
До этого момента все наши DAG-и жили по расписанию. schedule_interval='@daily' - это классика. Но современный бизнес не хочет ждать "утреннего отчета". Если данные прилетели в 14:00, отчет должен быть готов в 14:10, а не на следующее утро. Здесь мы сталкиваемся с фундаментальным конфликтом: Airflow - это Batch-инструмент (запускает задачи...

Как управлять топиками Kafka: полное удаление, очистка и аварийные сценарии Apache Kafka — мощный инструмент, но без должного ухода он быстро "захламляется". Топики, которые вы создавали для тестов, старые проекты или просто логи, со временем начинают занимать место и мешать. А иногда они разрастаются так, что кластер "ложится"...
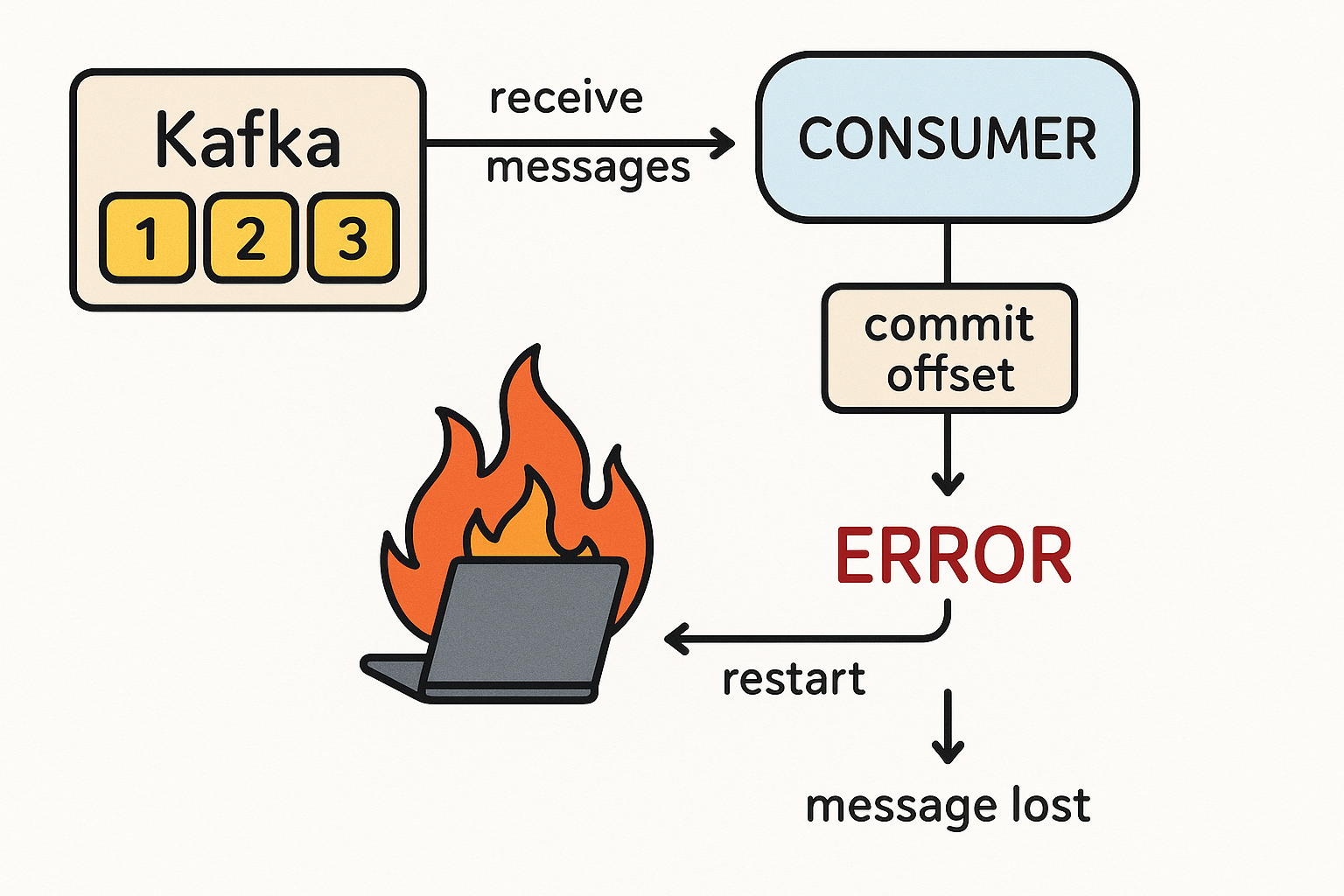
В мире распределенных систем, гарантии доставки сообщений, при передаче данных между сервисами — это фундаментальная задача. Но что происходит, когда мы отправляем сообщение из точки А в точку Б через сеть, которая по своей природе ненадежна? Сетевые задержки, сбои серверов, перезапуски приложений — все это может привести к потере или...
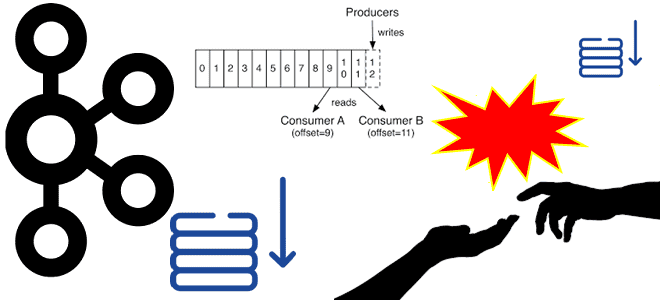
Когда и зачем фиксировать смещение потребителей Kafka вручную, с какими проблемами можно при этом столкнуться и как улучшение KIP-1094 обеспечивает целостность потоков данных в распределенных средах. Когда и зачем фиксировать смещения потребителей в Kafka вручную Недавно мы разбирали, как выполняется автоматическая фиксация смещений потребителей в Apache Kafka. Она выполняется периодически....
