
Мы уже писали о том, как Trino работает с удаленными объектными хранилищами и файловыми системами. Сегодня поговорим о том, какие изменения выпущены в февральском релизе 2025 года, почему в Trino удалена поддержка доступа к Azure Storage, Google Cloud Storage, S3 и S3-совместимым файловым системам через Hive и что использовать вместо...

Хотя Apache Pig сегодня не самый актуальный инструмент для аналитики больших данных в экосистеме Hadoop, дата-инженеру полезно знать его основные принципы работы и ключевые отличия от Hive. Также рассмотрим, чем Hive отличается от Pig в качестве средства SQL-on-Hadoop. Что такое Apache Pig Apache Pig – это высокоуровневый процедурный язык для...
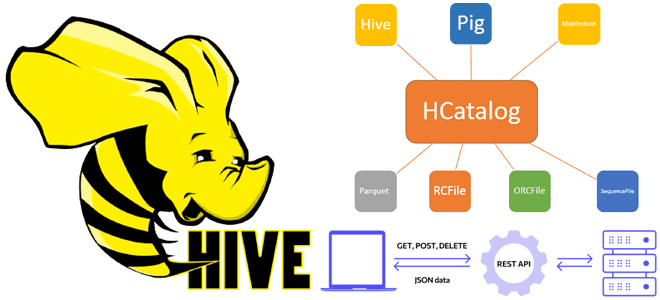
Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton. Принципы работы компонента WebHCat как REST-сервиса Apache Hive Будучи NoSQL-хранилищем класса...

16 ноября 2022 года вышел 2-ой альфа-релиз Apache Hive 4.0.0. Какие ошибки в нем исправлены и что за новые функции, важные для дата-инженера и администратора кластера Hadoop, появились. А перед этим вспомним основные принципы работы Apache Hive. Принципы работы Apache Hive Apache Hive является популярным инструментом стека SQL-on-Hadoop, позволяя обращаться...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...

Сегодня разберем, как автоматизировать наполнение озера данных на HDFS через загрузку таблиц из реляционной базы MySQL в Hive с помощью Apache NiFi. Какие процессоры NiFi следует использовать и зачем предварительно разделять таблицу Apache Hive. Пример ETL-конвейера на процессорах Apache NiFi Apache NiFi часто используется дата-инженерами в качестве средства автоматизации и...
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...

В этой статье для обучения дата-инженеров и администраторов SQL-on-Hadoop рассмотрим способы обеспечения информационной безопасности и защиты данных от несанкционированного доступа в Apache Hive. Классический security-набор: аутентификация, авторизация и шифрование. Авторизация и аутентификация в Apache Hive Будучи популярным инструментом стека SQL-on-Hadoop, Apache Hive поддерживает все механизмы обеспечения информационной безопасности, поддерживаемый базовой...
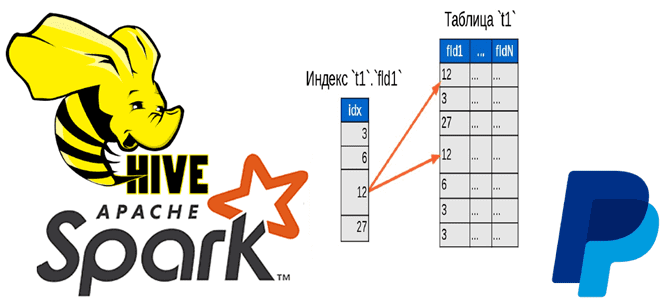
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...

Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...

В рамках обучения аналитиков данных, дата-инженеров и разработчиков распределенных приложений, сегодня поговорим про материализованные представления в Apache Hive. Что это такое, зачем нужно и как реализуется в самом популярном NoSQL-хранилище стека SQL-on-Hadoop. Что такое материализованное представление и зачем это надо в аналитике больших данных: краткий ликбез Аналитика данных включает в...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...
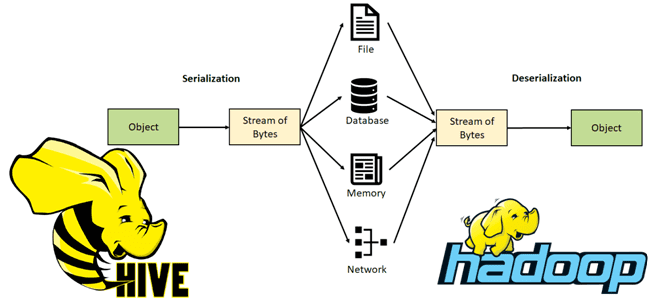
Чтобы добавить еще больше практики в наши курсы для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим тонкости сериализации данных в Apache Hive. Читайте далее, как этот популярный SQL-on-Hadoop инструмент обрабатывает данные из HDFS, что такое SerDe и как написать собственный сериализатор/десериализатор. Сериализация и десериализация данных в Apache Hive В настоящее...

В этой статье для обучения дата-инженеров и аналитиков данных заглянем под капот Apache Hive, чтобы разобраться с механизмов LLAP. Как этот движок повышает производительность популярного SQL-on-Hadoop инструмента, поддерживая длительные процессы на одних и тех же ресурсах для кэширования и аналитической обработки больших данных. Что такое LLAP в Apache Hive и...

Сегодня рассмотрим несколько полезных приемов по работе с Apache Hive, которые пригодятся инженеру данных и специалисту по Data Science в проектах аналитики больших данных. Как разделить и сегментировать таблицы, зачем изменять значение конфигурации памяти этапов MapReduce, чем полезна автоматическая обработка асимметрии данных и еще пара лайфхаков для ускорения выполнения SQL-запросов...

В апреле 2022 года вышел очередной минорный релиз Apache Hive, который работает с Hadoop версии 3. Рассмотрим основные улучшения и исправленные ошибки этого обновления, которые пригодятся дата-инженеру и разработчику распределенных приложений аналитики больших данных. Исправленные ошибки В апрельском выпуске популярного NoSQL-хранилища Apache Hive, которое реализует возможность обращения к данным в...

Для обучения дата-инженеров и аналитиков данных, сегодня рассмотрим приемы оптимизации SQL-запросов в Apache Hive, выполняемых движком Tez. Каким образом Tez рассчитывает оптимальное количество редукторов, зачем включать индексацию фильтров, как статистика таблицы помогает улучшить план выполнения запросов и что за конфигурации нужно менять. 3 движка выполнения запросов в Apache Hive Напомним,...