
Business Intelligence — это не отчеты. Это компас для вашего бизнеса Представьте себя капитаном большого корабля в открытом море во время шторма. Как вы будете прокладывать курс? Полагаясь на интуицию и старые карты, нарисованные от руки? Возможно, вам повезет. Но скорее всего, вы налетите на рифы или заблудитесь. А теперь...

Модель данных — язык, на котором бизнес говорит с технологиями Есть старая айтишная мудрость: "Написать код легко. Гораздо сложнее написать правильный код для правильной модели данных". И это абсолютная правда. Любую ошибку в коде можно исправить относительно безболезненно. А вот ошибка, заложенная в саму структуру данных, в модель, обходится...
Зачем нужен каталог метаданных и как он работает: построение платформы данных и управление метаданными по DAMA DMBOK. Unity Catalog и другие решения для учета источников данных и непрерывного обеспечения их актуальности. Управление метаданными по DMBOK Методологически создание и внедрение платформ данных основано на положениях DAMA DMBOK – своде знаний по...

Что общего у StarRocks с Trino, чем они отличаются, когда и что выбирать для практического использования: сравниваем движки для быстрой аналитики больших данных из Data Lake. Чем похожи StarRocks и Trino Вчера мы разбирали, что такое StarRocks, как устроена и где пригодится эта высокопроизводительная аналитическая база данных с открытым исходным...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...
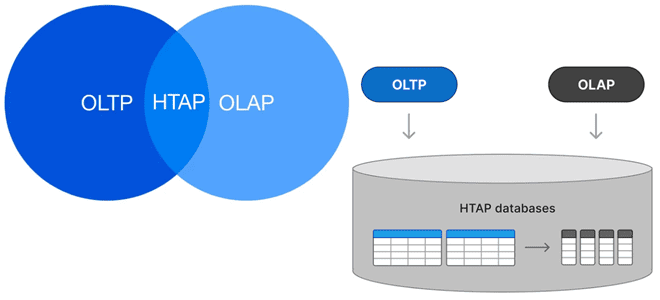
Можно ли сочетать OLAP и OLTP-нагрузки в едином хранилище и как это сделать: гибридная транзакционно-аналитическая обработка в базах данных, возможности и проблемы этой архитектуры. Что такое HTAP Исторически хранилища данных принято делить на OLAP и OLTP с учетом их оптимизации для аналитических и транзакционных нагрузок. OLTP-системы (Online Transaction Processing) оптимизированы...

Почему в одной организации возникает рассогласование данных, чем опасна такая рассинхронизация, как ее обнаружить и устранить: подходы и решения для повышения качества данных. Что такое data silos и как найти локальные «болота данных» Рассогласование в данных возникает при разной логике обработки одной и той же информации. Это мешает принимать объективные...

Что такое Apache Doris, как его использовать для построения хранилища данных и чем это отличается от ClickHouse. Сценарии применения и критерии выбора основы DWH. Что такое Apache Doris Недавно мы рассматривали, почему ClickHouse подходит для реализации хранилища данных на основе эталонной архитектуры Medallion благодаря поддержке более 70 форматов файлов, материализованным...
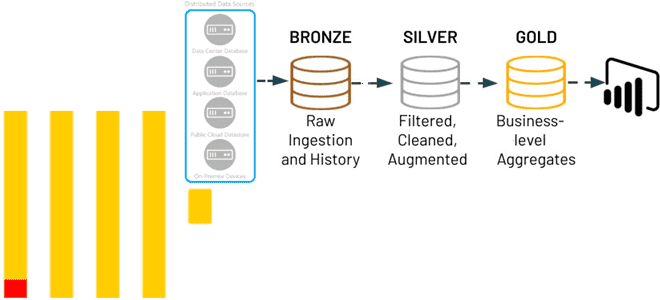
Почему ClickHouse подходит для архитектуры данных Medallion и как реализовать это слоистое хранилище средствами колоночной СУБД без сторонних инструментов: лучшие практики и примеры использования. 3 слоя архитектуры данных Medallion Слоистая архитектура, предложенная компанией Databricks, сегодня считается классикой для построения озер и хранилищ данных. Она предполагает реализацию 3-х уровней (слоев): Бронза,...