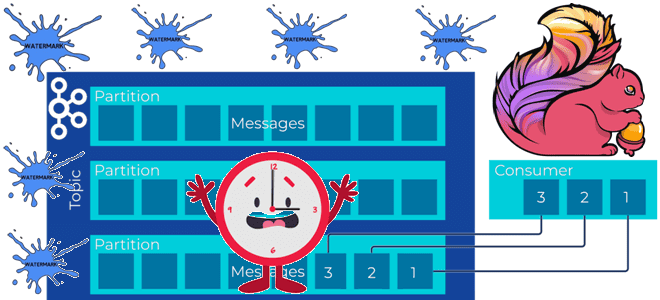
Почему задание Flink не обрабатывает потоковые данные из топика Kafka и при чем здесь водяные знаки: причины потери данных или растущей задержки вычислений и способы их решения. Почему задание Flink не обрабатывает потоковые данные и при чем здесь водяные знаки? Рассмотрим простой потоковый конвейер на Apache Flink и Kafka: задание...
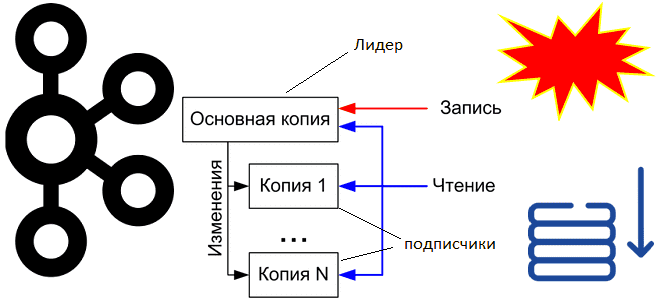
Как Apache Kafka обеспечивает упорядоченность сообщений в рамках раздела, где хранятся смещения потребителей и зачем их фиксировать вместе со эпохой брокера-лидера. Что такое смещения потребителей Apache Kafka и где они хранятся Асинхронная интеграция между информационными системами через Apache Kafka основана на смещениях потребителей – позиции сообщения в разделе топика. Раздел...
Почему MCP-серверы с технологиями потоковой передачи событий в LLM стали трендом: примеры обогащения ИИ-агентов контекстом из Kafka. Внедрение MCP в Confluent Cloud для взаимодействия с Apache Kafka Хотя MCP-протокол, позволяющий ML-модели новыми контекстными данными, что необходимо для больших языковых моделей (LLM, Large Language Model), довольно прост с технической точки зрения,...

