 1373
1373 
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take().
Преобразования в Apache Spark: виды и особенности реализации
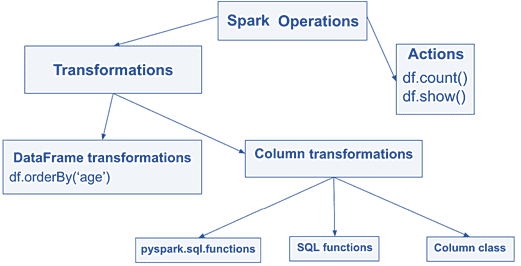
Напомним, в Apache Spark над датафреймами можно выполнить 2 типа операций [1]:
- преобразования (transformations) – отложенные или ленивые вычисления, которые фактически не выполняются сразу, а после материализации запроса и вызове какого-либо действия. При этом создается план запроса, но сами данные все еще находятся в хранилище и ожидают обработки. Поэтому в преобразованиях не следует использовать некоторые приемы разработки Spark-приложений, такие как аккумуляторы, о чем мы рассказываем в новой статье.
- действия (actions) – функции, запрашивающие вывод. При этом не только создается план запроса, но и оптимизируется оптимизатором Spark, а также физический план компилируется в RDD DAG, который делится на этапы (stages) и задачи (tasks), выполняемые в кластере. Подробнее о том, как связаны эти понятия и чем они отличаются, читайте здесь. Оптимизированный план запроса генерирует высокоэффективный Java-код, который работает с внутренним представлением данных в формате Tungsten [2].
Преобразования бывают 2-х видов: над целым датафреймом и над его отдельными столбцами (column transformation). Из преобразований над датафреймами на практике чаще всего используются следующие [1]:
- select(), withColumn() — создание проекций столбцов;
- filter() – фильтрация;
- orderBy(), sort(), sortWithinPartitions() – сортировка;
- Different(), dropDuplicates() – удаление дублей (дедупликация), о чем мы писали здесь;
- join() — для операций соединения, про которые мы рассказывали в этой статье;
- groupBy() – агрегация, которая относится к shuffle-операциям, что мы разбирали в этом материале.
Колоночные преобразования выполняются над отдельными столбцами внутри, например, withColumn() и select() или операциях selectExpr() для добавления новых столбцов в DataFrame.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
21 сентября, 2026
Продолжительность
22 ак.часов
Стоимость обучения
51 200
Как мы уже упоминали вчера, Apache Spark позволяет получить один и тот же результата разными способами. При выборе того или иного способа стоит помнить о нюансах его применения. В частности, withColumn() проецирует все столбцы из DataFrame и добавляет один новый с заданным именем. А select() проецирует только те столбцы, которые передаются в качестве аргумента. Поэтому, если в результате нужны все остальные столбцы, их нужно перечислить явно или использовать обозначение со звездочкой df.select(‘*’, …). При этом результирующий столбец преобразования внутри select будет иметь имя по умолчанию, которое можно переименовать с помощью alias().
Другой пример — функция expr() позволяет передавать SQL-выражение в виде строки в кавычках, аналогично selectExpr(), который является ярлыком для совместного использования select() и expr(). В самом выражении допустимо использовать любую из функций Spark SQL. Таким образом, SQL-функции с колоночным преобразованием expr() дополняют и расширяют возможности пакета pyspark.sql.functions, позволяя обойти некоторые ограничения, например, динамически вычислять длину подстроки из другого столбца.
Подводя итог колоночным преобразованиям в Apache Spark, структурируем их по следующим категориям [1]:
- DSL-функции из пакета sql.functions;
- методы класса Column, которые вызываются для колоночного объекта;
- функции из Spark SQL API для использования внутри expr() или selectExpr().
Все эти преобразования эквивалентны с точки зрения производительности, т.к. являются отложенными (ленивыми), автоматически обновляя план запроса. Также можно выделить еще 3 группы расширенных преобразований столбцов:
- определяемые пользователем функции (UDF, user-defined functions), позволяющие расширить API DataFrame с помощью простого интерфейса и реализовать любое настраиваемое преобразование, по умолчанию не доступное в API;
- функции высшего порядка (HOF, higher-order functions) — отлично поддерживаются с версии Spark 2.4 и используются для преобразования и управления сложными типами данных, такими как массивы или соответствия (map);
- оконные функции (window functions) – для вычисления различных агрегатов или ранжирования по группам строк в определенном временном окне или фрейме.
Действия над датафреймами
Действия — это функции, в которых мы запрашиваем некоторый вывод. Эти функции запускают вычисление и запускают задание в кластере Spark. Обычно одно действие запускает одно задание, но бывает и больше, например, как функция show(), если в первых 20 строках нет нужного раздела данных [3]. На практике в Apache Spark чаще всего используются следующие действия [1]:
- count() — вычисляет количество строк в DataFrame;
- show() — выводит на экран 20 записей из DataFrame;
- collect() — выводит все записи на экран, собирая все данные от всех исполнителей и передавая их драйверу. В случае большого объема данных это может привести к сбою драйвера из-за ограниченности его памяти. Но эта функция полезна, если данные уже отфильтрованы или достаточно агрегированы, т.е. их размер — не проблема для драйвера.
- toPandas() — аналог collect(), но результатом является не список записей, а датафрейм Pandas;
- take(n) — тоже аналог collect(), который собирает не все записи, а n. Пригодится при проверке наличия данных в отдельном датафрейме или он пуст, например, take (1).
- write — создает записывающий обработчик DataFrame, который позволяет сохранять данные во внешнем хранилище.
О других причудах API DataFrame читайте в нашей новой статье. А детально разобраться в практическом использовании преобразований и действий Apache Spark в рамках разработки распределенных приложений и аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark

