
От оркестрации и синхронизации конвейеров обработки данных до управления хранилищами, включая хранение состояний для stateful-приложений: сложности проектирования архитектуры потоковой обработки событий и способы их решения. Основные сложности проектирования современной архитектуры данных Из-за принципиальных отличий потоковой парадигмы обработки данных от пакетной, что разбиралось здесь, задача проектирования дата-конвейеров сильно усложняется, т.к. редко...
Большинство ETL-конвейеров извлекают данные из реляционных баз в пакетном или микропакетном режиме. Читайте далее, по каким шаблонам реализовать операции извлечения. Моментальные снимки: периодическая выгрузка данных из исходных таблиц Полная периодическая выгрузка данных из одной или нескольких таблиц – это, пожалуй, самый простой метод извлечения изменяемых данных. По своей сути результат полной...
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
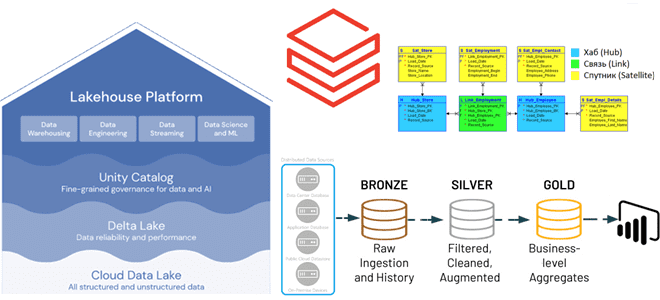
Преимущества методологии Data Vault для проектирования архитектуры данных Lakehouse, а также лучшие практики ее использования с максимальной эффективностью для корпоративного хранилища. Принципы методологии Data Vault и их применение к проектированию DWH Существует множество различных методологий проектирования данных, которые можно использовать при разработке аналитической системы, например, модели звезды и снежинки, подходы...
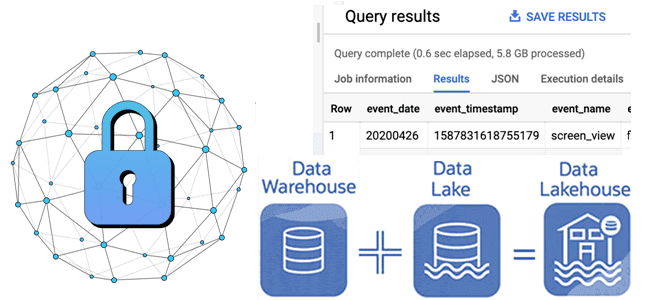
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...
Что такое Databricks SQL и как его ускорить, используя кэширование данных: типы хранилищ данных в платформе Lakehouse и виды кэшей. Что такое Databricks SQL Платформа Databricks Lakehouse предоставляет комплексное решение для хранения данных. Она построена на открытых стандартах и API. Эта архитектура данных сочетает ACID-транзакции и управление данными корпоративных хранилищ...

