Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
Сегодня я покажу на практическом примере, как реализовать потоковый захват изменения данных из таблицы PostgreSQL и их репликацию в Apache Kafka с помощью Debezium. Создаем и настраиваем свой коннектор на платформе Upstash. Постановка задачи Паттерн захвата измененных данных (CDC, Change Data Capture) является одним из самых распространенных в инженерии данных....
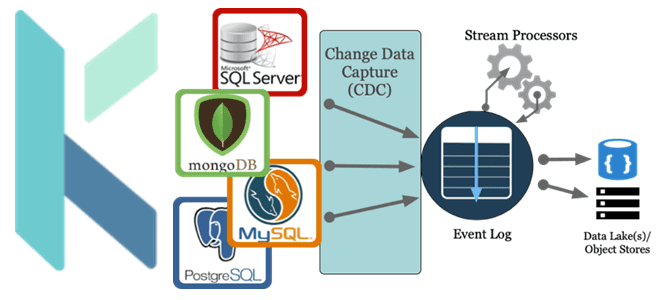
Как реализовать CDC-сценарий, используя платформу оркестрации Kestra вместо Debezium с Kafka Connect для планирования и управления конвейером обработки данных. За счет чего Kestra работает эффективнее Debezium с коннекторами Kafka Connect и при чем здесь Apache AirFlow с NiFi. Что не так с реализацией CDC на Debezium с Kafka Connect Мы...
Мы уже писали про поиск сложных событий при их потоковой обработке средствами Apache Flink. Продолжая эту важную для обучения дата-инженеров тему, сегодня рассмотрим, как CDC-коннектор от GetIndata упрощает запуск распознавание шаблонов на потоках данных из многих источников. Проблемы захвата измененных данных из реляционной базы с помощью JDBC-драйвера и способы их...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...

В этой статье поговорим про интеграцию данных с помощью CDC-подхода и репликацию SQL-таблиц из корпоративной СУБД в несколько разных удаленных хранилищ в реальном времени с применением Apache Kafka и Debezium, развернутых в Kafka Connect и Confluent Cloud. Постановка задачи: CDC с Big Data в реальном времени Рассмотрим кейс, который часто...