Почему не рекомендуется публиковать в Kafka сообщения больших размеров, и как это сделать, если очень нужно: когда приходится перенастраивать конфигурации продюсера, топика и потребителя, и какие это параметры. Почему не нужно публиковать в Kafka сообщения больших размеров Apache Kafka, как и другие брокеры сообщений, оптимизирована для передачи данных небольшого размера....
Полный отказ от ZooKeeper, изменение протокола перебалансировки потребителей, защита транзакций на стороне сервера, ELR-реплики и другие важные новинки Apache Kafka 4.0. Главные изменения в брокерах, продюсерах и потребителях Apache Kafka 4.0 Несколько дней назад, 18 марта 2025 года вышел мажорный релиз Apache Kafka 4.0 – первый крупный выпуск, работающий полностью...
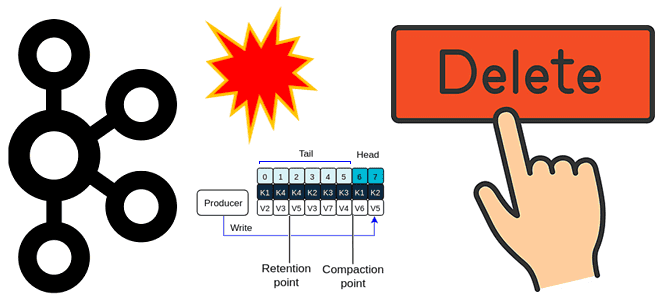
Почему нельзя просто взять и удалить топик Apache Kafka: что проверить и перенастроить, с помощью каких инструментов и чем можно обойтись вместо непосредственного удаления. Проблемы удаления топика Apache Kafka и их решения Когда у вас есть собственный инстанс или даже кластер Apache Kafka с полными правами на все манипуляции с...
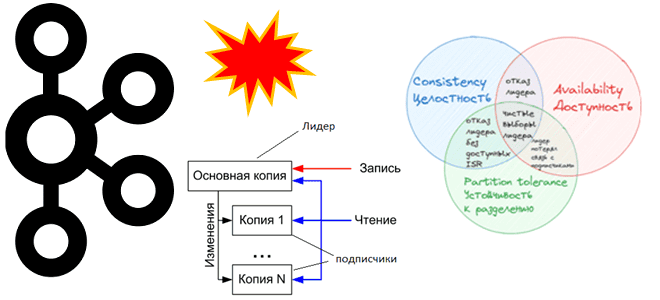
Как Apache Kafka реализует компромиссы CAP-теоремы и при чем здесь чистые выборы лидера: проблемы целостности, доступности и устойчивости в распределенной системе с репликацией данных. CAP-теорема в кластере Apache Kafka При публикации сообщений в Apache Kafka, развернутой в кластере из нескольких узлов, данные сохраняются в брокере-лидере раздела, а затем реплицируются по...
Как получить спецификацию AsyncAPI из кода с помощью декораторов функций публикации и потребления сообщений средствами Python-библиотеки FastStream: простой пример потокового конвейера на Apache Kafka. Еще раз про FastStream и спецификацию AsyncAPI Вчера я рассказывала про Python-библиотеку FastStream для разработки потоковых конвейеров на Apache Kafka, RabbitMQ, NATS и Redis. Помимо мощного,...

