 1248
1248 
Содержание
Spark Streaming – это библиотека фреймворка Apache Spark для обработки непрерывных потоковых данных, которая оперирует с дискретизированным потоком DStream, чей API базируется на отказоустойчивой структуре RDD (Resilient Distributed Dataset, надежная распределенная коллекция типа таблицы). Несмотря на позиционирование Spark Streaming в качестве средства потоковой обработки, на самом деле эта библиотека реализует микропакетный подход (micro-batch), интерпретируя поток данных как непрерывную последовательность небольших пакетов информации через регулярные интервалы времени.
Как устроен Apache Spark Streaming: основные принципы работы
В Apache Spark Streaming потоковым примитивом является дискретизированный поток DStream, который обеспечивает уровень абстракции поверх необработанных данных – событий, разделив их на блоки, аналогично RDD. Каждый набор RDD содержит события, собранные за заданный пользователем период времени – интервал пакетной обработки (batch interval), по окончании которого создается новый набор RDD, содержащий все данные из этого интервала. В начале каждого интервала (batch interval) создается новый пакет, и любые данные, поступившие в течение этого времени, включаются в пакет. В конце интервала увеличение пакета прекращается.
Непрерывный набор RDD собираются в DStream. Например, если заданный интервал пакетов составляет одну секунду, то поток DStream каждую секунду выдает пакет с одним набором RDD, который включает все данные, полученные в течение этой секунды. Таким образом, приложение Spark Streaming обрабатывает пакеты, содержащие события, работая с данными в каждом наборе RDD [1]. Spark опрашивает источник с периодичностью, заданной длительностью пакета в конкретном приложении, а затем создает пакет из полученных данных. Таким образом, каждая входящая запись принадлежит пакету DStream.
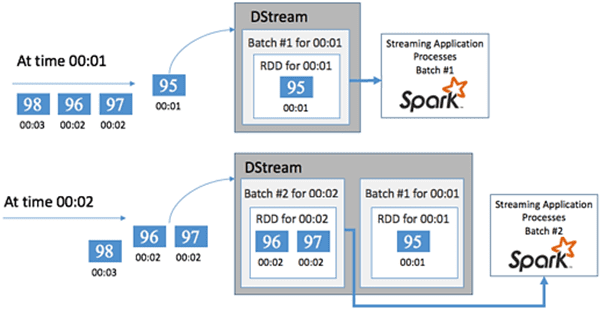
В Spark Streaming нет ограничений на тип приемника данных благодаря методу foreachRDD() для выполнения действий с потоком. Он поочередно возвращает RDD, созданные каждым микро-пакетом, позволяя выполнять над ними любые действия, например, вычисления или сохранение в хранилище. Чтобы выполнить над одним RDD несколько операций и/или отправить данные в разные приемники, его можно кэшировать.
DStreams обеспечивает параллельный механизм восстановления. Это эффективнее прямой репликации и резервного копирования, но допускает небольшое отставание в обработке потоковых данных. Для повышения отказоустойчивости приложения используются контрольные точки (checkpoints), что позволяет восстановить утраченные данные, просто вернувшись к последней контрольной точке и возобновив вычисления от нее [2].
Контрольные точки хранят метаданные приложения Spark Streaming: конфигурация и операции, а также все пакеты, которые были поставлены в очередь на обработку, но еще не обработаны. Иногда контрольные точки также включают сохранение данных в RDD для более быстрого перестроения состояния данных из RDD, управляемого Spark [2].
