Денормализация таблиц, оптимизация SQL-запросов, словари вместо измерений и AggregatingMergeTree-движок с инкрементными матпредставлениями для приема измененных данных из PostgreSQL в ClickHouse. Оптимизация SQL-запросов Хотя передача изменений из PostgreSQL в ClickHouse может сопровождаться дублированием или потерями данных, эти проблемы решаемы, о чем мы рассказывали здесь и здесь. Однако, репликация данных из реляционной...
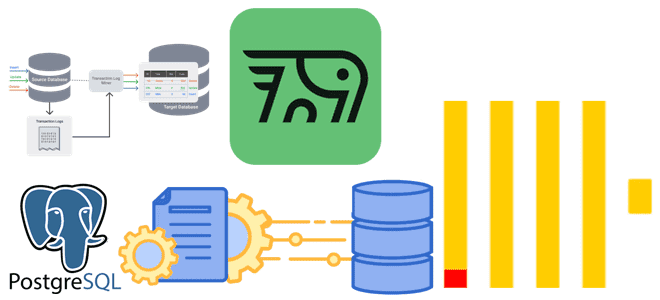
Почему ключи сортировки в ClickHouse могут стать причиной появления дублей или пропусков при CDC-передаче изменений из PostgreSQL и как этого избежать: особенности логической репликации из транзакционной базы данных в аналитическую. Влияние ключей сортировки на CDC-передачу изменений из PostgreSQL в ClickHouse Продолжая разбираться с дублированием данных при передачи изменений из PostgreSQL...
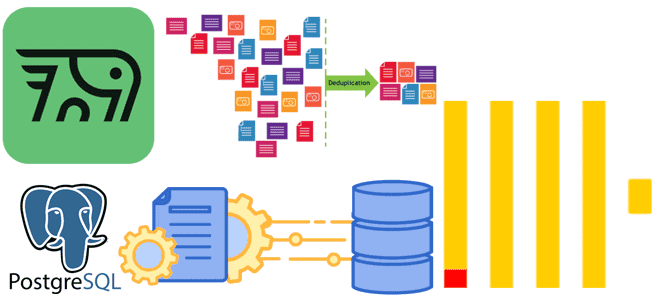
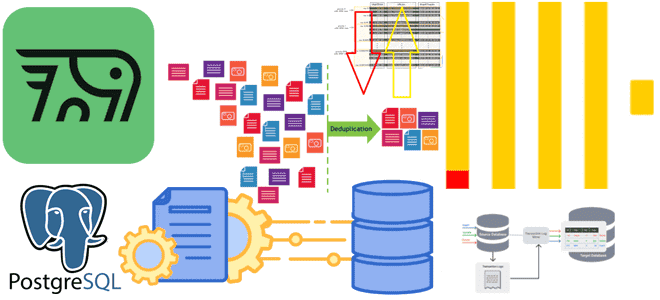
Почему табличный движок ReplacingMergeTree в PeerDB и ClickPipes не избавит от дублей при передаче измененных данных из PostgreSQL в ClickHouse и можно ли полностью выполнить дедупликацию с помощью модификатора FINAL, политики строк, обновляемых представлений или агрегатных и оконных функций. Как движок ReplacingMergeTree допускает дубли при импорте изменений из PostgreSQL в...
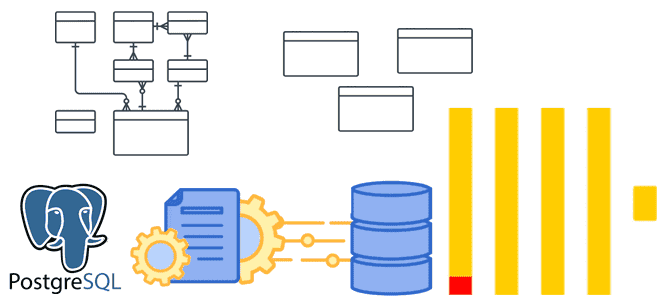
Как передать изменения данных из транзакционной базы в аналитическую без дублей и задержек: CDC-ETL из PostgreSQL в ClickHouse с PeerDB. CDC для ClickHouse с PeerDB и ClickPipes Возможности Clickhouse позволяют построить на нем корпоративное хранилище данных целиком или реализовать отдельный слой, например, для денормализованных витрин. Также совместное использование транзакционных и...

Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста. JSON в ClickHouse Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована...

Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД. Как Clickhouse делает быстрее агрегации в JSON-данных Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне...
Где и как задавать настройки безопасного доступа клиента к кластеру Trino, каким образом обеспечить безопасность внутри кластера и защитить доступ к внешним источникам данных: примеры конфигураций. Как настроить безопасную работу кластера Trino По умолчанию в Trino не включены функции обеспечения безопасности. Однако, это можно настроить для различных частей архитектуры фреймворка:...
Как описать ETL-конвейер захвата, преобразования и передачи изменения данных в YAML-файле: пример конфигурации Flink CDC из PostgreSQL в Elasticsearch. ETL-конвейер Flink CDC в YAML-файле Apache Flink позволяет строить надежные конвейеры обработки данных, используя не только с внутренние API, но и с помощью дополнительных компонентов. Одним из таких компонентов является Flink...

Как расширение Citus повышает производительность PostgreSQL, организуя распределенный кластер с помощью шардирования и почему этого недостаточно для эффективных OLAP-запросов как в Greenplum. Что такое Citus для PostgreSQL Поскольку Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных, у тех, кто знакомится с...
Как без копирования анализировать данные из разных источников в реальном времени с помощью SQL-запросов: каталоги и коннекторы Trino. Коннекторы Trino: как они работают и что настроить в каталоге Вчера мы разобрали, как устроен кластер Trino – аналитического движка с массово-параллельной архитектурой (MPP, Massively Parallel Processing), который обрабатывает данные на нескольких...
Сегодня я на практическом примере покажу тонкости настройки конфигураций JDBC-коннектора источника, передающий новые записи из таблицы PostgreSQL в топик Apache Kafka. Настройка JDBC-коннектора и отправка в Kafka Connect Как я упоминала вчера, помимо CDC-коннектор Debezium, передать данные из реляционной базы данных PostgreSQL в Apache Kafka, также есть JDBC-коннектор от Confluent:...

Что общего между Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium), чем отличаются эти коннекторы и как добавить JDBC-драйвер для передачи данных из PostgreSQL в Apache Kafka на Docker. Коннекторы Kafka к реляционным БД от Confluent О том, что CDC-коннектор Debezium позволяет организовать интеграцию Apache Kafka с реляционной...
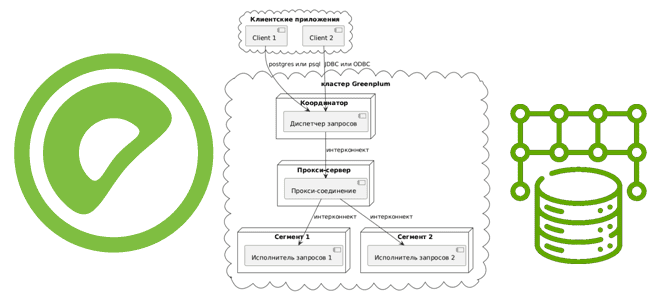
Как сегменты Greenplum взаимодействуют друг с другом для выполнения распределенных SQL-запросов, чем UDPIFC-режим интерконнекта лучше TCP-протокола, зачем проксировать межсетевые соединения и какими командами это сделать. Что такое интерконнекты в Greenplum Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных. Точкой входа в...
Что такое волатильные функции, зачем они нужны и чем опасны: разбираем на примере Greenplum и PostgreSQL. К чему приведет некорректное использование атрибутов изменчивости в SQL-запросе или UDF-функции распределенной MPP-СУБД. Что такое волатильность функции и почему это важно для Greenplum Волатильной или изменчивой считается функция, значение которой может изменяться даже в...

Как решать задачи машинного обучения в Greenplum с агентом gpMLBot и расширением PostgresML: возможности, ограничения и примеры. Что такое gpMLBot: Greenplum Automated Machine Learning Agent Чтобы использовать Greenplum как хранилище данных в задачах машинного обучения, в этой БД поддерживаются соответствующие механизмы. Одним из них является библиотека Apache MADlib, о которой...
Что такое вебхук и как отправить событие из PostgreSQL в Apache Kafka, используя API Webhook на платформе Upstash. NoCode-интеграция БД и брокера сообщений: практический пример. Практический пример: CDC из PostgreSQL в Kafka через веб-хуки Веб-хук или перехватчик – это настраиваемый обратный HTTP-вызов из одной системы к другой. Он используется для...
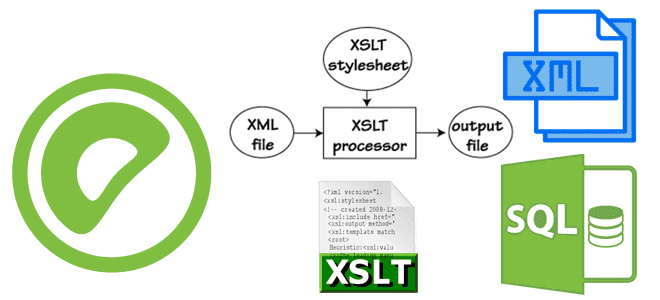
Как Greenplum хранит и обрабатывает XML-документы, зачем для этого нужны утилиты gpfdist и gpload, каковы их конфигурации для выполнения XSLT-преобразований XML-файлов и их загрузки/выборки во внешние таблицы MPP-СУБД. Работа с XML-документами и XSLT-преобразования в Greenplum Greenplum, как и PostgreSQL, также поддерживает работу со сложными типами данных и может вести себя...
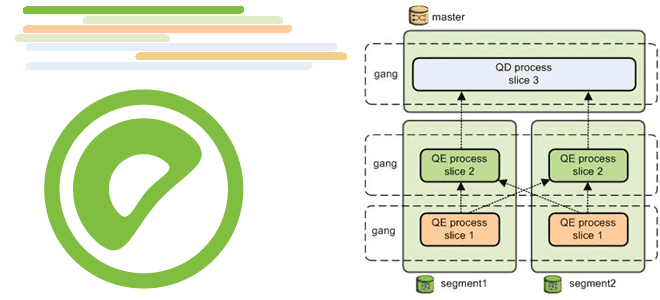
Как координатор Greenplum на мастер-хосте рассылает сегментам планы выполнения запросов, что такое курсор параллельного получения результатов оператора SELECT и каким образом его использовать для аналитики больших данных в этой MPP-СУБД. Особенности рассылки планов SQL-запросов в Greenplum на выполнение Хотя Greenplum основана на PostgreSQL, некоторые механизмы работы этих СУБД отличаются. Например,...
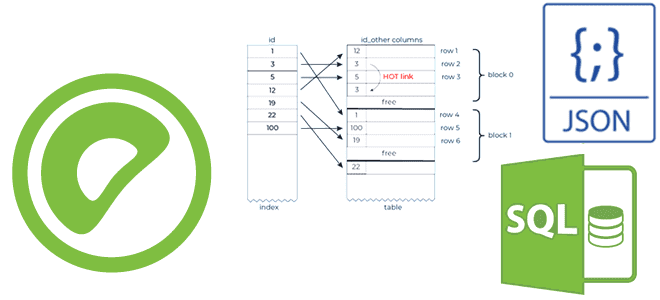
Как Greenplum индексирует JSON-документы, что такое GIN-индекс в PostgreSQL, чем он отличается от B-дерева и хэш-таблицы, когда и как их использовать, а также почему поддерживается только индексация JSONB-полей. Как Greenplum индексирует JSONB-документы Поскольку Greenplum основана на PostgreSQL, она также поддерживает работу со сложными типами данных и может вести себя подобно...
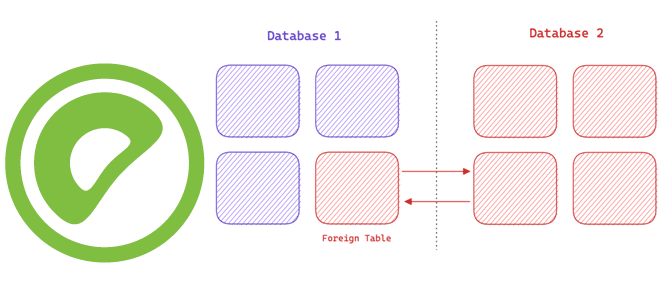
Чем внешняя таблица Greenplum отличается от сторонней, и как они преобразуются друг в друга: организация доступа к данным вне базы, FDW-обертки и протоколы для интеграции MPP-СУБД с другими источниками информации. Сторонняя таблица в Greenplum Термины внешняя (external) и сторонняя (foreign) table похожи, но нюансы их использования в Greenplum отличаются. Такие...