
В современном мире объём данных, генерируемых в реальном времени, растёт экспоненциально. По прогнозам, к 2025 году рынок аналитики real-time данных достигнет $38.6 миллиардов, что подчёркивает критическую важность их мгновенной обработки. В таких условиях традиционные batch-системы уступают место фреймворкам потоковой обработки, среди которых Apache Flink занимает лидирующие позиции благодаря своей производительности,...

Как Flink SQL позволяет обогащать потоковые данные информацией из внешних систем и статических таблиц, зачем в релизе 2.0 улучшили Lookup Join и каким образом работает эта оптимизация. Как работает потоковое обогащение в Apache Flink Для взаимодействия с внешними системами (источниками и приемниками данных) Apache Flink использует коннекторы. Source-коннекторы обеспечивают чтение...
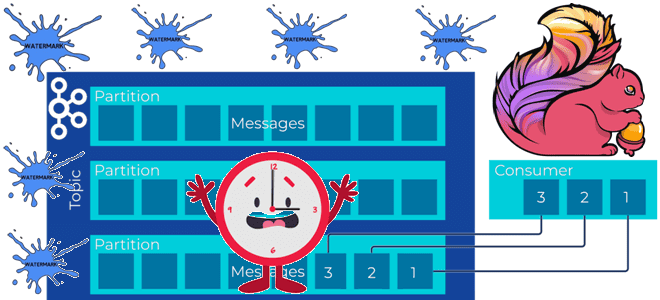
Почему задание Flink не обрабатывает потоковые данные из топика Kafka и при чем здесь водяные знаки: причины потери данных или растущей задержки вычислений и способы их решения. Почему задание Flink не обрабатывает потоковые данные и при чем здесь водяные знаки? Рассмотрим простой потоковый конвейер на Apache Flink и Kafka: задание...

Как библиотека PemJa реализует потоковый режим выполнения Flink-заданий, где UDF-функции Python выполняются в JVM, ускоряя обработку данных за счет исключения межпроцессного взаимодействия. Выполнение PyFlink-приложения в JVM Хотя Flink-приложение работает в JVM-среде, фреймворк позволяет писать код не только на Java и Scala. О том, как работает PyFlink, Python-интерфейс для Apache Flink,...
Почему можно программировать на Python для разработки JVM-приложений: как Java-фреймворки с Python API, такие как Apache Spark и Flink, транслируют Python-код, организуя межпроцессное взаимодействие. Способы трансляции Python-кода для исполнения в JVM Большинство фреймворков для разработки высоконагруженных приложений написаны на Java. Например, Apache Spark или Flink. При этом они предоставляют Python...
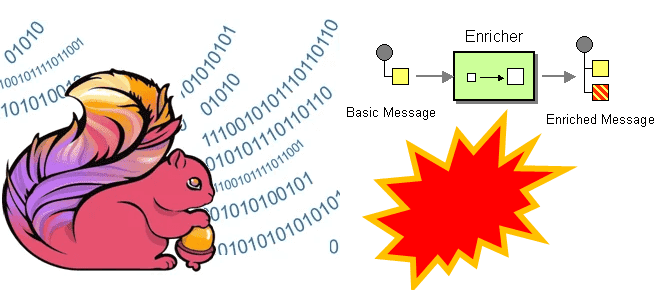
Как FLIP-304 помогает понять причину сбоя и повысить надежность Flink-приложения: обогащение типовых сообщений об ошибках пользовательскими метаданными. Зачем нужен FLIP-304 и как это позволяет дополнять сообщения об ошибках при сбоях заданий Apache Flink Хотя Apache Flink имеет встроенные механизмы обеспечения отказоустойчивости, такие как контрольные точки и точки сохранения, а также...
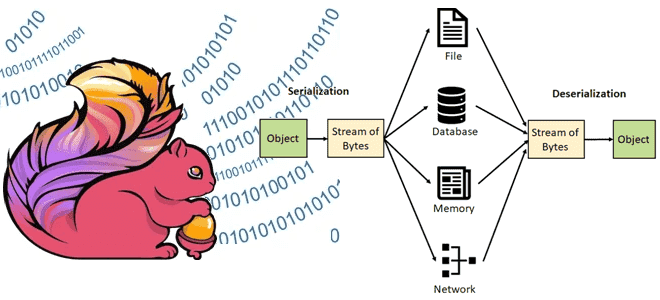
Какие типы данных поддерживает Apache Flink, как сериализация влияет на скорость обработки, зачем выбирать специализированные типы данных вместо общих структур и возможно ли изменение схемы данных без перезапуска приложения. Типы данных в Apache Flink В Apache Flink сериализация играет ключевую роль в процессе обработки данных, обеспечивая преобразование объектов в байтовый...