Зачем разделять таблицы в озере данных, что не так с Hive-разделением и Z-упорядочение в Delta Lake и как работает жидкая кластеризация (Liquid Clustering) – новая стратегия оптимизации размещения данных от Databricks. Что не так с Hive-разделением и Z-упорядочение таблиц в Delta Lake В озере данных физическое расположение данных может оказать...
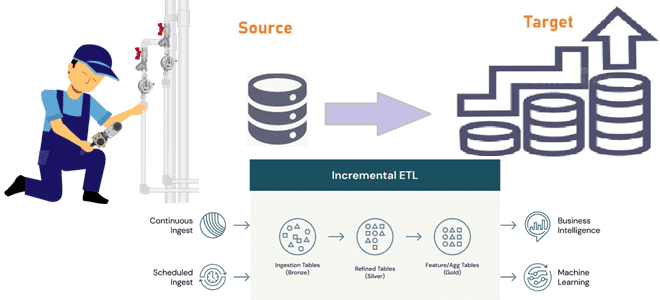
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
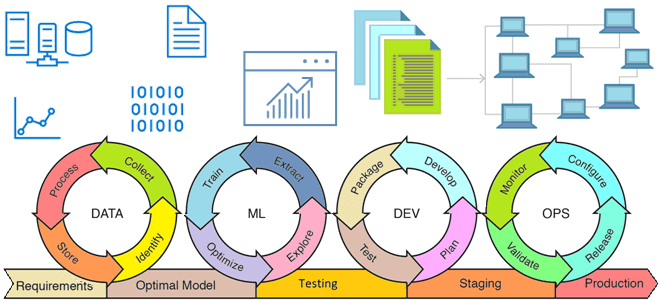
Из каких компонентов состоит архитектура MLOps, что такое инфраструктура как код, как управлять ею с помощью скриптов и почему это нужно на каждом этапе жизненного цикла моделей Machine Learning. Жизненный цикл ML-модели и MLOps MLOps – это набор методов и техник машинного обучения вместе с лучшими практиками разработки, развертывания и...
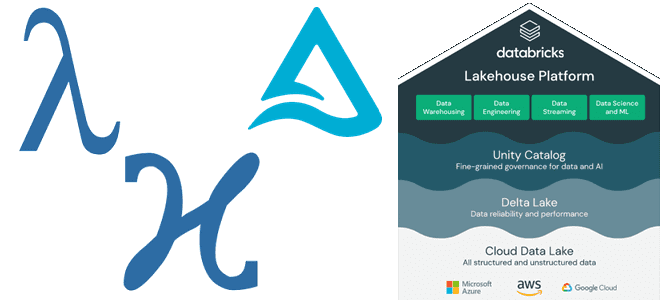
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...
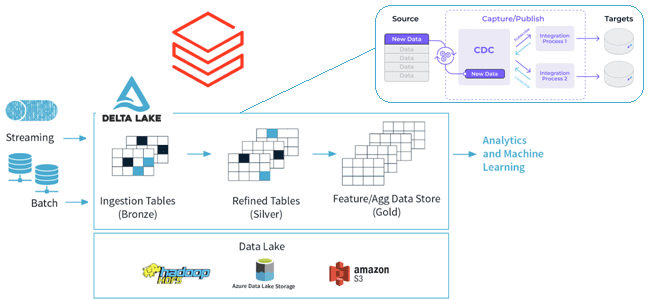
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...
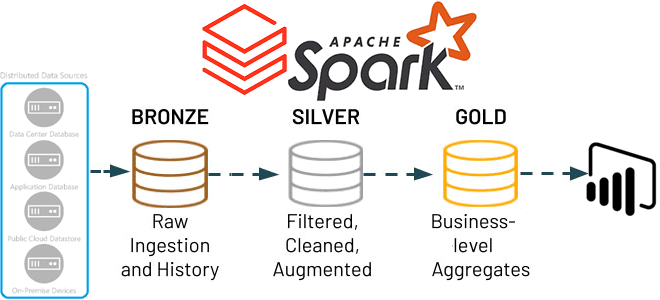
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...

Сегодня разберем распространенные трудности корпоративных платформ обработки и хранения Big Data, а также как избежать этих проблем, используя современные методы и средства проектирования дата-архитектур и инструменты инженерии данных. 7 главных проблем с платформами данных Обычно каждая data-driven компания органично развивает свои платформы данных, усложняя их архитектуры. Но этот процесс эволюционного...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа...

Продолжая вчерашний разговор про Delta Lake на базе Apache Spark от Databricks, сегодня мы расскажем одну из последних новостей о запуске этого решения на Google Cloud с середины февраля 2021 года. Читайте далее, чем хороша эта проприетарная Big Data платформа для аналитики больших данных на Spark, инструментах визуализации и MLOps,...

Сегодня рассмотрим пример построения системы аналитики больших данных для мониторинга финансовых транзакций в реальном времени на базе облачного Delta Lake и конвейера распределенных приложений Apache Kafka, Spark Structured Streaming и других технологий Big Data. Читайте далее о преимуществах облачного Delta Lake от Databricks над традиционным Data Lake. Постановка задачи: финансовая...