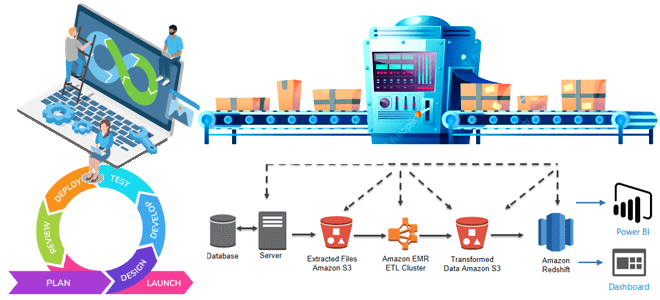
Чем инженерия данных отличается от разработки ПО, как организовать оркестрацию конвейеров обработки данных и внедрить лучшие практики CI/CD. Почему дата-инженерия отличается от разработки ПО При том, что между инженерией данных и разработкой программного обеспечения (ПО) очень много общего, эти ИТ-дисциплины довольно сильно отличаются. Хотя в обоих направлениях используется облачная инфраструктура,...

С учетом тренда на контейнеризацию при разработке и развертывании любых технологий, в т.ч. Big Data, сегодня рассмотрим плюсы и минусы совместного использования Apache Spark с Kubernetes. Читайте далее, как отправить Спарк-задание в кластер Кубернетес и почему это сэкономит затраты на вашу инфраструктуру аналитики больших данных, не повысив производительность отдельных приложений,...
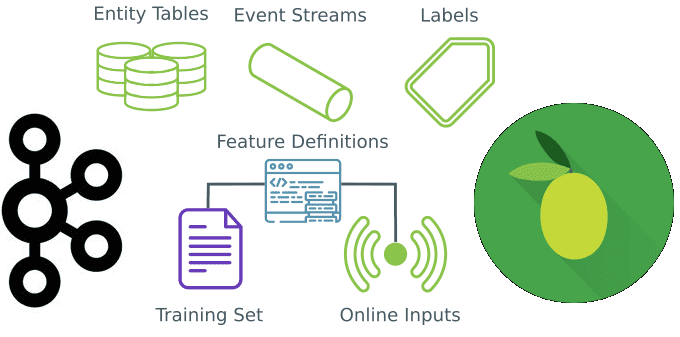
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

Чтобы сделать наши курсы по Apache Kafka для разработчиков Big Data систем еще более интересными, а обучение – запоминающимся, сегодня мы рассмотрим еще несколько примеров реализации микросервисной архитектуры на этой стриминговой платформе. А также поговорим про проблемы удаления данных в этой архитектурной модели, разобрав кейс компании Twitter по построению корпоративного...
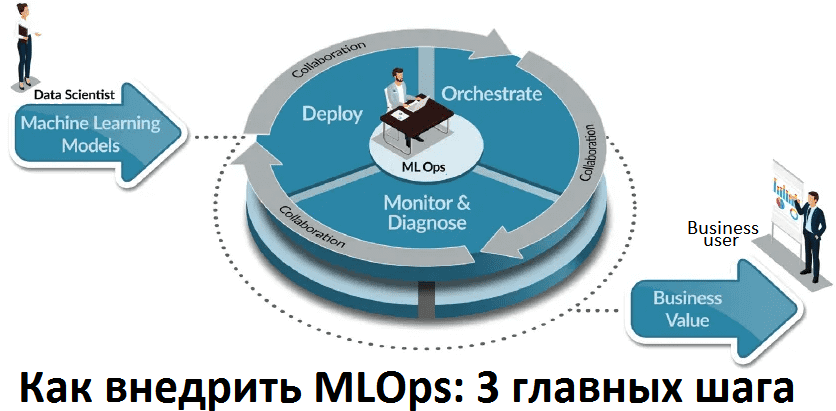
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...
Цифровизация и запуск проектов Big Data предполагают некоторый уровень управленческой зрелости бизнеса, который обычно оценивается по модели CMMI. MLOps также требует предварительной готовности предприятия к базовым ценностям этой концепции. Читайте в нашей статье, что такое Machine Learning Operations Maturity Model – модель зрелости операций разработки и эксплуатации машинного обучения, из...
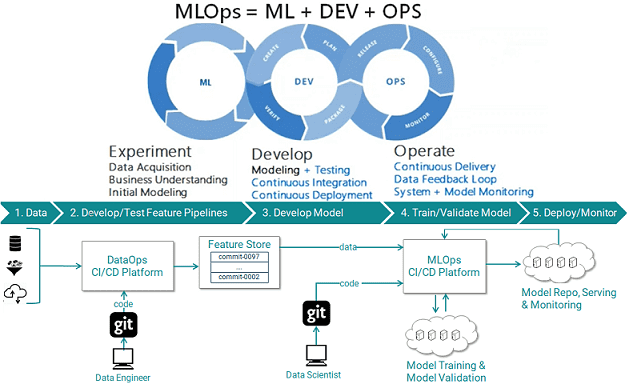
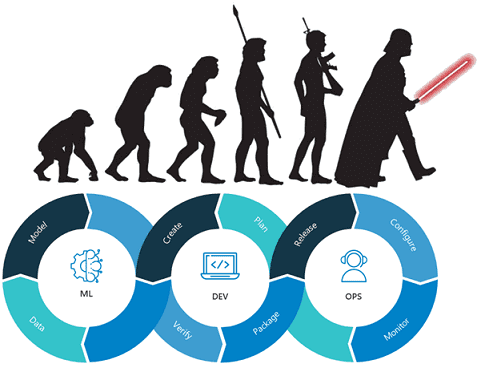
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...