Чем Apache Beam отличается от Apache Flink, что и когда выбирать, зачем их совмещать для реализации сложных конвейеров обработки больших объемов данных с помощью распределенных stateful-приложений, и как это работает. Сходства и отличия Apache Beam и Flink Хотя Apache Beam является унифицированной моделью определения пакетных и потоковых конвейеров параллельной обработки данных,...
Почему репортеры мониторинга системных метрик Flink, отправляющие данные в Prometheus, не решают проблемы предварительной обработки измерений с IoT-устройств, и как новый коннектор расширяет сферу применения фреймворка потоковой обработки. Встроенные средства мониторинга системных метрик Flink В декабре 2024 года вышел новый коннектор Apache Flink к Prometheus – популярной базе данных временных...
Как описать ETL-конвейер захвата, преобразования и передачи изменения данных в YAML-файле: пример конфигурации Flink CDC из PostgreSQL в Elasticsearch. ETL-конвейер Flink CDC в YAML-файле Apache Flink позволяет строить надежные конвейеры обработки данных, используя не только с внутренние API, но и с помощью дополнительных компонентов. Одним из таких компонентов является Flink...
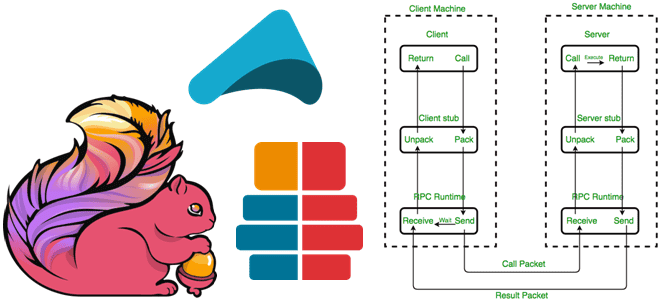
Зачем и как Apache Flink использует удаленный вызов процедур, с помощью каких технологий реализуется это RPC-взаимодействие и почему в 2023 году Akka заменен на Pekko. Удаленный вызов процедур в Apache Flink Мы уже рассказывали, как RPC-вызовы используются для коммуникации между компонентами Spark. Удаленный вызов процедур используется и в Apache Flink,...
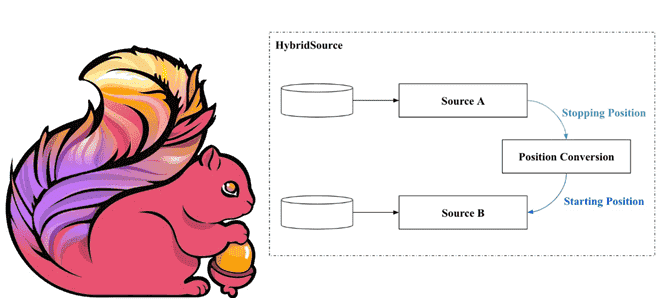
Как задание Apache Flink может читать информацию из разных источников данных в одном потоке. Что такое HybridSource и как с ним работать: разбираем на примере файла и топика Kafka. Что такое гибридный источник данных Иногда заданию Flink необходимо считывать данные из нескольких источников в последовательном порядке. Напомним, источником данных для...

23 октября 2024 года опубликован предварительный выпуск Apache Flink. Знакомимся с самыми яркими новинками этого мажорного релиза: удаленные API, коннекторы и конфигурации, динамическая оптимизация логических планов, а также дизагрегированное состояние и управление им. Критические изменения: удаление устаревших компонентов Начнем с критических изменений, связанных с удалением устаревших компонентов. В Apache Flink...
Чтобы сделать конвейеры обработки данных еще более эффективными, устраняя промежуточные хранилища для потоковых вычислений и сократить количество ETL-инструментов, немецкая компания Ververica разработала Fluss – потоковое хранилище для Apache Flink. Читайте далее, что это и чем полезно в непрерывной обработке потоков Big Data. Что не так с архитектурой конвейеров обработки данных...
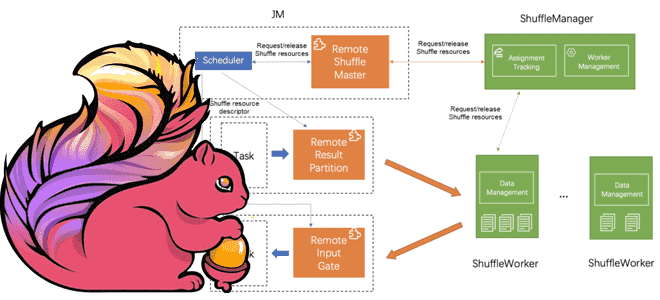
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных. Что такое Remote Shuffle Service в Apache Flink Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако,...

