
Для популяризации нашего нового курса для дата-инженеров по Trino мы проводим очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Поскольку Trino является движком для онлайн-обработки больших объемов данных с помощью распределенных SQL-запросов, ему нужна повышенная отказоустойчивость для стабильной работы...

Как оптимизировать многопоточную обработку в ClickHouse и эффективно распределить ресурсы ЦП между разными пользователями и запросами, спланировав рабочую нагрузку. Настройка многопоточной обработки в Clickhouse Чтобы эффективно утилизировать ресурсы для аналитической обработки огромных объемов данных, в ClickHouse можно спланировать рабочую нагрузку, определив приоритеты использования памяти, диска и ЦП для разных видов...
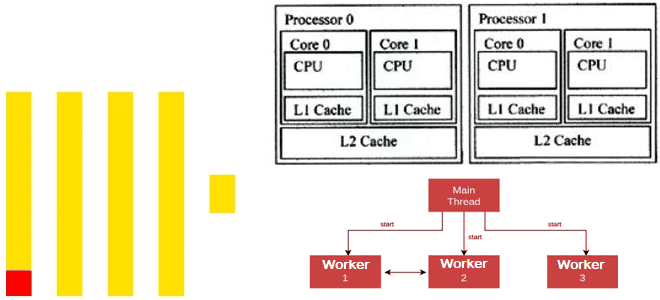
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД. Особенности многопоточной обработки в Clickhouse Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача....
Как эффективно распределять ресурсы ClickHouse между разными пользователями и запросами, настроив политику планирования рабочих нагрузок: примеры и рекомендации. Иерархия планирования рабочей нагрузки в Clickhouse Когда ClickHouse выполняет несколько запросов одновременно, они могут использовать общие ресурсы, например, диски, ЦП и память. Чтобы эффективно распределять ресурсы ClickHouse между разными пользователями и нагрузками,...
Зачем в ClickHouse 25.4 добавлена отложенная материализация и как ленивые вычисления позволяют ускорить работу аналитической СУБД благодаря сокращению объемов читаемых данных и снижению количества операций дискового ввода-вывода. Еще раз о пользе ленивых вычислений Отложенные или ленивые вычисления (lazy evaluation), которые выполняются не сразу, а откладываются до момента, когда их результат...
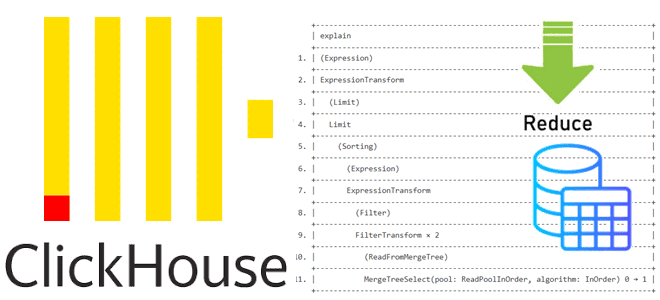
Как устроена оптимизация PREWHERE для сокращения объема сканируемых данных в ClickHouse: разбираемся с деталями реализации и смотрим планы выполнения SQL-запросов. Как устроена оптимизация PREWHERE в ClickHouse Недавно мы писали, как оптимизация PREWHERE позволяет сократить объем сканируемых данных и повысить скорость выполнения SQL-запроса в ClickHouse. Сегодня рассмотрим техническую реализацию этого оператора...
Как ускорить выполнение SQL-запроса в ClickHouse, сократив объем сканируемых данных с помощью оператора PREWHERE: практический пример простой, но эффективной оптимизации. Как работает оператор PREWHERE в ClickHouse ClickHouse имеет ряд многоуровневых оптимизаций, благодаря которым позволяет анализировать огромные объемы данных почти в реальном времени. Одной из таких оптимизаций является PREWHERE, которая сокращает...
Что не так с векторным RAG: обогащение LLM данными из графовых баз с помощью MCP-протокола, вычислительных движков и коннекторов для построения ML-системы агентского ИИ. Что такое графовый RAG для LLM и ИИ-агентов Большие языковые модели (LLM, Large Language Model) и основанные на них системы агентского ИИ активно используют векторные базы...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...

Что общего у StarRocks с Trino, чем они отличаются, когда и что выбирать для практического использования: сравниваем движки для быстрой аналитики больших данных из Data Lake. Чем похожи StarRocks и Trino Вчера мы разбирали, что такое StarRocks, как устроена и где пригодится эта высокопроизводительная аналитическая база данных с открытым исходным...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...
Как сократить затраты на хранение исторических данных в ClickHouse для ИИ-сценариев, сохранив высокую скорость аналитики по широким таблицам и озеру данных: эволюция колоночной СУБД в новом проекте с исходным кодом Antalya от Altinity. Проблемы совмещения ClickHouse с озерами данных и способы их решения Благодаря колоночной структуре хранения данных ClickHouse не...

