
Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j: знакомство с Python-пакетом для RDF-графов rdflib-neo4j. Возможности, ограничения и пример использования. Что не так с Neosemantics и зачем нужна очередная библиотека для Neo4j Что такое RDF-графы, триплеты и плагин Neosemantics для работы с этими концепциями в графовой СУБД...
Какие файловые системы поддерживает Apache Flink: средства взаимодействия с файлами, хранящимися локально или в объектных хранилищах HDFS, S3 и GCS. Особенности работы с файловыми системами в Apache Flink Apache Flink имеет собственную абстракцию файловой системы через класс org.apache.flink.core.fs.FileSystem. Эта абстракция обеспечивает общий набор операций и минимальные гарантии для различных типов...
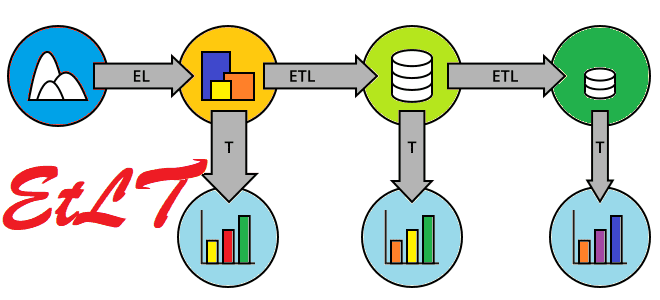
Как развивалась архитектура конвейеров обработки данных, что такое EtLT и почему этот подход почему постепенно заменяет классические ETL и ELT-инструменты. Краткая история развития современной дата-инженерии. От ETL к ELT и обратно: предыстория Архитектура конвейеров обработки данных претерпела несколько итераций от ETL, ELT, XX ETL (Reverse ETL, Zero-ETL) до EtLT. Если экосистема...
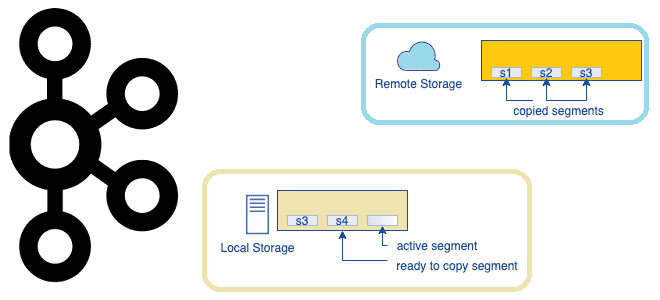
Что представляет собой очередное предложение по улучшению проекта Apache Kafka, которое расширяет возможности этой распределенной платформы потоковой передачи событий, превращая ее в средство долговременного хранения данных. Надежность vs скорость: вечный компромисс в Apache Kafka Изначально Apache Kafka позиционировалась как middleware, т.е. сервисный слой для асинхронной интеграции нескольких информационных систем. Этот...
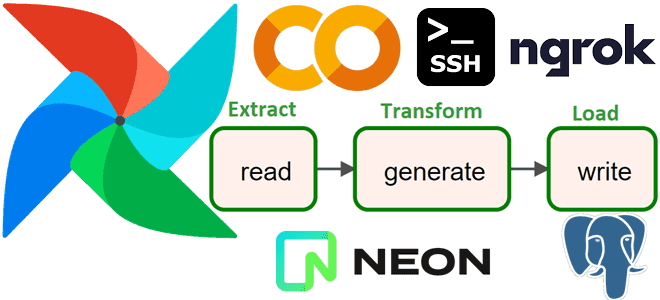
Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа. Постановка задачи Возьмем в качестве примера базу данных для...
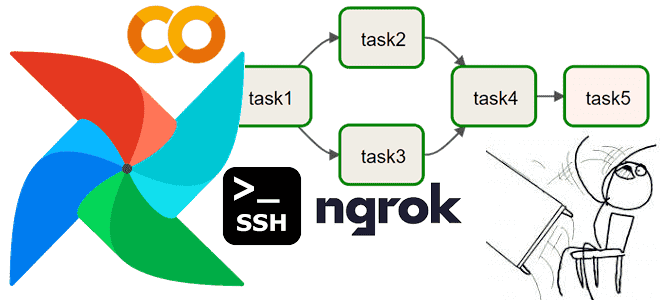
Медленно, муторно, небезопасно: что не так с запуском Apache AirFlow в интерактивной среде Google Colab и можно ли с этим смириться. Разбираем на личном опыте. Трудности работы с Apache AirFlow в среде Google Colab О том, что можно настроить AirFlow в Google Cloud Platform, и запускать DAG-файлы из Colab, используя...

Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...

Как MLOps-инженеры платформы онлайн-курсов Udemy ускорили цикл разработки и внедрения проектов машинного обучения, используя возможности Amazon SageMaker для создания и отладки Spark-приложений в удаленном облачном кластере. MLOps на AWS Чтобы воспользоваться преимуществами бесшовной интеграции процессов разработки и развертывания машинного обучения согласно концепции MLOps, совсем не обязательно выстраивать собственную платформу из...
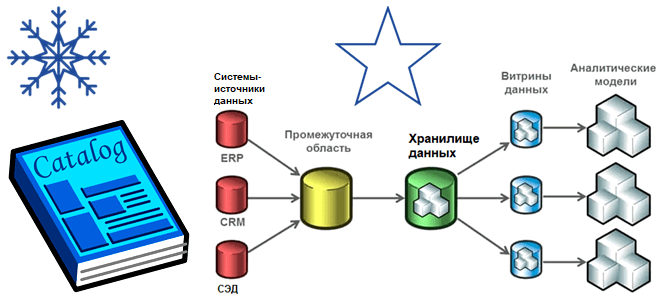
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...