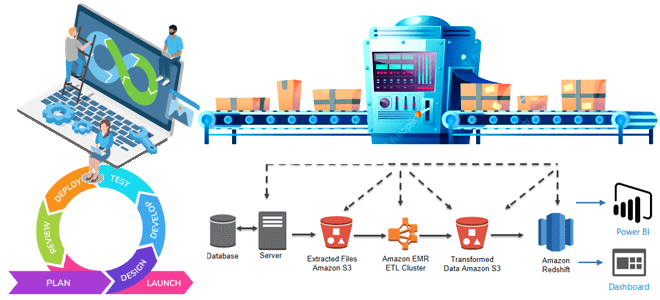
Чем инженерия данных отличается от разработки ПО, как организовать оркестрацию конвейеров обработки данных и внедрить лучшие практики CI/CD. Почему дата-инженерия отличается от разработки ПО При том, что между инженерией данных и разработкой программного обеспечения (ПО) очень много общего, эти ИТ-дисциплины довольно сильно отличаются. Хотя в обоих направлениях используется облачная инфраструктура,...

Что такое dbt, чем полезен этот инструмент для анализа и инженерии данных, зачем переносить в него бизнес-логику обработки данных и представлять эти задачи в DAG-конвейере Apache AirFlow. Python и SQL для анализа данных и дата-инженерии: versus или вместе? Распил крупных монолитных систем на множество автономных взаимодействующих друг с другом приложений...
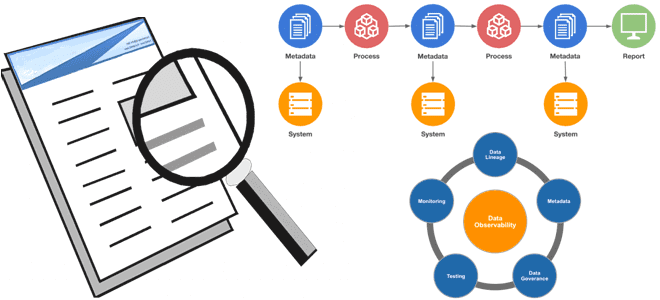
Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии. Почему важна наблюдаемость данных Цифровизация предполагает управление на основе качественных...

В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить...

Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...

Аналитика больших данных напрямую связана с их качеством, которое необходимо отслеживать на каждом этапе непрерывного конвейера их обработки (Pipeline). Сегодня рассмотрим методы и средства обеспечения Data Quality на примере корпорации Airbnb. Читайте далее про лучшие практики повышения качества больших данных от компании-разработчика самого популярного DataOps-инструмента в мире Big Data, Apache...
Продвигая наши курсы по Apache AirFlow для инженеров Big Data, сегодня расскажем, чем этот фреймворк отличается от Luigi – другого достаточно известного инструмента оркестровки ETL-процессов и конвейеров обработки больших данных. В этой статье мы собрали для вас сходства и отличия Apache AirFlow и Luigi, а также их достоинства и недостатки,...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

Вчера мы рассматривали проблему управления накладными расходами в сложных конвейерах обработки больших данных на примере использования Apache AirFlow в агрегаторе аренды частного жилья Airbnb. Сегодня разберем, как именно инженеры компании решили проблему роста накладных расходов, отделив бизнес-логику от логики оркестрации в конвейерах Spark-заданий. Читайте далее про принципы проектирования Big Data...

При всех своих достоинствах Delta Lake, включая коммерческую реализацию этой Big Data технологии от Databricks, оно обладает рядом особенностей, которые могут расцениваться как недостатки. Сегодня мы рассмотрим, чего не стоит ожидать от этого быстрого облачного хранилище для больших данных на Apache Spark и как можно обойти эти ограничения. Читайте далее,...

Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...

Ранее мы уже писали про DataOps- и DevOps-инженеров, а также про администраторов больших данных. Продолжая тему гибкого управления проектами (Agile) для повышения эффективности и ускорения бизнес-процессов, сегодня поговорим о том, какие еще специалисты нужны для успешного Big Data проекта. Профильные категории и процессы Big Data проекта Независимо от конечной цели...

Мы уже писали о происхождении термина DataOps, а также про методы и средства реализации этой концепции непрерывной интеграции данных между процессами, командами и системами в рамках data-driven company. Продолжая тему развития Agile-подходов в мире больших данных, сегодня рассмотрим, чем отличаются сферы ответственности DataOps- и DevOps-инженеров и почему оба этих специалиста...

DataOps (DATA Operations, датаопс), по аналогии с DevOps (DEVelopment Operations, девопс) — это концепция и набор практик непрерывной интеграции данных между процессами, командами и системами для повышения эффективности корпоративного управления или отраслевого взаимодействия за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на...