Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями. CLI-интерфейс ksqldb Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня...

Как расширить возможности ksqlDB, реализовав пользовательскую функцию обработки данных, хранящихся в топиках Kafka, с помощью SQL-запросов: ликбез по UDF и практический пример. Пользовательские функции в ksqlDB для работы с данными в топиках Apache Kafka Поскольку Apache Kafka – то не просто брокер сообщений, а целая экосистема потоковой передачи событий, вокруг...
Недавно мы писали, чем Kafka Streams отличается от Consumer API. Сегодня рассмотрим, в чем разница между Kafka Streams и ksqlDB, а также разберем, почему использовать этот компонент экосистемы Apache Kafka не так просто. Как работает ksqlDB: практический пример Apache Kafka является полноценной экосистемой потоковой передачи, вокруг которой существует множество полезных...

Сегодня рассмотрим, как дата-инженеры маркетплейса Whatnot масштабировали потоковую обработку данных с помощью Apache Kafka, изменив свои ETL-процессы и реализовав на этой распределенной платформе шину событий для анализа пользовательского поведения c ksqlDB и Rockset. Постановка задачи: события пользовательского поведения в Whatnot Whatnot – это маркетплейс, пользователи которого могут покупать и продавать...
Мы уже рассматривали особенности обработки вложенных структур данных на примере парсинга JSON-файлов с Apache Spark и Hive. Развивая эту тему, сегодня поговорим про перенос записей с вложенными массивами из топиков Apache Kafka в реляционные СУБД с пользовательскими SMT-преобразователями и JDBC-коннектором: кейс для разработчиков. Проблемы обработки сложных структур данных с JDBC-коннектором...

24 января 2022 года вышел новый релиз Apache Kafka. Главные новинки самой последней на сегодня стабильной версии 3.1.0: добавленные фичи, улучшения и исправленные баги краткий обзор для разработчиков распределенных приложений Kafka Streams и администраторов кластера этой платформы потоковой передачи событий. Новинки Apache Kafka 3.1.0 для администратора кластера В свежем релизе...

3 ноября 2021 года компания Confluent, которая занимается продвижением и коммерциализацией Apache Kafka, выпустила новый релиз ksqlDB, который включает 20 исправленных ошибок и 18 добавленных фич. Самое интересное в выпуске 0.22.0: улучшенные push- и pull-запросы, а также source-потоки и таблицы. 20 исправленных багов и 18 новых фич в ksqlDB 0.22.0...

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...

В этой статье для дата-инженеров и администраторов Apache Kafka рассмотрим, зачем Confluent выпустил премиум коннектор Splunk S2S Source и как на базе этих платформ построить эффективную систему потоковой аналитики больших данных. Также читайте далее, что такое универсальный сервер рассылки Splunk и какие конфигурации коннектора позволяют автоматически создавать топик Kafka для сбора...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...
6 июня 2021 года компания Confluent, которая продвигает коммерческую версию платформы Apache Kafka, выпустила новый релиз ksqlDB. Сегодня рассмотрим самые важные исправления ошибок и новые функции ksqlDB 0.19.0, уделив особое внимание SQL-запросам соединения таблиц через JOIN по внешнему ключу. ТОП-10 исправленных ошибок в новом релизе ksqlDB Напомним, ksqlDB – это...
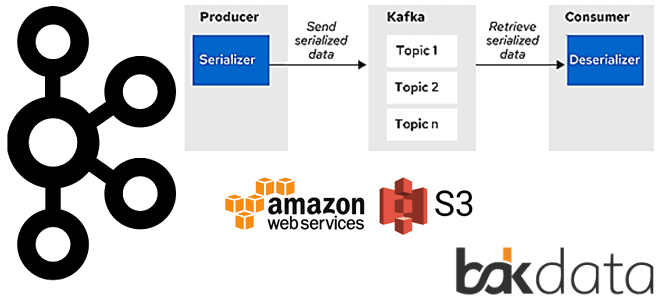
Сегодня рассмотрим проблему обработки больших сообщений в Apache Kafka Streams и способы ее решения с помощью средства сериализации и десериализации (SerDe) от немецкой ИТ-компании Bakdata. Узнайте, почему максимального лимита конфигурации max.message.bytes не хватает, зачем и как приложение Kafka Streams материализует данные, а также каким образом kafka-s3-backed-serde читает и записывает большие...
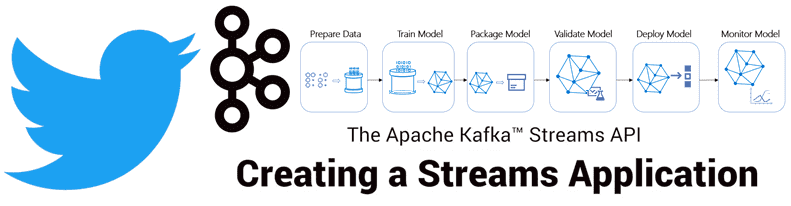
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams. Архитектура приложения...
KSQL - это движок SQL с открытым исходным кодом для Apache Kafka. Он обеспечивает простой, но мощный интерактивный SQL интерфейс для потоковой обработки на Kafka, без необходимости писать код на языке программирования, таком как Java или Python. SELECT * FROM payments-kafka-stream WHERE fraud_probability > 0.8 ...