Вчера мы говорили про наиболее перспективные технологии 2020 с точки зрения исследовательского агентства Gartner и их влияние на цифровую трансформацию. Сегодня продолжим разбирать современные тенденции изменения рабочего пространства с учетом эпидемиологической напряженности и тренда на дистанционное взаимодействие. Читайте далее, что такое Desktop as a Service, как выглядит интеллектуальное рабочее пространство,...

Постоянно обновляя наши курсы «Аналитика больших данных для руководителей» в соответствии с развитием области Big Data и вызовов современного бизнеса, сегодня мы расскажем про наиболее перспективные технологии с точки зрения исследовательского агентства Gartner, а также рассмотрим их влияние на цифровую трансформацию. Читайте в нашей статье, почему цифровой двойник нужен не...

Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...

В этой статье поговорим про интеграцию информационных систем: обсудим SOA и ESB-подходы, рассмотрим стриминговую архитектуру и возможности Apache Kafka для организации быстрого и эффективного обмена данными между различными бизнес-приложениями. Также обсудим, что влияет на архитектуру интеграции корпоративных систем и распределенных Big Data приложений, что такое спагетти-структура и почему много сервисов...

В продолжение темы про проявление Agile-принципов в Big Data системах, сегодня мы рассмотрим, как DevOps-подход отражается в использовании Apache Kafka. Читайте в нашей статье про кластерную архитектуру коннекторов Кафка и KSQL – SQL-движка на основе API клиентской библиотеки Kafka Streams для аналитики больших данных, о которой мы рассказывали здесь. Из...

Мы уже рассказывали, как некоторые принципы Agile отражаются в Big Data системах. Сегодня рассмотрим это подробнее на примере коннекторов Кафка и KSQL – SQL-движка для Apache Kafka. Он который базируется на API клиентской библиотеки для разработки распределенных приложений с потоковыми данными Kafka Streams и позволяет обрабатывать данные в режиме реального...

В контексте темы бережливого производства в ИТ, сегодня мы расскажем про анализ требований к разработке ПО в условиях Agile-подходов к организации работы и соответствия жестким рамкам отечественных ГОСТов и зарубежных стандартов. Читайте в нашей статье, что говорит BABOK по этому поводу и когда нужно запускать процесс создания программной документации, чтобы...

Ранее мы рассказывали, что общего между бережливым производством и DevOps. Сегодня рассмотрим, как 7 принципов Lean отражены в разработке программного обеспечения. Также читайте в нашей статье об актуальности методологии ITIL для проектов цифровизации и внедрения технологий больших данных (Big Data). 7 принципов Lean в ИТ Мы уже упоминали, что впервые...
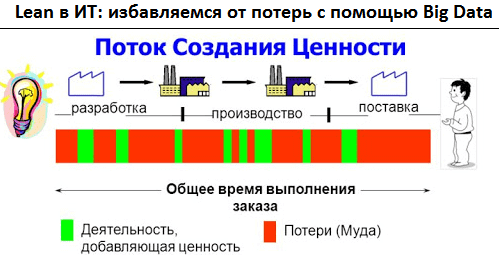
Продолжая разговор про бережливое производство в ИТ, сегодня мы рассмотрим виды потерь и источники их возникновения, а также поговорим, как принципы Lean помогают бизнесу избавиться от муда, мури и мура средствами больших данных (Big Data). 8 видов потерь в Lean с примерами из ИТ Прежде всего, поясним значение понятий муда,...
Чтобы сделать курс Аналитика больших данных для руководителей еще более интересным, мы продолжаем включать в него темы про методы производственной оптимизации. Сегодня рассмотрим, что такое бережливое производство (Lean) и почему Agile вообще и DevOps в частности активно используют принципы этой концепции. Также читайте в нашей статье, чем Lean отличается от системы...

В результате цифровой трансформации «традиционного предприятия» должна получиться идеальная организация, работающая на основе данных, в т.ч. больших (Big Data). Сегодня мы поговорим, что такое Data-Driven Company, чем она отличается и как ей стать: читайте в нашей статье, какие инструменты Big Data, методы Agile и инженерные подходы системного анализа применяются для...