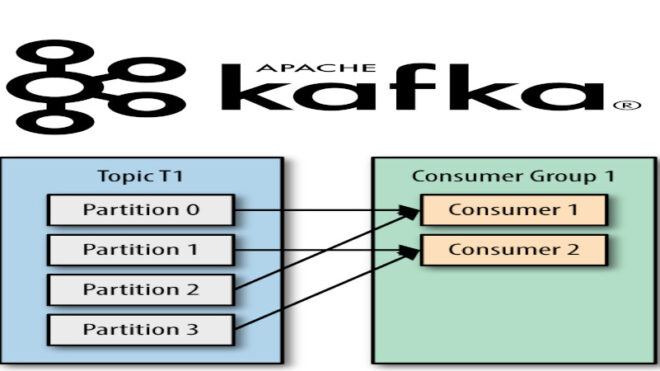
Потребитель – это приложение, которое подписывается на серверный канал и получает новые сообщения.
Примеры потребителей в распределенных системах могут включать в себя [1]:
-
Потребители сообщений в системах сообщений: в распределенных системах, использующих системы сообщений (например, Apache Kafka, RabbitMQ), потребителем может быть приложение или сервис, которое подписывается на определенные темы или очереди, чтобы получать и обрабатывать сообщения.
-
Клиенты в клиент-серверных приложениях: в клиент-серверной архитектуре распределенной системы клиенты являются потребителями услуг, предоставляемых сервером. Например, веб-браузеры могут быть потребителями веб-серверов.
-
Потребители в системах потоковой обработки данных: в системах потоковой обработки данных потребители могут обрабатывать и анализировать поступающие потоки данных. Это может включать в себя обработку событий в реальном времени, анализ данных и так далее.
В качестве примера ниже рассмотрим пример потребителя в контексте брокера Apache Kafka.
Kafka-потребитель (Consumer) представляет собой фрагмент программного кода, ответственного за прием Big Data сообщений, сгенерированных продюсером. Этот процесс получения сообщений также происходит в распределенной среде в реальном времени, что обеспечивает эффективную передачу данных в системе Kafka. Потребитель, как и продюсер, имеет 3 базовых атрибута[2]:
- bootstrap.servers – список брокеров для соединения с кластером Kafka;
- deserializer – класс-десериализатор, применяемый для десериализации (восстановление структуры объекта из байтового массива) ключей сообщений. В качестве десериализатора используется класс StringDeserializer, так как все при десериализации объекты автоматически принимают стрококвый тип (даже если до этого они были другого типа);
- group.id – свойство, отвечающее за создание группы потребителей для одного из экземпляров класса потребителя.
Следующий код на языке Java отвечает за создание Kafka-потребителя [3]:
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
// Настройки для потребителя Kafka
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "local:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Экземпляр потребителя Kafka
Consumer<String, String> consumer = new KafkaConsumer<>(properties);
// Подписка на топик Kafka
consumer.subscribe(Collections.singletonList("topic"));
// Чтение сообщений из топика
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// Обработка полученных записей
records.forEach(record -> {
System.out.printf("Получено сообщение с ключом %s и значением %s%n", record.key(), record.value());
});
}
}
}
Администрирование кластера Kafka
Администрирование Arenadata Streaming Kafka
Apache Kafka для инженеров данных
Источники
- https://itglobal.com/ru-ru/company/blog/chto-takoe-raspredelennye-vychisleniya/
- https://kafka.apache.org/documentation/#consumerconfigs
- Н.Нархид, Г.Шапира, Т.Палино. Apache Kafka. Потоковая обработка и анализ данных