
Как Quix Streams реализует отказоустойчивую stateful-обработку потоковых датафреймов из топиков Kafka с помощью встроенного key-value хранилища состояний RocksDB: практический пример. Потоковый stateful-конвейер на Apache Kafka и Quix Streams Продолжая знакомиться с библиотекой Quix Streams, которая позволяет получить потоковые датафреймы из данных в топиках Kafka, сегодня разберем, как здесь организована работа...
Мы уже рассматривали важность мониторинга приложений Apache Flink и говорили про метрики отслеживания задержки обработки данных в потоковых заданиях. Сегодня заглянем под капот этого фреймворка и разберем, какие показатели работы JVM, а также RocksDB особенно важны для дата-инженера и разработчика распределенных приложений. Метрики JVM во Flink-приложениях Напомним, основным языком разработки...

В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness...

В этой статье для инженеров данных и разработчиков Hadoop-приложений рассмотрим опыт индийской компании Wynk по применению Apache Flink в качестве средства потоковой аналитики больших данных пользовательского поведения в мобильных приложениях прослушивания музыки. Особое внимание уделим вопросу формирования и обработки пользовательских сессий. Постановка задачи и выбор решения Wynk Music является одним...

В этой статье для дата-инженеров и разработчиков распределенных приложений разберем кейс американской ИТ-компании FiscalNote, которая использует Apache Flink в качестве движка потоковой обработки информации со сторонних веб-сайтов. Трудности сериализации сообщений из очередей RabbitMQ с разной скоростью поступления Big Data и способы их обхода. Постановка задачи: требования для Flink-приложения FiscalNote специализируется...

3 ноября 2021 года компания Confluent, которая занимается продвижением и коммерциализацией Apache Kafka, выпустила новый релиз ksqlDB, который включает 20 исправленных ошибок и 18 добавленных фич. Самое интересное в выпуске 0.22.0: улучшенные push- и pull-запросы, а также source-потоки и таблицы. 20 исправленных багов и 18 новых фич в ksqlDB 0.22.0...

Разбираемся с механизмами отказоустойчивости Flink-приложений. Что такое контрольные точки (Checkpoint), чем они отличаются от точек сохранения (Savepoint) и что между ними общего. А также при чем здесь snapshot, что выбирать в разных случаях и как это использовать для отказоустойчивости stateful-приложений Apache Flink. Snapshot как механизм обеспечения отказоустойчивости приложений Apache Flink...
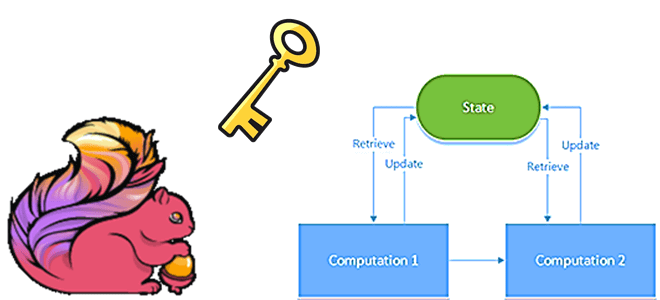
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике. Состояния в Apache Flink Apache Flink поддерживает как stateful-, так и...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...
Сегодня рассмотрим 2 важных понятия архитектуры распределенных систем для хранения и аналитики больших данных на примере платформы потоковой обработки событий Apache Kafka.Читайте далее, что такое согласованность и полнота, а также в чем преимущества строго однократной доставки сообщений на основе транзакционной записи и фиксации смещений в журналах, и как все это...

Вчера мы рассказывали, почему некоторые OOM-ошибки stateful-приложений Kafka Streams могут быть вызваны некорректной работой RocksDB – встроенного key-value NoSQL-хранилище состояний. Сегодня рассмотрим, какие проблемы с дисковыми операциями характерны для этой СУБД, как они отражаются на Kafka-приложениях потоковой аналитики больших данных и каким образом можно это исправить. Быстрые диски, RocksDB и...

Сегодня заглянем под капот stateful-приложений Kafka Streams и рассмотрим, что такое RocksDB, как устроено это key-value NoSQL-хранилище и почему его необходимо настраивать для быстрой и безотказной работы приложений потоковой аналитики больших данных. Читайте далее, какие проблемы приложений Kafka Streams связаны с RocksDB и как ограничить повышенное потребление оперативной памяти. Что...