
В прошлый раз мы говорили про метаданные в Apache Impala. Сегодня поговорим про функции командной строки в Impala. Читайте далее про особенности работы функций командной строки Impala, благодаря которым становится возможным процесс оптимизации обработки Big Data массивов. Как работают функции командной строки в Impala: особенности оптимизации обработки Big Data Командная...

Сегодня в рамках обучения дата-аналитиков и разработчиков распределенных приложений, рассмотрим, что такое пользовательские функции в Apache Hive, как их создать и использовать. А также в чем проблема вызова UDF-функции, зарегистрированной в Hive, из Impala и при чем здесь Sentry. Простые и сложные UDF в Apache Hive Пользовательские функции в Hive...

В этой статье мы поговорим про функции группировки и сортировки в распределенной СУБД Apache Impala. Читайте далее про особенности работы механизма группировки и сортировки Big Data, которые позволяют Impala-разработчику обрабатывать большие массивы данных любых типов с минимальными временными затратами. Как работает механизм группировки и сортировки данных: особенности обработки Big Data...

В прошлый раз мы говорили про особенности работы и создания представлений в Impala. Сегодня поговорим про модифицированный вывод в распределенной SQL-платформе Apache Impala. Читайте далее про особенности модификации вывода записей в Impala, включая базовые операторы, которые применяются для вывода конкретных записей. Базовые SQL-операторы для модификации вывода записей в распределенной СУБД...

Чтобы самостоятельное обучение по Impala стало еще интереснее, сегодня мы предлагаем вам простой тест по основам работы с механизмом представлений, включая их структуру и особенности. Тест по основам работы с представлениями Impala для новичков Для начинающих самостоятельное обучение по Apache Impala мы предлагаем простой интерактивный тест по этой Big Data...

В этой статье мы поговорим про работу с представлениями в Apache Impala. Также рассмотрим структуру представлений в этой SQL-подобной распределенной СУБД, входящей в экосистему Hadoop. Читайте далее про особенности работы с представлениями в Impala, которые делают эту СУБД весьма удобным и мощным средством хранения и обработки Big Data. Как работает...

Сегодня рассмотрим, как можно фильтровать потоки больших данных в Apache NiFi через типовой механизм SQL-запросов. Читайте далее, чем эта ETL-платформа стриминговой маршрутизации Big Data отличается от других систем, которые используют язык структурированных запросов вне СУБД, какие процессоры позволяют работать с потоковыми файлами (FlowFile) как с таблицами базы данных и при...

Недавно мы разбирали особенности интеграции Apache Kudu и Spark. В продолжение этой темы, сегодня поговорим про некоторые особенности выполнения SQL-операций с данными при интеграции этих Big Data фреймворков, а также рассмотрим пример записи данных в мульти-мастерный кластер Куду через Impala с помощью API Data Frame на PySpark. Что приносит Kudu...
Продолжая разбирать production-кейсы реального использования этих технологий Big Data, сегодня поговорим подробнее, каковы плюсы совместного применения Kudu, Spark Streaming, Kafka и Cloudera Impala на примере аналитической платформы для мониторинга событий информационной безопасности банка «Открытие». Также читайте в нашей статье про возможности этих технологий в контексте машинного обучения (Machine Learning), в...

Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени. История Kudu-проекта в Xiaomi Корпорация Xiaomi начала использовать...
Вчера мы говорили про интеграцию Apache Kudu со Spark SQL, Kafka и Cloudera Impala для эффективной организации озера данных (Data Lake), обеспечивающего быструю аналитику больших данных в режиме реального времени. В продолжение этой темы, сегодня рассмотрим 5 примеров практического использования kudu в Big Data проектах, уделив особое внимание системам бизнес-аналитики...

В продолжение темы про совместное использование Apache Kudu с другими технологиями Big Data, сегодня рассмотрим, как эта NoSQL-СУБД работает вместе с Kafka, Spark и Cloudera Impala для построения озера данных (Data Lake) для быстрой аналитики больших данных в режиме реального времени. Также читайте в нашей статье про особенности интеграции Apache...

В этой статье продолжим разговор про Apache Kudu и рассмотрим, как эта NoSQL-СУБД используется с Hadoop и Cloudera Impala, чем она полезна в организации озера данных (Data Lake) и почему Куду не заменяет, а успешно дополняет HDFS и HBase для эффективной работы с большими данными (Big Data). Apache Kudu в...

Сегодня поговорим про движки хранения больших данных в экосистеме Apache Hadoop и рассмотрим, что такое Kudu, каковы особенности применения, достоинства и недостатки этой колоночной NoSQL-СУБД. Также читайте в нашей статье, как Kudu связан с Impala, Spark и другими Big Data фреймворками. Что такое Apache Kudu и где это используется Распределенная...

В продолжение темы про корпоративные хранилища данных, сегодня мы рассмотрим облачные варианты Data Warehouse с учетом тренда на расширенную аналитику Big Data на базе машинного обучения. Читайте в нашей статье про синергию классической LSA-архитектуры локального КХД с Лямбда-подходом, MPP-СУБД, а также Apache Hadoop, Spark, Hive и другими технологиями больших данных....

В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data). Где хранить...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...

Сегодня мы рассмотрим еще один инструмент стека SQL-on-Hadoop: Apache Phoenix, позволяющий выполнять SQL-запросы к нереляционной СУБД HBase. Читайте в нашей статье, что представляет собой этот исполнительный механизм, как он работает и чем отличается от других Big Data решений подобного класса (Cloudera Impala, Apache Hive и Drill). Также мы собрали для...

Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use...
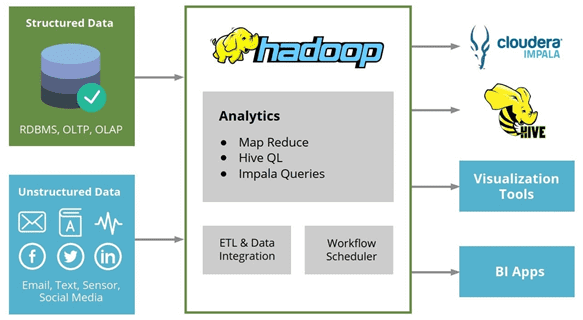
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в...