Почему можно программировать на Python для разработки JVM-приложений: как Java-фреймворки с Python API, такие как Apache Spark и Flink, транслируют Python-код, организуя межпроцессное взаимодействие. Способы трансляции Python-кода для исполнения в JVM Большинство фреймворков для разработки высоконагруженных приложений написаны на Java. Например, Apache Spark или Flink. При этом они предоставляют Python...

Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения. Расширение стратегий развертывания в Kubernetes с Argo Rollouts Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows -...
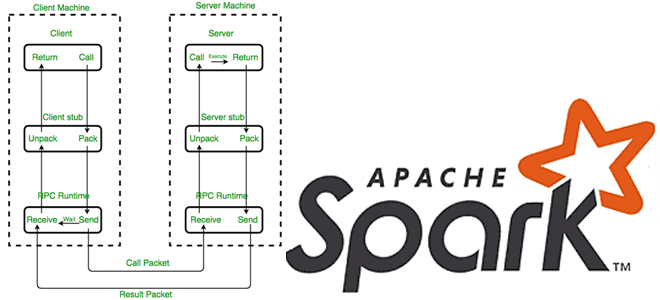
Как Apache Spark использует протокол удаленного вызова процедур для межпроцессного взаимодействия, какие параметры отвечают за эффективное выполнение RPC-запросов и где их настроить. RPC в Apache Spark Распределенный характер Apache Spark предполагает взаимодействие между компонентами, расположенными на разных узлах, например, драйвер на мастер-узле взаимодействует с исполнителями на рабочих узлах. В качестве...
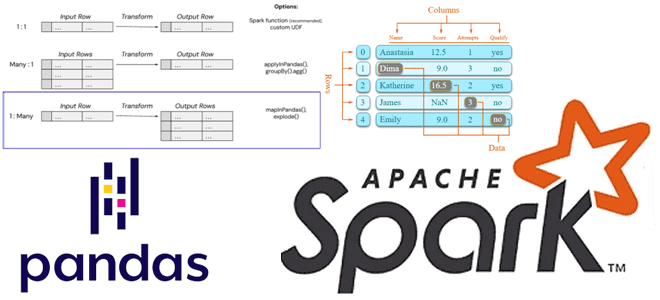
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...

Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...
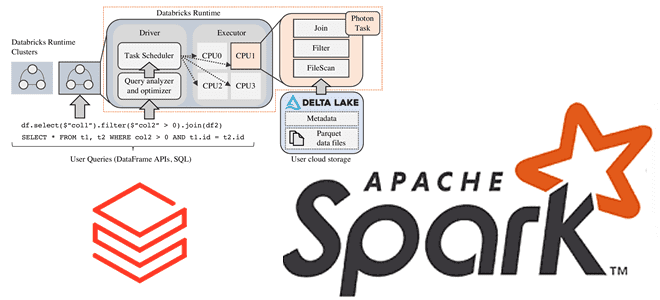
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...
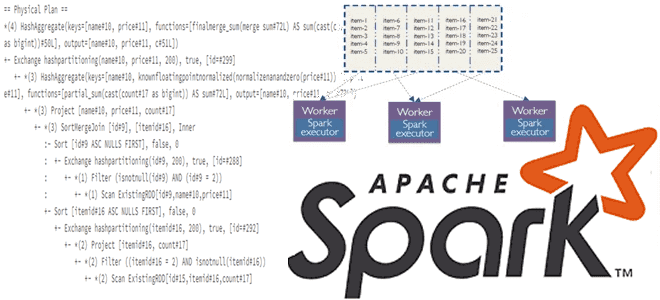
Что такое Dynamic Partition Pruning в Spark SQL, как работает этот метод оптимизации пакетных запросов, зачем его использовать в задачах аналитики больших данных, и каким образом повысить эффективность его практического применения. Что такое Dynamic Partition Pruning и зачем это нужно в Spark SQL Параллельная обработка данных в Apache Spark обеспечивается...

