
Business Intelligence — это не отчеты. Это компас для вашего бизнеса Представьте себя капитаном большого корабля в открытом море во время шторма. Как вы будете прокладывать курс? Полагаясь на интуицию и старые карты, нарисованные от руки? Возможно, вам повезет. Но скорее всего, вы налетите на рифы или заблудитесь. А теперь...

За пределами таблиц. Темная сторона корпоративных данных Представьте себе айсберг. Мы видим его верхушку, сияющую на солнце — она понятна, измерима и предсказуема. Это наши структурированные данные в базах и хранилищах. Но мы знаем, что 90% массы айсберга скрыто под водой. Точно так же и в мире корпоративной...

Данные — не только актив, но и токсичный актив Почему защита и безопасность данных важна? В мире бизнеса принято говорить, что данные — это новый ценный актив, новая нефть. Это правда, но лишь наполовину. Гораздо честнее будет сказать так: данные — это как радиоактивное топливо для атомной станции. При...

Поздравляем! Если вы читаете эти строки, значит, вы прошли полный путь от первого изучения ClickHouse до понимания его самых глубоких механизмов. За эти десять статей мы превратились из новичков, задающихся вопросом "Что такое колоночная СУБД?", в уверенных пользователей, способных не только писать сложные аналитические запросы, но и проектировать, оптимизировать и...

Мы с вами научились виртуозно писать запросы, строить сложные аналитические отчеты и интегрировать ClickHouse с другими системами. Но чтобы вся эта мощь работала стабильно и предсказуемо в production, кластер требует внимания и ухода. Написание запросов — это работа аналитика или разработчика, а поддержание здоровья системы — это задача администратора баз...
Оконные функции ClickHouse и работа с массивами данных. Мы с вами уже прошли большой путь: научились эффективно хранить данные, оптимизировать таблицы, выполнять базовые и сложные запросы и даже интегрироваться с внешними системами. Казалось бы, мы можем практически всё. Но как ответить на такие вопросы: "Каково время между последовательными действиями каждого...
До сих пор мы рассматривали ClickHouse как самостоятельную систему: создавали в нем таблицы и загружали данные. Однако в реальном мире данные редко живут в одном месте. Транзакционная информация находится в реляционных базах вроде MySQL или PostgreSQL, архивы логов — в объектных хранилищах типа Amazon S3, а потоки событий в реальном...
Итак, вы освоили типы данных, создали таблицы на правильных движках MergeTreeи даже научились писать сложные запросы. Кажется, что вы готовы к работе с реальными данными. Однако на больших объемах вы можете столкнуться с ситуацией, когда даже на мощном "железе" запрос выполняется не так быстро, как хотелось бы. В чем же...
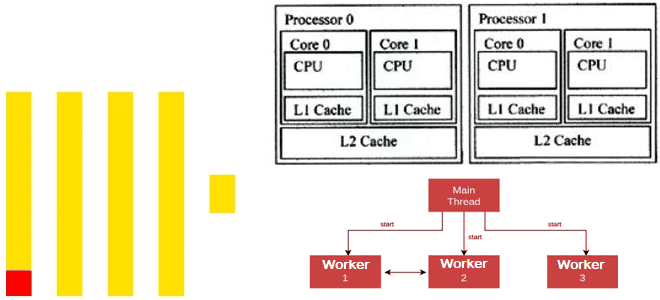
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД. Особенности многопоточной обработки в Clickhouse Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача....
Зачем в ClickHouse 25.4 добавлена отложенная материализация и как ленивые вычисления позволяют ускорить работу аналитической СУБД благодаря сокращению объемов читаемых данных и снижению количества операций дискового ввода-вывода. Еще раз о пользе ленивых вычислений Отложенные или ленивые вычисления (lazy evaluation), которые выполняются не сразу, а откладываются до момента, когда их результат...
Как устроена оптимизация PREWHERE для сокращения объема сканируемых данных в ClickHouse: разбираемся с деталями реализации и смотрим планы выполнения SQL-запросов. Как устроена оптимизация PREWHERE в ClickHouse Недавно мы писали, как оптимизация PREWHERE позволяет сократить объем сканируемых данных и повысить скорость выполнения SQL-запроса в ClickHouse. Сегодня рассмотрим техническую реализацию этого оператора...
Как ускорить выполнение SQL-запроса в ClickHouse, сократив объем сканируемых данных с помощью оператора PREWHERE: практический пример простой, но эффективной оптимизации. Как работает оператор PREWHERE в ClickHouse ClickHouse имеет ряд многоуровневых оптимизаций, благодаря которым позволяет анализировать огромные объемы данных почти в реальном времени. Одной из таких оптимизаций является PREWHERE, которая сокращает...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...
Как сократить затраты на хранение исторических данных в ClickHouse для ИИ-сценариев, сохранив высокую скорость аналитики по широким таблицам и озеру данных: эволюция колоночной СУБД в новом проекте с исходным кодом Antalya от Altinity. Проблемы совмещения ClickHouse с озерами данных и способы их решения Благодаря колоночной структуре хранения данных ClickHouse не...
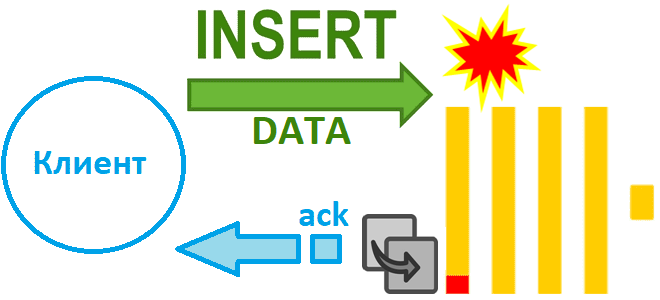
Как избежать потери данных при асинхронной вставке в Clickhouse при сбое сервера и зачем в версию 24.2 добавлен адаптивный тайм-аут очистки буфера: тонкости ETL с колоночной СУБД. Асинхронная вставка с возвратом подтверждения Недавно мы рассказали, чем хороши асинхронные вставки в ClickHouse и отметили, что при их использовании можно настроить параметр...
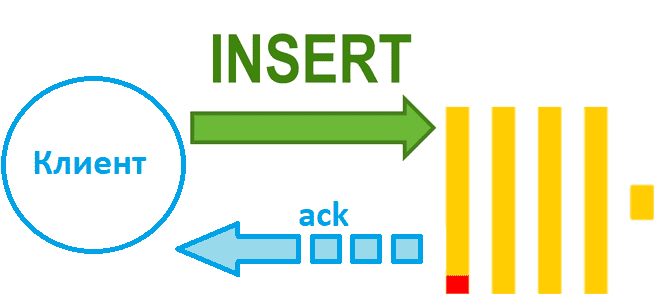
Чем синхронная вставка в ClickHouse отличается от асинхронной и как это настроить: лучшие практики и риски загрузки данных в колоночное хранилище. Синхронная вставка данных в ClickHouse Хотя скорость вставки данных в ClickHouse зависит от множества факторов, ее можно ускорить за счет асинхронных вставок, если предварительное пакетирование на стороне клиента невозможно....

