Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника.
Прямой поток и подход на основе приемника
Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме из разных источников, т.е. по мере их появления. Наиболее ярким представителем такого потокового источника является Apache Kafka- Распределенная платформа потоковой передачи. Сегодня разберем, как Spark может считывать данные из Kafka. Хотя Apache Spark поддерживает несколько языков программирования (Scala, Java, R, Python), я умею работать только с Python, а потому все примеры буду показывать именно на нем. Для чтения данных из Kafka с помощью PySpark можно выделить следующие подходы:
- подход прямого потока;
- подход на основе приемника;
- структурированный потоковый подход.
Подход прямого потока использует метод createDirectStream() из модуля pyspark.streaming.kafka для чтения данных. Этот метод создает прямое соединение между приложением Spark Streaming и брокерами Kafka, автоматически обеспечивая балансировку нагрузки и отказоустойчивость.
Чтобы проверить, как этот метод работает, я написала и запустила в Google Colab следующий код для чтения данных из топика Kafka, развернутой в облачной serverless-платформе Upstash.
from pyspark.sql import SparkSession
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
# Создаем объект SparkSession и устанавливаем имя приложения
spark = SparkSession.builder \
.appName("MySparkApp") \
.master("local[*]") \
.getOrCreate()
ssc = StreamingContext(spark.sparkContext, 1)
kafkaParams = {
"bootstrap.servers": broker_url,
"auto.offset.reset": "earliest",
"security_protocol": "SASL_SSL",
"sasl_mechanism": "SCRAM-SHA-256",
"sasl_plain_username":username_value,
"sasl_plain_password": password_value,
"enable_auto_commit": True,
"group_id": "new_group"
}
directStream = KafkaUtils.createDirectStream(
ssc,
topics=[topic],
kafkaParams=kafkaParams
)
directStream.pprint()
ssc.start()
ssc.awaitTermination()
Однако, запуск этого кода выдал ошибку о невозможности найти и использовать модуль KafkaUtils, который является частью устаревшего интерфейса PySpark Streaming, поэтому он доступен только в PySpark версии 2.x и ниже. В PySpark версии 3.0 и выше поддержка PySpark Streaming была удалена. Spark Streaming — это предыдущее поколение потокового движка Spark, вместо него теперь используется Spark Structured Streaming – структурированная потоковая передача.
Аналогичным образом у меня не заработал код, реализующий подход на основе приемника, который использует метод createStream() из того же модуля pyspark.streaming.kafka для чтения данных из Kafka. Этот метод создает приемник на рабочих узлах Spark, который получает данные от Kafka, а затем перенаправляет их в приложение Spark Streaming. Этот подход удобен, когда надо читать данные из нескольких топиков Kafka или когда надо использовать высокоуровневый API потребителя Kafka.
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
25 августа, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
Пример Python-кода выглядит так:
from pyspark import SparkContext # импортируем класс SparkContext из модуля pyspark
from pyspark.streaming import StreamingContext # импортируем класс StreamingContext из модуля pyspark.streaming
from pyspark.streaming.kafka import KafkaUtils # импортируем метод KafkaUtils.createStream() для чтения данных из Kafka
# Создаем объект SparkContext и устанавливаем имя приложения
sc = SparkContext(appName="MySparkApp") # создаем объект SparkContext с именем "MySparkApp"
ssc = StreamingContext(sc, 1) # создаем объект StreamingContext с временным интервалом 1 секунда
kafkaParams = {
"bootstrap.servers": broker_url, # адрес Kafka-брокера
