
Введение. Цена молчания. Почему изолированные данные убивают ваш бизнес Мы с Вами сегодня поговорим об интеграции данных. Представьте себе человеческий организм. Мозг (руководство) принимает решения, руки (отдел продаж) выполняют задачи, голос (маркетинг) общается с миром, а ноги (логистика) обеспечивают движение. Все это работает слаженно благодаря центральной нервной системе, которая мгновенно...

Данные — не только актив, но и токсичный актив Почему защита и безопасность данных важна? В мире бизнеса принято говорить, что данные — это новый ценный актив, новая нефть. Это правда, но лишь наполовину. Гораздо честнее будет сказать так: данные — это как радиоактивное топливо для атомной станции. При...

Данные как океан. Где его хранить и как им управлять? Раньше, лет 15-20 назад, корпоративные данные были похожи на большое, но вполне обозримое озеро. Его можно было разместить в собственном "бассейне" — локальном дата-центре, и спокойно им управлять. Сегодня ситуация изменилась кардинально. Данные превратились в бескрайний, бушующий океан. Они...

Модель данных — язык, на котором бизнес говорит с технологиями Есть старая айтишная мудрость: "Написать код легко. Гораздо сложнее написать правильный код для правильной модели данных". И это абсолютная правда. Любую ошибку в коде можно исправить относительно безболезненно. А вот ошибка, заложенная в саму структуру данных, в модель, обходится...

Архитектура данных— невидимый фундамент вашего бизнеса Представьте, что вы решили построить небоскреб. С чего вы начнете? Вряд ли с выбора панорамных окон и покупки дорогой итальянской мебели для пентхауса. Любой здравомыслящий человек начинает с фундамента. С прочного, продуманного, железобетонного основания, способного выдержать вес сотен этажей, порывы ветра и даже...
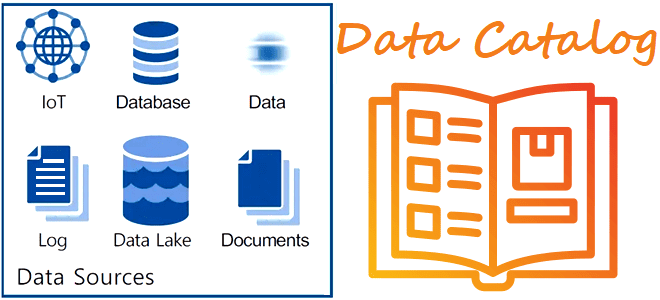
Зачем нужен каталог метаданных и как он работает: построение платформы данных и управление метаданными по DAMA DMBOK. Unity Catalog и другие решения для учета источников данных и непрерывного обеспечения их актуальности. Управление метаданными по DMBOK Методологически создание и внедрение платформ данных основано на положениях DAMA DMBOK – своде знаний по...

Что общего у StarRocks с Trino, чем они отличаются, когда и что выбирать для практического использования: сравниваем движки для быстрой аналитики больших данных из Data Lake. Чем похожи StarRocks и Trino Вчера мы разбирали, что такое StarRocks, как устроена и где пригодится эта высокопроизводительная аналитическая база данных с открытым исходным...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...
Как сократить затраты на хранение исторических данных в ClickHouse для ИИ-сценариев, сохранив высокую скорость аналитики по широким таблицам и озеру данных: эволюция колоночной СУБД в новом проекте с исходным кодом Antalya от Altinity. Проблемы совмещения ClickHouse с озерами данных и способы их решения Благодаря колоночной структуре хранения данных ClickHouse не...
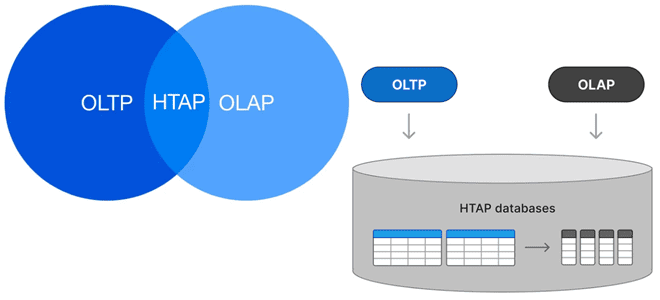
Можно ли сочетать OLAP и OLTP-нагрузки в едином хранилище и как это сделать: гибридная транзакционно-аналитическая обработка в базах данных, возможности и проблемы этой архитектуры. Что такое HTAP Исторически хранилища данных принято делить на OLAP и OLTP с учетом их оптимизации для аналитических и транзакционных нагрузок. OLTP-системы (Online Transaction Processing) оптимизированы...

Почему в одной организации возникает рассогласование данных, чем опасна такая рассинхронизация, как ее обнаружить и устранить: подходы и решения для повышения качества данных. Что такое data silos и как найти локальные «болота данных» Рассогласование в данных возникает при разной логике обработки одной и той же информации. Это мешает принимать объективные...
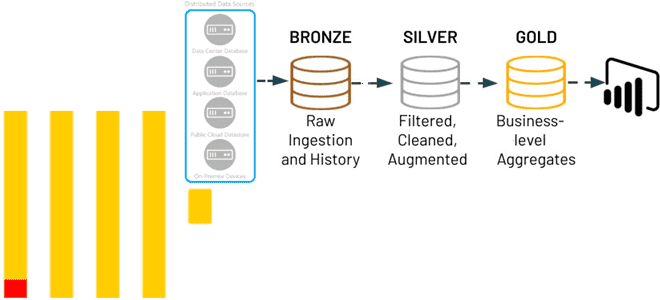
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...
Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg. Очередная попытка унификации пакетной и потоковой парадигмы Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике,...
Архитектура Data Lake: что не так с потоковыми обновлениями данных в Data Lake, как Apache Iceberg реализует эти операции и почему Upsolver решили улучшить этот формат Проблема потоковых обновлений в Data Lake и 2 подхода к ее решению Считается, что озеро данных (Data Lake) предлагают доступное и гибкое хранилище, позволяющее...
Большинство ETL-конвейеров извлекают данные из реляционных баз в пакетном или микропакетном режиме. Читайте далее, по каким шаблонам реализовать операции извлечения. Моментальные снимки: периодическая выгрузка данных из исходных таблиц Полная периодическая выгрузка данных из одной или нескольких таблиц – это, пожалуй, самый простой метод извлечения изменяемых данных. По своей сути результат полной...
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
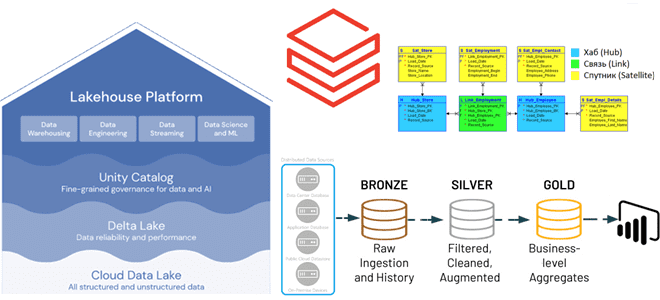
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...