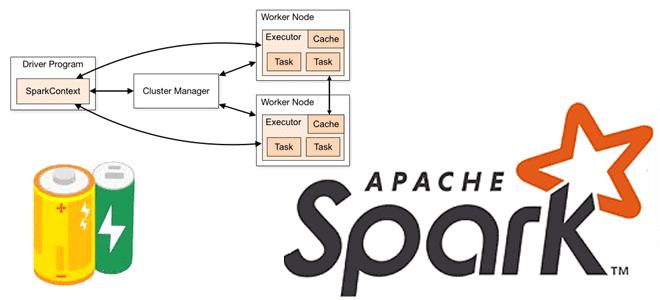
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...
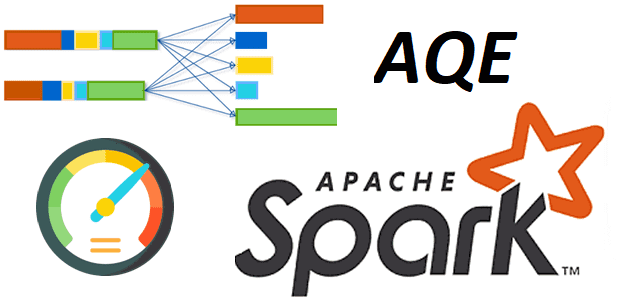
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...