Зачем в Apache Flink 1.20 добавлена новая функция восстановления пакетных заданий после сбоя JobMaster, как она работает и какие параметры надо настроить для повышения ее эффективности. Восстановление пакетных заданий Flink после сбоя JobMaster Как и любой фреймворк стека Big Data, Apache Flink включает множество компонентов, каждый из которых выполняет конкретную...
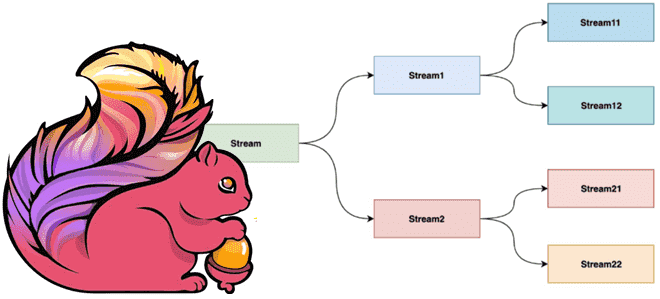
Что такое дополнительный выходной поток DataStream в Apache Flink, зачем это нужно, чем механизм SideOutput лучше операторов filter и split, а также как его использовать: примеры на Python. Что такое дополнительный выходной поток DataStream в Apache Flink и зачем это нужно Хотя выходные результаты большинства операторов API DataStream в Apache...
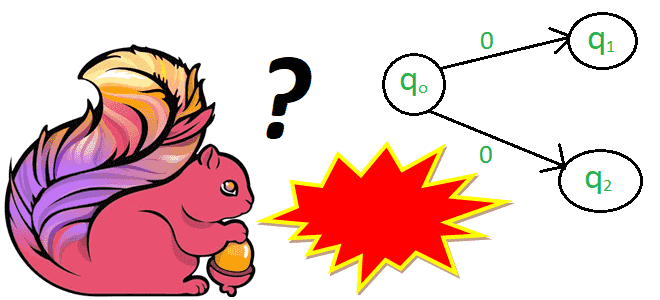
Что такое проблема недетерминированного поведения, почему она так важна в потоковой обработке данных и как Apache Flink борется с ней: недетерминированные и динамические функции, а также changelog stateful-операторов. Недетерминированные функции в Apache Flink В потоковой обработке данных, на которую ориентирован Apache Flink, все завязано на отметку времени события (timestamp). Однако,...
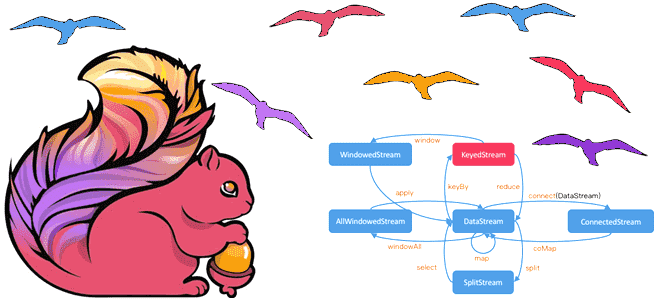
Чем DataSet API отличается от DataStream, зачем переходить с наборов на потоки данных в Apache Flink и как это сделать: эквивалентные и неподдерживаемые методы преобразования данных. Разница между DataStream и DataSet API Исторически в Apache Flink было 3 высокоуровневых API: DataStream/DataSet, Table и SQL. О возможностях и ограничениях каждого из...

2 августа 2024 года вышел свежий релиз Apache Flink. Знакомимся с главными новинками выпуска 1.20 для упрощения потоковой обработки данных в мощных управляемых конвейерах: новые материализованные таблицы, единый механизм слияния файлов для контрольных точек, улучшения DataStream API и пакетных операций. Улучшения Flink SQL Начнем с новинок Flink SQL, одной из...