
Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения. Расширение стратегий развертывания в Kubernetes с Argo Rollouts Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows -...
В чем сложности оркестрации параллельных заданий в Kubernetes и как их решить с помощью Argo Workflows: обзор фреймворка и практический пример YAML-спецификации шаблона рабочего процесса для развертывания веб-приложения. Что такое Argo Workflows и зачем он нужен Оркестрация параллельных заданий на платформе Kubernetes довольно сложна из-за их внутренних зависимостей друг от...

Что общего между Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium), чем отличаются эти коннекторы и как добавить JDBC-драйвер для передачи данных из PostgreSQL в Apache Kafka на Docker. Коннекторы Kafka к реляционным БД от Confluent О том, что CDC-коннектор Debezium позволяет организовать интеграцию Apache Kafka с реляционной...
Как туннелировать порты Docker-контейнеров для доступа к Kafka на WSL в Windows с внешнего клиента: переадресация HTTP- и TCP-соединений с помощью SSH-сервера serveo. Поиск средства тунелирования и настройка портов Собственное развертывание платформы Kafka от Confluent в виде набора связанных Docker-контейнеров в WSL на Windows с GUI-интерфейсом AKHQ, о чем я...
Как настроить YAML-файл Docker Compose для доступа к Kafka на WSL в Windows: открытие портов в конфигурации развертывания с примерами (продолжение). Настройка конфигурационного YAML-файла для запуска Docker-контейнеров с компонентами Kafka на Windows в WSL Как я рассказывала вчера, для работы с компонентами платформы Kafka от Confluent, развернутой как набор связанных...

WSL и Docker для локального развертывания Apache Kafka с GUI и всеми компонентами в контейнере: моя реальная история поиска веб-интерфейса и настройки портов (начало). Развертывание Kafka на Windows с Docker в WSL В конце августа 2024 года команда serverless-платформы Upstash, на которой у меня есть рабочий инстанс Apache Kafka, разослала...

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...

Как сделать запуск UDF-функций Python или R на узлах сегмента Greenplum более быстрым и безопасным с помощью Docker-контейнеров и расширения PL/Container. Что такое PL/Container и как это использовать в Greenplum Запуск пользовательского кода для базы данных всегда имеет риск нарушения информационной безопасности. Если речь идет о стеке Big Data, ущерб...

Мы уже писали о преимуществах развертывания Apache NiFi на Kubernetes, а также сложностях практической реализации этого процесса. Сегодня поговорим о контейнеризации реестра NiFi с использованием Helm-диаграмм, а также совмещения с Apache Ranger и Kerberos. 7 главных трудностей развертывания Apache NiFi на Kubernetes Apache NiFi активно используется дата-инженерами для организации потоковых...
Что не так с традиционными методами и инструментами разработки ПО для систем машинного обучения и как MLOps решает эти инженерные проблемы ML. Почему не стоит размещать файлы моделей Machine Learnig и датасеты в Git, а также зачем MLOps-инженеру решать вопросы архитектуры и управляться с Kubernetes. MLOps вместо Git-репозиториев Традиционные рабочие...

Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...
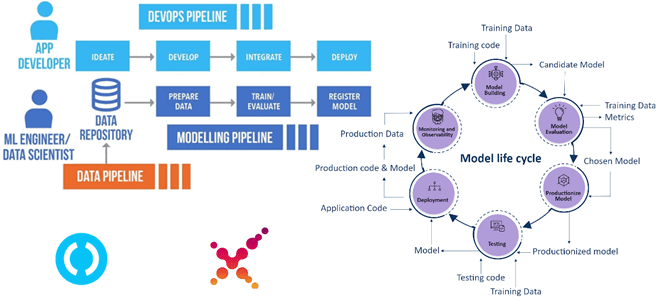
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...

Почему следует избегать PythonOperator в конвейере обработки пакетных данных на Apache Airflow и что использовать вместо этого оператора для описания задач DAG. Когда лаконичный CLI лучше наглядного GUI, где и как применять библиотеку Python Fire для оркестрации, а также планирования запуска batch-заданий. Зачем нам CLI или что не так с PythonOperator...

Запуск Apache Airflow с Kubernetes сегодня стал стандартом де-факто. Однако, при практическом развертывании Airflow с помощью исполнителя Kubernetes и оператора пода в кластере этой платформы оркестрации контейнерных приложений возникает множество препятствий и трудностей. Сегодня рассмотрим, как обойти их с помощью service-mesh проекта с открытым исходным кодом Istio, какие проблемы могут при...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...

Как организовать удобный мониторинг за приложениями Apache Spark в кластере Kubernetes с помощью Prometheus и Grafana: пошаговый guide для администраторов и дата-инженеров с примерами. Создаем свою альтернативу наглядным дэшбордам AWS EMR с Java-библиотекой Dropwizard Metrics и средством настройки оповещений Alertmanager. Не только AWS EMR или как следить за Spark-приложениями в...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...
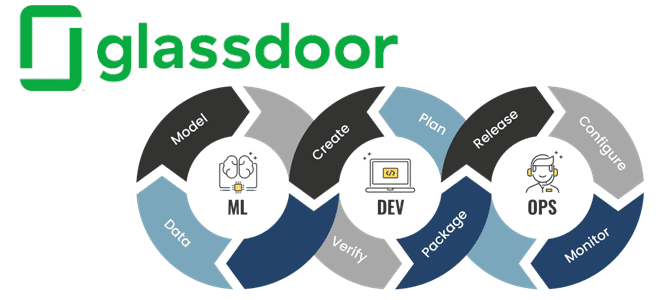
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

Сегодня поговорим про совместное использование Apache NiFi с его легковесным агентом – MiNiFi. Преимущества для ETL-процессов в IoT-системах и не только, ограничения практического применения, а также пример контейнеризации и выполнения Docker-образа на Raspberry PI4 ARM64. Internet of Things и Apache NiFi на периферии Интернет вещей (Internet of Things, IoT) приводит...
Сегодня разберемся с serverless-технологиями и рассмотрим, как самостоятельно создать и интегрировать бессерверный парсер Selenium с Apache Nifi. Краткий ликбез по OpenFaaS, Selenium и Chromium, а также преимущества serverless-технологий и пример вызова функции сбора данных с веб-страницы на Python. Введение: serverless, OpenFaaS и Selenium с Chromium Serverless-стратегия организации платформенных облачных услуг,...