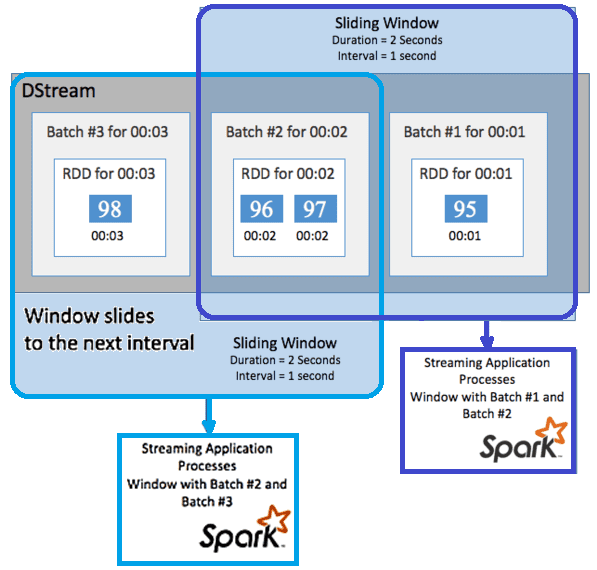
Spark Streaming поддерживает оконные операции для выполнения статистических вычислений в DStream за некоторый период времени. К примеру, скользящее окно (sliding window ) с продолжительностью и интервалом скольжения, во время которого вычисляется содержимое окна. Скользящие окна могут перекрывать друг друга: окно продолжительностью 2 секунды и интервалом скольжения в 1 секунду, что означает наличие данных в текущем окне из последней секунды предыдущего. В функции скользящего окна в API Spark Streaming входит window, countByWindow, reduceByWindow и countByValueAndWindow [1].
Архитектура и принципы работы приложений
Приложение Spark Streaming – это длительно выполняемое задание, которое получает данные из источников, обрабатывает их и передает далее в одно или несколько мест назначений. Структура такого Spark-приложения состоит из статической и динамической частей [1]:
- статическая часть определяет, откуда берутся данные, как они должны быть обработаны и куда отправляются результаты;
- динамическая часть запускает приложение на неопределенный срок, ожидая сигнал об остановке.
Статическое определение логики приложения состоит из последовательности шагов [1]:
- создание объекта StreamingContext из объекта SparkContext с указанием кластера и размера микро-пакета в секундах;
- создание потока DStream из StreamingContext;
- применение преобразований к потоку DStream;
- вывод результатов.
Обработка данных начинается только после запуска приложения. Чаще всего потоковое приложение Spark создается локально в JAR-файле, а далее развертывается в кластере или запускается через POST-операцию в REST API Apache Livy [1].
Достоинства и недостатки
Основными преимуществами, которые библиотека Spark Streaming предоставляет разработчику распределенных приложений потоковой обработки Big Data, являются следующие:
- отказоустойчивость благодаря одновременному копированию данных из внешних источников на разные узлы кластера и механизму контрольных точек;
- обработка данных в режиме near-real time;
- высокий уровень контроля над вычислениями за счет DStream API на базе RDD.
Обратной стороной этих достоинств являются следующие недостатки:
- сложность и непрозрачность RDD затрудняет работу с этой структурой данных;
- RDD API не оптимизирует цепочку преобразования данных, что приводит к увеличению временных задержек, особенно при обработке ошибочных и медленных данных;
- отсутствие опции обработки данных с использованием времени события – есть только метка времени (timestamp), показывающая, когда данные пришли в Spark. Если событие в реальном мире было создано раньше этой метки времени и принадлежало более раннему пакету, возможна потеря данных или уменьшению точности вычислений;
- разделение потоковых данных на последовательные блоки RDD происходит не мгновенно, что увеличивает задержку и снижает надежность доставки сообщений;
- микро-пакетный подход к обработке данных предполагает некоторую задержку, т.е. не в полной мере соответствует потоковой концепции в режиме реального времени.
Чтобы устранить эти недостатки, в версии Apache Spark 2.0 была выпущена библиотека Structured Streaming, реализующая модель потоковой передачи на базе SQL-модуля фреймворка, а точнее, API ее основных структур данных – Dataframe и Dataset, используемых в Java, Scala, Python и R. Подробнее об отличиях Structured Streaming от Spark Streaming читайте здесь.
Источники