Почему не рекомендуется публиковать в Kafka сообщения больших размеров, и как это сделать, если очень нужно: когда приходится перенастраивать конфигурации продюсера, топика и потребителя, и какие это параметры. Почему не нужно публиковать в Kafka сообщения больших размеров Apache Kafka, как и другие брокеры сообщений, оптимизирована для передачи данных небольшого размера....
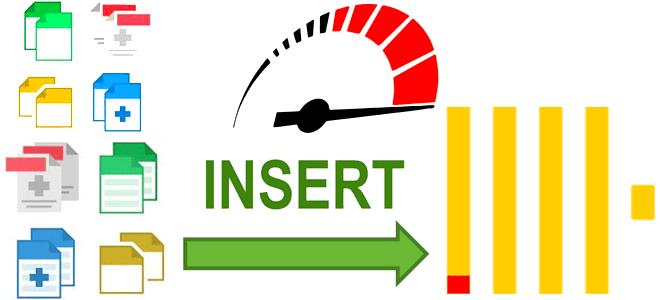
Как именно формат, сортировка, сжатие и интерфейс передачи данных в ClickHouse влияют на скорость операций загрузки: бенчмаркинговое сравнение от разработчиков колоночной СУБД. В каком формате данные быстрее всего вставляются в ClickHouse Продолжая недавний разговор про вставку данных в ClickHouse, сегодня рассмотрим, ключевые факторы, которые особенно сильно влияют на скорость загрузки...

Как выполняется вставка данных в ClickHouse, от чего зависит ее скорость и каким образом ее повысить: последовательность операций загрузки и ее оптимизации. От чего зависит скорость вставки данных в ClickHouse Поскольку ClickHouse часто используется для построения хранилищ или витрин данных, скорость загрузки данных в эту базу очень важна. Хотя на...
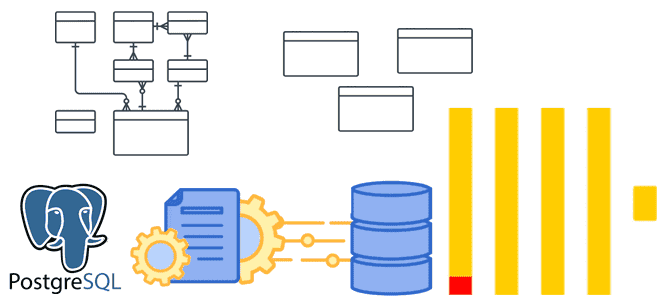
Денормализация таблиц, оптимизация SQL-запросов, словари вместо измерений и AggregatingMergeTree-движок с инкрементными матпредставлениями для приема измененных данных из PostgreSQL в ClickHouse. Оптимизация SQL-запросов Хотя передача изменений из PostgreSQL в ClickHouse может сопровождаться дублированием или потерями данных, эти проблемы решаемы, о чем мы рассказывали здесь и здесь. Однако, репликация данных из реляционной...