Что общего между Trino и dbt, чем они отличаются и в каких случаях выбирать тот или иной инструмент для инженерии и анализа данных. Краткий ликбез для начинающего дата-инженера и аналитика. Сходства и отличия Trino и dbt Trino и dbt (Data Build Tool) — это два популярных инструмента с открытым исходным...
Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg. Очередная попытка унификации пакетной и потоковой парадигмы Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике,...
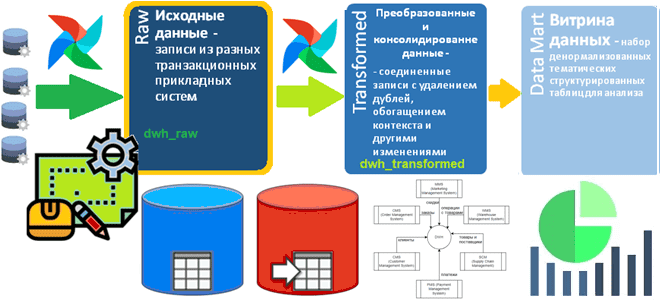
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...
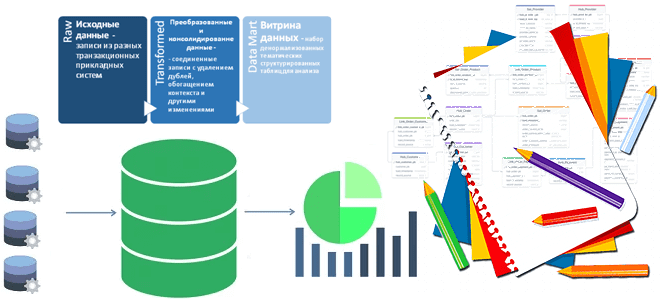
Как построить хранилище данных с подходом Data Vault: пример проектирования схемы данных и разработка DDL-скрипта для Transformed-слоя DWH интернет-магазина. Слоистая структура DWH и подход Data Vault Корпоративное хранилище данных (DWH, Data Warehouse) часто бывает гетерогенным, т.к. организованным с помощью нескольких баз данных, связанных ETL-процессами. Согласно концепции слоистой архитектуры (LSA, Layered...

Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Что такое гонка данных в дата-инженерии Одна из главных особенностей распределенных систем – это задержка между...
Большинство ETL-конвейеров извлекают данные из реляционных баз в пакетном или микропакетном режиме. Читайте далее, по каким шаблонам реализовать операции извлечения. Моментальные снимки: периодическая выгрузка данных из исходных таблиц Полная периодическая выгрузка данных из одной или нескольких таблиц – это, пожалуй, самый простой метод извлечения изменяемых данных. По своей сути результат полной...
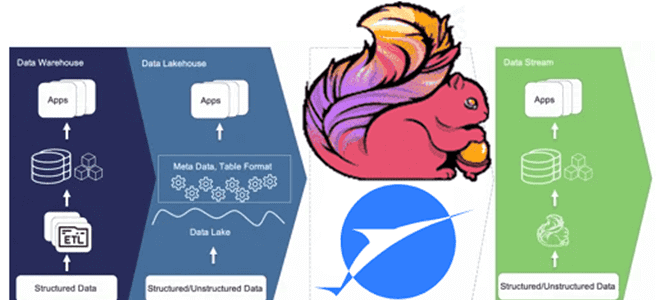
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
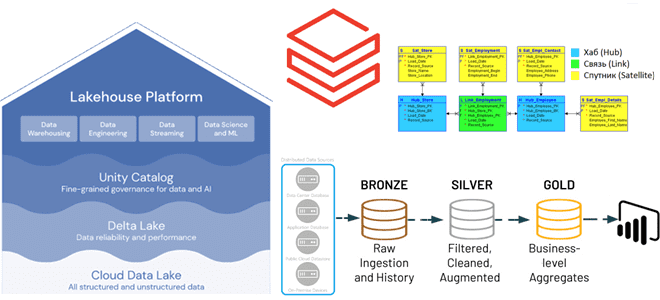
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
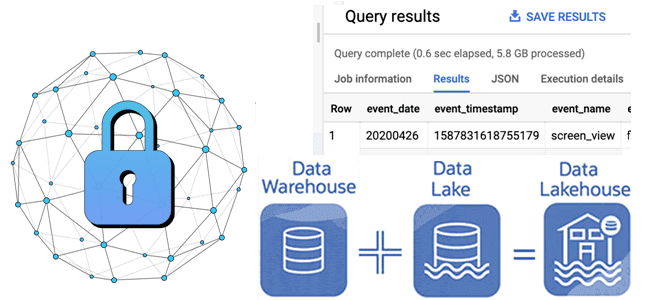
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...

Как выбирать политики распределения и разделения данных в Greenplum, в чем польза динамического сканирования индексов, зачем регулярно использовать операции VACUUM и ANALYZE, из-за чего тормозят SQL-запросы и как это исправить. Эффективное распределение и разделение Будучи основанной на PostgreSQL, Greenplum расширяет возможности этой замечательной СУБД, добавляя операции с массово-параллельной обработкой. Для...