"auto.offset.reset": "earliest", # начинать чтение с самого начала топика
"security.protocol": "SASL_SSL", # протокол безопасности
"sasl.mechanism": "SCRAM-SHA-256", # механизм аутентификации
"sasl.username": username_value, # имя пользователя для аутентификации
"sasl.password": password_value, # пароль для аутентификации
"enable.auto.commit": True, # включить автоматический коммит
"group.id": "new_group", # идентификатор группы потребителей
"metadata.broker.list": ",".join(kafka_brokers) # список брокеров Kafka
}
# Читаем данные из топика Kafka с помощью createStream()
receiverStream = KafkaUtils.createStream(
ssc,
None, # заменяем параметр zookeeper на None, так как используем metadata.broker.list
"new_group", # идентификатор группы потребителей
{"my_topic": 1}, # словарь с именами топиков и количеством партиций соответственно
kafkaParams=kafkaParams # параметры доступа к серверу Kafka
)
# Выводим данные на экран
receiverStream.pprint()
ssc.start() # запускаем StreamingContext
ssc.awaitTermination() # ждем остановки приложения
Этот код тоже не заработал на версии Spark 3.4, установленной в Colab, поскольку метод KafkaUtils.createStream() был отмечен как устаревший еще в Apache Spark 2.4.0, а также заменен на KafkaUtils.createDirectStream(), рассмотренный ранее. Метод KafkaUtils.createStream() был стал устаревшим по следующим причинам:
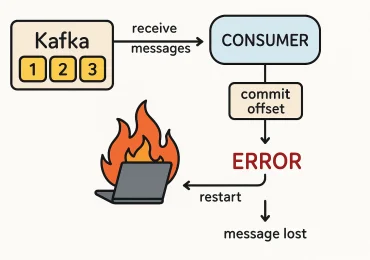
- недостаточная гарантия доставки, т.е. он не гарантирует, что все данные будут успешно доставлены в приложение Spark Streaming. Если произойдет сбой, то некоторые данные могут быть утеряны.
- низкая производительность, поскольку он использует старый API Kafka Consumer, который не поддерживает многопоточную обработку данных. Это может привести к низкой производительности при обработке больших объемов данных.
- ограниченный контроль над чтением данных – метод createStream() не позволяет точно контролировать, какие данные будут прочитаны из Kafka. Например, нельзя указать конкретные партиции для чтения или настроить точную точку восстановления при сбое.
Таким образом, подход прямого потока, который обеспечивает прием данных с малой задержкой с минимальными накладными расходами и задержкой из нескольких топиков и разделов Kafka с автоматической балансировкой нагрузки и отказоустойчивостью, не сработал из-за его устаревания. Которое, в свою очередь, вызвано необходимостью настройки смещений и управление разделами, ограниченного контроля над управлением смещениями и необходимостью поддерживать постоянное и стабильное соединение между приложением Spark Streaming и брокерами Kafka. Аналогичным образом не сработал подход на основе приемника, который обеспечивает лучшую пропускную способность, чем прямой поток и может использовать высокуровневый API потребителя Kafka. Впрочем, этот подход тоже считается устаревшим и имеет те же самые ограничения. Поэтому в Apache Spark 2.0, выпущенном в июле 2016 года, появился Structured Streaming – способ обработки потоковых данных на основе DataSet/DataFrame API. Он позволяет обрабатывать потоковые данные так же, как пакетные путем представления потоковых данных в виде бесконечной таблицы, которая автоматически обновляется при получении новых данных. Это позволяет использовать знакомый SQL-подобный синтаксис для обработки потоковых данных и создания сложных потоковых вычислений. По сравнению с ранее существовавшими методами обработки потоковых данных в Spark, такими как рассмотренные Spark Streaming и Kafka Streaming, структурированная потоковая передача обеспечивает более высокую производительность и точность обработки данных, а также облегчает разработку и отладку потоковых приложений. Как это работает, рассмотрим далее.