В поддержку нашего нового курса для дата-инженеров Школа Больших Данных проводит очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Trino – это распределенный SQL-движок с массово-параллельной архитектурой и открытым исходным кодом. Он предназначен для работы с большими объемами данных в...
Как избежать потери данных при асинхронной вставке в Clickhouse при сбое сервера и зачем в версию 24.2 добавлен адаптивный тайм-аут очистки буфера: тонкости ETL с колоночной СУБД. Асинхронная вставка с возвратом подтверждения Недавно мы рассказали, чем хороши асинхронные вставки в ClickHouse и отметили, что при их использовании можно настроить параметр...
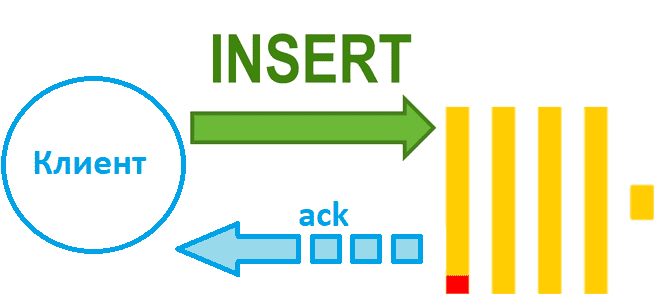
Чем синхронная вставка в ClickHouse отличается от асинхронной и как это настроить: лучшие практики и риски загрузки данных в колоночное хранилище. Синхронная вставка данных в ClickHouse Хотя скорость вставки данных в ClickHouse зависит от множества факторов, ее можно ускорить за счет асинхронных вставок, если предварительное пакетирование на стороне клиента невозможно....
Как именно формат, сортировка, сжатие и интерфейс передачи данных в ClickHouse влияют на скорость операций загрузки: бенчмаркинговое сравнение от разработчиков колоночной СУБД. В каком формате данные быстрее всего вставляются в ClickHouse Продолжая недавний разговор про вставку данных в ClickHouse, сегодня рассмотрим, ключевые факторы, которые особенно сильно влияют на скорость загрузки...

Как выполняется вставка данных в ClickHouse, от чего зависит ее скорость и каким образом ее повысить: последовательность операций загрузки и ее оптимизации. От чего зависит скорость вставки данных в ClickHouse Поскольку ClickHouse часто используется для построения хранилищ или витрин данных, скорость загрузки данных в эту базу очень важна. Хотя на...
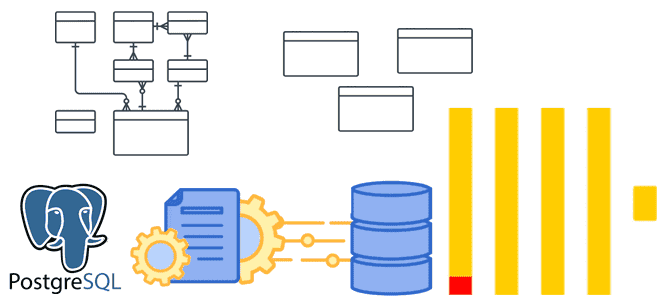
Денормализация таблиц, оптимизация SQL-запросов, словари вместо измерений и AggregatingMergeTree-движок с инкрементными матпредставлениями для приема измененных данных из PostgreSQL в ClickHouse. Оптимизация SQL-запросов Хотя передача изменений из PostgreSQL в ClickHouse может сопровождаться дублированием или потерями данных, эти проблемы решаемы, о чем мы рассказывали здесь и здесь. Однако, репликация данных из реляционной...
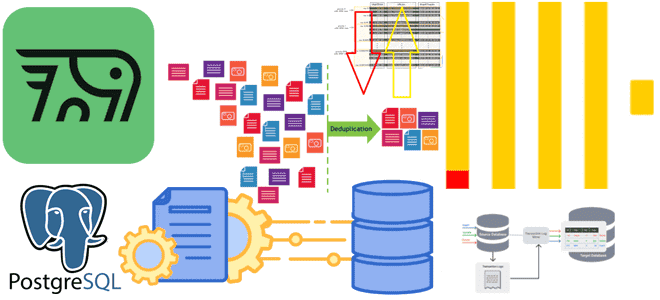
Почему ключи сортировки в ClickHouse могут стать причиной появления дублей или пропусков при CDC-передаче изменений из PostgreSQL и как этого избежать: особенности логической репликации из транзакционной базы данных в аналитическую. Влияние ключей сортировки на CDC-передачу изменений из PostgreSQL в ClickHouse Продолжая разбираться с дублированием данных при передачи изменений из PostgreSQL...
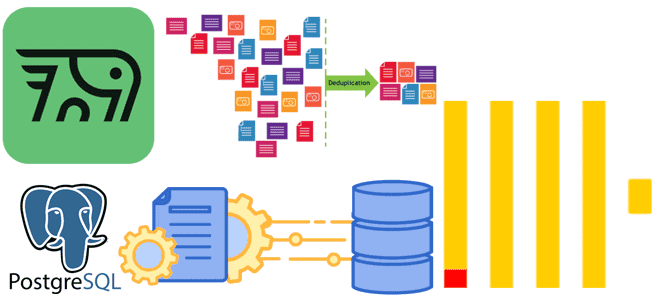
Почему табличный движок ReplacingMergeTree в PeerDB и ClickPipes не избавит от дублей при передаче измененных данных из PostgreSQL в ClickHouse и можно ли полностью выполнить дедупликацию с помощью модификатора FINAL, политики строк, обновляемых представлений или агрегатных и оконных функций. Как движок ReplacingMergeTree допускает дубли при импорте изменений из PostgreSQL в...