Как устроен потоковый запрос Spark Structured Streaming на уровне кода: интерфейсы, их методы и как их настроить, создание и запуск StreamingQuery. Создание потокового запроса в Spark Structured Streaming Хотя структурированная потоковая передача Spark основана на SQL-движке этого фреймворка, в ней гораздо больше сложных абстракций. Например, с точки зрения программирования потоковый...
Почему параллельное выполнение заданий в Apache Spark зависит от языка программирования и как можно обойти однопоточную природу Python в PySpark. Что не так с параллельным выполнением заданий PySpark и как это исправить? Apache Spark позволяет писать распределенные приложения благодаря инструментам для распределения ресурсов между вычислительными процессами. В режиме кластера каждое...

Как размер пакета, режим вывода и интервал срабатывания триггера потоковой обработки влияют на скорость вычислений в приложении Apache Spark Structured Streaming и как настроить эти параметры. Размер пакета при потоковой обработке данных в Spark Streaming Хотя скорость обработки данных средствами Apache Spark Streaming зависит от многих факторов, включая саму структуру...
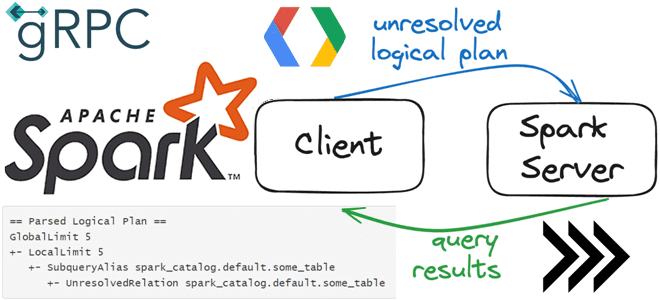
Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения. Как работает Spark Connect О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться...

3 июня 2024 года вышел предварительный релиз Apache Spark 4.0. Эта версия еще не считается стабильной и предназначена только для ознакомления. Поэтому даже полноценные release notes по ней пока отсутствуют. Тем не менее, сегодня познакомимся с наиболее интересными фичами этого выпуска: новый тип данных VARIANT, API источника данных Python и...

Для чего смотреть планы выполнения запросов при работе с API pandas в Spark и как это сделать: примеры использования метода spark.explain() и его аргументов для вывода логических и физических планов. Разбираем на примере PySpark-скрипта. API pandas и физический план выполнения запроса в Apache Spark Мы уже писали, что PySpark, API-интерфейс...
Проблемы управления данными в мультиарендной среде или как Databricks решил изолировать клиентские приложения Apache Spark на общей виртуальной машине Java друг от друга и от самого фреймворка (драйвера и исполнителей). Знакомство с Lakeguard на базе каталога Unity. Проблемы управления данными в мультитенантной среде Компания Databricks не просто развивает и продвигает...
Какие источники исходных данных поддерживает Apache Spark для пакетной и потоковой обработки, обеспечивая отказоустойчивые вычисления в большом масштабе средствами SQL и Structured Streaming. Источники данных Apache Spark SQL и структурированной потоковой передачи Будучи фреймворком для создания распределенных приложений обработки больших объемов данных, Apache Spark может подключаться к разным источникам этих...

Что такое assert, зачем это нужно в тестировании и отладке, как эта конструкция применяется для сравнения датафреймов в PySpark: примеры работы функций assertDataFrameEqual() и assertSchemaEqual() в Apache Spark. Что такое assert: конструкция тестирования При разработке PySpark-приложения дата-инженер чаще всего оперирует такими структурами данных, как датафрейм. Датафрейм (DataFrame) – это распределенная...
Где stateful-операторы хранят состояния, почему RocksDB лучше HDFSBackedStateStore и как Databricks адаптировал key-value хранилище к особенностям Spark Structured Streaming, чтобы сделать потоковую обработку больших данных еще быстрее. Где stateful-операторы Spark Structured Streaming хранят состояния? Хотя Apache Spark Structured Streaming реализует потоковую парадигму обработки информации, он по-прежнему использует микропакеты, т.е. ограниченные...