Чем хороша Python-библиотека FastStream и как ее использовать для потоковой публикации данных в Apache Kafka: практический пример асинхронной отправки JSON-сообщений. О библиотеке FastStream Для Python-разработчиков есть довольно много библиотек, позволяющих взаимодействовать с Apache Kafka: kafka-python, confluent-kafka, Quix Streams и другие клиенты. О сравнении kafka-python и confluent-kafka я писала здесь, а...
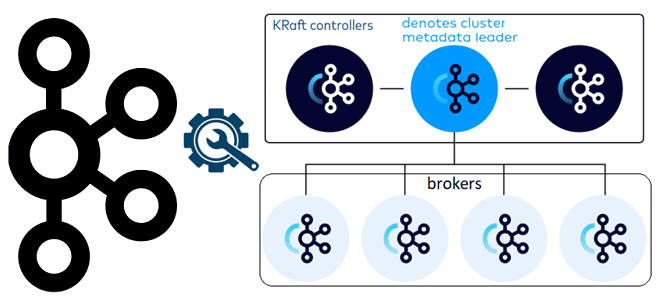
Чем контроллеры Kafka в режиме KRaft отличаются от режима Zookeeper, как их настроить и чем статический кворум отличается от динамического: краткий ликбез для администратора кластера. Брокеры и контроллеры: новые роли серверов Kafka в режиме KRaft Поскольку уже совсем скоро, в мажорном релизе Kafka 4.0, ожидается полный отказ от Zookeeper в...

Как Quix Streams реализует отказоустойчивую stateful-обработку потоковых датафреймов из топиков Kafka с помощью встроенного key-value хранилища состояний RocksDB: практический пример. Потоковый stateful-конвейер на Apache Kafka и Quix Streams Продолжая знакомиться с библиотекой Quix Streams, которая позволяет получить потоковые датафреймы из данных в топиках Kafka, сегодня разберем, как здесь организована работа...

Быстрая и простая обработка потоков сообщений в одном приложении с Quix Streams вместо Kafka Streams: практический пример на Python с обогащением и фильтрацией данных. Практический пример потокового конвейера с Apache Kafka и Quix Streams Сегодня я познакомилась с Quix Streams - очередной замечательной библиотекой для создания потоковых конвейеров обработки данных...

Как реализовать концепцию обратного давления (backpressure) в потоковой обработке событий с Apache Kafka: настройка конфигураций на стороне приложений-продюсеров и потребителей, а также мониторинг системных метрик. Обратное давление при публикации событий в Kafka Мы уже писали о том, зачем нужна концепция обратного давления (backpressure) в потоковой передаче событий и как она...
Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg. Очередная попытка унификации пакетной и потоковой парадигмы Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике,...
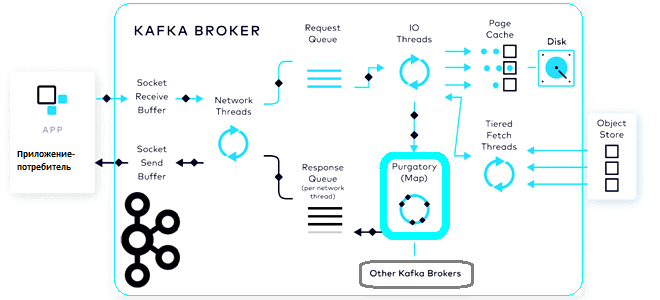
Что такое чистилище запросов, зачем это в потоковой обработке данных, при чем здесь иерархические колеса времени и как эта структура данных помогает Apache Kafka выполнять сотни тысяч асинхронных операций в секунду. Что такое чистилище запросов и зачем это в Kafka Будучи сложной распределенной системой, Apache Kafka реализует несколько типов запросов,...

Как передать JSON-документы из топика Kafka в Elasticsearch, используя OpenSearch Sink Connector. Подробная демонстрация с настройкой и регистрацией коннектора в Kafka Connect. Настройка sink-коннектора и отправка в Kafka Connect Как передать данные из Kafka в Elasticsearch, я уже показывала здесь, развернув экземпляр Kafka в облаке на платформе Upstash. Однако, с...