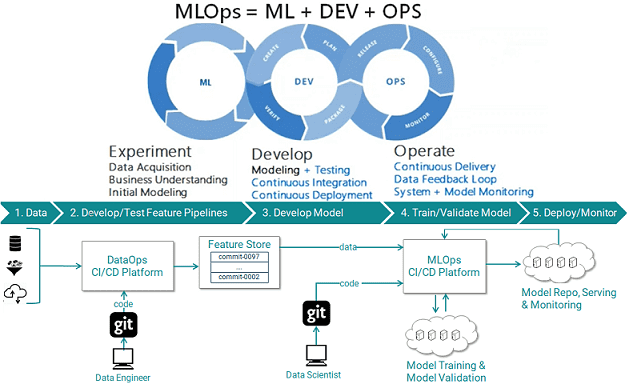
Пока цифровизация воплощает в жизнь концепцию DataOps, мир Big Data вводит новую парадигму – MLOps. Читайте в нашей статье, что такое MLOps, зачем это нужно бизнесу и какие специалисты потребуются при внедрении практик и инструментов сопровождения всех операций жизненного цикла моделей машинного обучения (Machine Learning Operations). Что такое MLOps, почему...
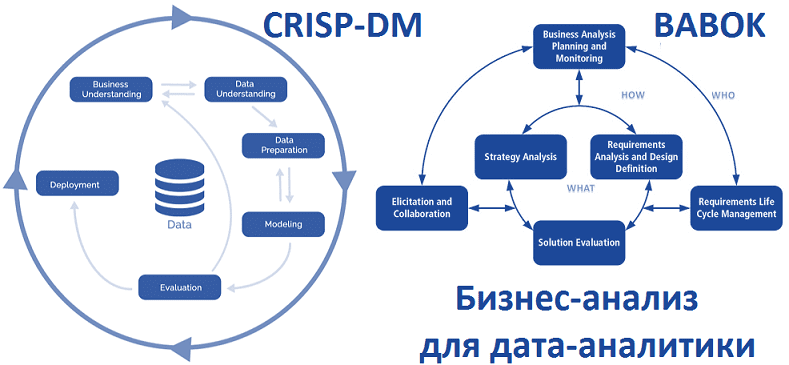
Мы уже рассказывали, что цифровизация и другие масштабные проекты внедрения технологий Big Data должны обязательно сопровождаться процедурами бизнес-анализа, начиная от выявления требований на старте до оценки эффективности уже эксплуатируемого решения. Сегодня рассмотрим, как задачи бизнес-анализа из руководства BABOK®Guide коррелируют с этапами методологии исследования данных CRISP-DM, которая считается стандартом де-факто в...

В этой статье мы рассмотрим несколько популярных мифов о Data Science и аналитике больших данных (Big Data), разобрав, когда и почему простое использование BI-систем или облачных DaaS-платформ бывает гораздо эффективнее попыток внедрения алгоритмов машинного обучения (Machine Learning) и прочих методов Data Science в операционные и стратегические бизнес-процессы. Почему 80% Data...
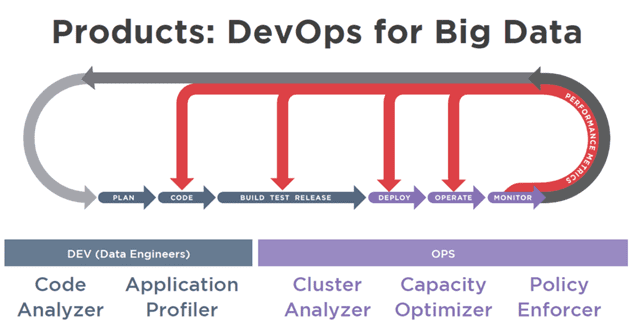
С точки зрения бизнеса DevOps (DEVelopment OPerations, девопс) можно рассматривать как углубление культуры Agile для управления процессами разработки и поставки программного обеспечения с помощью методов продуктивного командного взаимодействия и современных средств автоматизации. Сегодня мы поговорим о том, как эта методология используется в Big Data проектах, почему любой Data Scientist становится немного...

Генерация признаков – пожалуй, самый творческий этап подготовки данных (Data Preparation) для машинного обучения (Machine Learning). Этот этап еще называют Feature Engineering. Он наступает после того, как выборка сформирована и очистка данных завершена. В этой статье мы поговорим о том, что такое признаки, какими они бывают и как Data Scientist...

Выборка, полученная в результате первого этапа подготовки данных (Data Preparation), еще пока не пригодна для обработки алгоритмами машинного обучения, поскольку информацию необходимо очистить. Сегодня мы расскажем, что такое очистка данных (Data Cleaning) для Data Mining, зачем она нужна и как выполнять этот этап Data Preparation. Что такое очистка данных для...
Мы уже рассказывали о важности этапа подготовки данных (Data Preparation), результатом которого является обработанный набор очищенных данных, пригодных для обработки алгоритмами машинного обучения (Machine Learning). Такая выборка, называемая датасет (dataset), нужна для тренировки модели Machine Learning, чтобы обучить систему и затем использовать ее для решения реальных задач. Однако, поскольку в...

CRISP-DM, SEMMA и другие стандарты Data Mining не случайно выделяют подготовку данных в отдельную фазу. Data Preparation - весьма трудоемкий итеративный процесс, который занимает до 80% всех затрат ресурсов и времени в жизненном цикле Data Mining и включает следующие задачи обработки исходных («сырых») данных [1]: Выборка данных – отбор признаков...

Как быстро и эффективно внедрить Big Data и Machine Learning в прикладную область бизнеса для решения практических задач, избежав популярных ошибок Data Scientist - разбираемся на примере HR-направления. Подготовка к внедрению Big Data в HR и не только Зачем HR-специалисту большие данные и какую пользу они принесут управленческим процессам и...

Иван Гуз, директор по аналитике и клиентскому сервису Avito, 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе компании [1] рассказал о самых главных проблемах, которые подстерегают исследователя данных на практических проектах и от чего не убережет даже подробно проработанный стандарт CRISP-DM. Из его...

Посмотрев выступление Станислава Гафарова [1], руководителя направления по развитию ИТ-систем АО «СберТех», от 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе Авито [2], мы составили ТОП-7 ошибок при работе с данными по методологии CRISP-DM. На основании жизненного цикла работы с информацией по стандарту...