
Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения. Расширение стратегий развертывания в Kubernetes с Argo Rollouts Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows -...
В чем сложности оркестрации параллельных заданий в Kubernetes и как их решить с помощью Argo Workflows: обзор фреймворка и практический пример YAML-спецификации шаблона рабочего процесса для развертывания веб-приложения. Что такое Argo Workflows и зачем он нужен Оркестрация параллельных заданий на платформе Kubernetes довольно сложна из-за их внутренних зависимостей друг от...

Какие задачи решают инженеры и администраторы кластера для организации многопользовательского доступа к платформе потоковой передачи событий, а также чем полезен фреймворк Strimzi для развертывания и сопровождения мультиарендной среды Apache Kafka на Kubernetes. Задачи управления мультипользовательским кластером Kafka Выступая в качестве средства интеграции информационных систем и микросервисов, в корпоративной среде Apache...

Школа Больших Данных проводит еще один бесплатный митап для архитекторов платформ данных, инженеров данных, разработчиков, DevOps-, DataOps-инженеров и просто интересующихся о модели Dataflow, API Apache Beam, а также паттернах управления приложениями распределенной обработки данных на Kubernetes. Apache Beam – унифицированный API с открытым исходным кодом, реализующий модель Dataflow, предоставляет единый...

Школа Больших Данных проводит очередной бесплатный митап для архитекторов платформ данных, инженеров данных, разработчиков, DevOps-, DataOps-инженеров и просто интересующихся о моделях и ключевых паттернах управления распределенными приложениями Apache Spark и Apache Flink на Kubernetes. Apache Spark и Flink - это популярные Big Data фреймворки с открытым исходным кодом для распределённой...

Школа Больших Данных проводит бесплатный митап для дата-инженеров, разработчиков и администраторов «Apache Spark на Kubernetes своими руками». Митап состоится 30 мая 2024 года в 17:00 МСК. Мероприятие рассчитано на инженеров данных, разработчиков и просто интересующихся. Специальной подготовки не требуется: неплохо немного уметь программировать на Python, но это не обязательно. В...
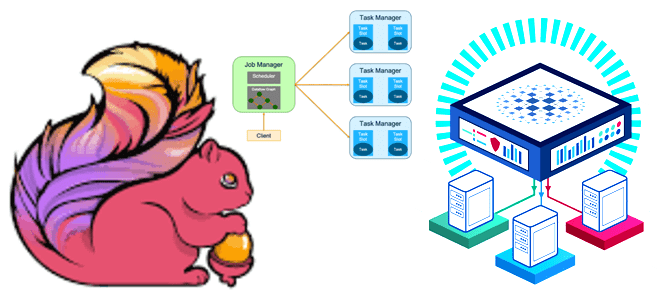
Как работает Flink-приложение, из каких компонентов состоит распределенный кластер и как сделать его отказоустойчивым. Архитектура и принципы работы высокой доступности Apache Flink. Архитектура Flink-приложения: ключевые компоненты и связь между ними Перед тем, как погружаться в средства обеспечения высокой доступности Flink-приложения, вспомним базовые принципы его работы. Сам по себе Apache Flink...

Зачем Apache Flink очередной API для создания распределенных приложений с отслеживанием состояния, чем он полезен и при чем здесь Kubernetes: ликбез по Stateful Functions. Apache Flink Stateful Functions Stateful Functions в Apache Flink – это API, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для...

Сегодня рассмотрим, как развернуть модель машинного обучения в конвейере Apache Kafka, используя потоковый API технологии удаленного вызова процедур от Google под названием gRPC и сервер ML-моделей TensorFlow Serving. Краткий ликбез по gRPC Напомним, gRPC – это технология интеграции систем, включая клиентский и серверный компоненты, основанная на удаленном вызове процедур в...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...

Мы уже делали краткий обзор некоторых исполнителей задач Apache AirFlow. Сегодня рассмотрим более подробно механизмы запуска удаленных задач и разберемся, чем Celery Executor отличается от CeleryKubernetes Executor и как они работают. Виды и назначение исполнителей Apache AirFlow Напомним, Apache AirFlow состоит из нескольких компонентов: Веб-сервер, предоставляющий GUI для настройки DAG...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...
Помимо популярного MLflow от Databrics, специалисты по машинному обучению часто используют другой MLOps-инструмент – Kubeflow, о чем мы писали здесь. Сегодня разберем, как работает это средство, упрощающее разработку и развертывание конвейеров Machine Learning на платформе контейнерной виртуализации Kubernetes. Что такое конвейеры Kubeflow и как они работают Как мы уже отмечали,...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...
Чтобы сделать наши курсы для DevOps-инженеров и специалистов по Machine Learning еще более полезными, сегодня рассмотрим, как автоматизировать развертывание и обслуживание ML-моделей согласно концепции MLOps с помощью GitLab CI/CD, BentoML, Yatai, MLflow и Kubeflow. BentoML для CI в MLOPS При развертывании ML-модели необходимо учитывать следующие аспекты: как была построена модель...

В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi познакомимся с NiFiKop – оператором, который упрощает запуск потокового ETL-маршрутизатора на платформе контейнерной виртуализации Kubernetes. 4 трудности управления кластером Apache NiFi При том, что Apache NiFI имеет множество достоинств, предоставляя возможности сбора, маршрутизации и обогащения потоков данных из разных...

Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера. Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams При работе с крупномасштабными потоковыми данными крайне важно...

Мы уже сравнивали MLflow и Kubeflow, которые позволяют управлять конвейерами машинного обучения. Продолжая эту важную для ML-инженера тему, сегодня рассмотрим 2 других MLOps-инструмента для оркестрации конвейеров Machine Learning: Vertex AI Pipelines и Apache AirFlow. Что такое Vertex AI Pipelines от Google Поскольку цель концепции MLOps в том, чтобы объединить разработку...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...