Запуск приложения Spark Structured Streaming в Google Colab
Для использования методов структурированной потоковой передачи Spark сперва необходимо установить библиотеки и импортировать модули:
####################################ячейка в Google Colab №1 - установка и импорт библиотек########################################### #установка библиотек !apt-get install openjdk-8-jdk-headless -qq > /dev/null !pip install pyspark !pip install kafka-python !pip install findspark #импорт модулей import pyspark from pyspark.sql import SparkSession from pyspark.sql.functions import from_json, col from pyspark.sql.types import StructType, StringType, StructField from pyspark.sql.functions import * from pyspark.sql.types import * from pyspark.sql.functions import udf import findspark import os os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64" !wget https://repo1.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.12/3.2.4/spark-sql-kafka-0-10_2.12-3.2.4.jar !mv spark-sql-kafka-0-10_2.12-3.2.4.jar /usr/local/lib/python3.10/dist-packages/pyspark/jars/
Затем можно написать код самого приложения PySpark Structured Streaming:
####################################ячейка в Google Colab №2 - код приложения ###########################################
findspark.init()
# Устанавливаем переменную окружения PYSPARK_SUBMIT_ARGS, чтобы указать Spark, какие jar-файлы и пакеты необходимо загрузить при запуске приложения.
# В данном случае мы загружаем пакет spark-sql-kafka-0-10 версии 3.2.4, который позволяет работать с данными из Apache Kafka.
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.4 --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.4 pyspark-shell'
# Создаем объект SparkSession, который является точкой входа в Spark SQL и Spark Streaming API.
spark = SparkSession.builder \
.appName("MySparkApp") \ # Устанавливаем имя приложения
.master("local[*]") \ # режим запуска "local[*]" для запуска приложения локально на всех доступных ядрах процессора
.config("spark.jars.packages", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.4") \ # Устанавливаем конфигурационные параметры для загрузки пакета spark-sql-kafka-0-10
.config("spark.jars", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.4") \
.config("spark.packages", "org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.4") \
.getOrCreate()
spark.conf.set("spark.sql.shuffle.partitions", 1) # Устанавливаем параметр конфигурации spark.sql.shuffle.partitions в 1, чтобы уменьшить количество разделов при обработке данных
stream = spark.read.format("kafka") \# Читаем данные из Kafka в Spark DataFrame с помощью метода read из формата "kafka".
# Устанавливаем параметры доступа к серверу Kafka, имя топика и идентификатор группы потребителей.
.option("kafka.bootstrap.servers", broker_url) \
.option("kafka.security.protocol", "SASL_SSL") \
.option("kafka.sasl.mechanism", "SCRAM-SHA-256") \
.option("kafka.sasl.username", username_value) \
.option("kafka.sasl.password", password_value) \
.option("subscribe", topic) \
.option("kafka.group.id", consumerGroupId) \
.option("startingOffsets", "latest") \ # Устанавливаем смещение чтения начиная с последнего сообщения
.load()
stream.printSchema() # Выводим схему DataFrame на экран
# Выбираем ключ и значение из DataFrame и конвертируем их в строки.
query = stream.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \# Записываем поток данных в консоль
.format("console") \
.option("truncate", "false") \
.trigger(processingTime="1 second") \#настройки триггера
.start()
query.awaitTermination() # Ждем завершения потока
В этом коде используется библиотека findspark, которая позволяет запускать PySpark в интерактивной среде Google Colab. Функция findspark.init() добавляет PySpark в переменную окружения PATH, чтобы Python мог найти установленную версию PySpark и использовать ее для запуска приложения. Если не вызвать функцию findspark.init(), то Python не сможет найти установленный PySpark и получится ошибка при попытке импорта модулей PySpark. При использовании PySpark в другом окружении, таком как standalone-кластер или YARN, функция findspark.init() необязательна.
Поскольку Google Colab довольно сильно ограничивает возможности гибкой настройки программного окружения, это код, написанный без ошибок, не удалось запустить из-за отсутствия нужных зависимостей. Я столкнулась с исключением
AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".
Это указание в строке вывода предписывает запускать приложение, как написано в официальной документации, с использованием
./bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.0 ...
То, что было указано в моем коде через переменные среды с помощью строки
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.4 --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.4 pyspark-shell'
оказалось недостаточно и код не запустился.
Однако, при развертывании на локальной машине с нужными версиями всех используемых библиотек подобной проблемы возникнуть не должно.
Узнайте больше про использование Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники