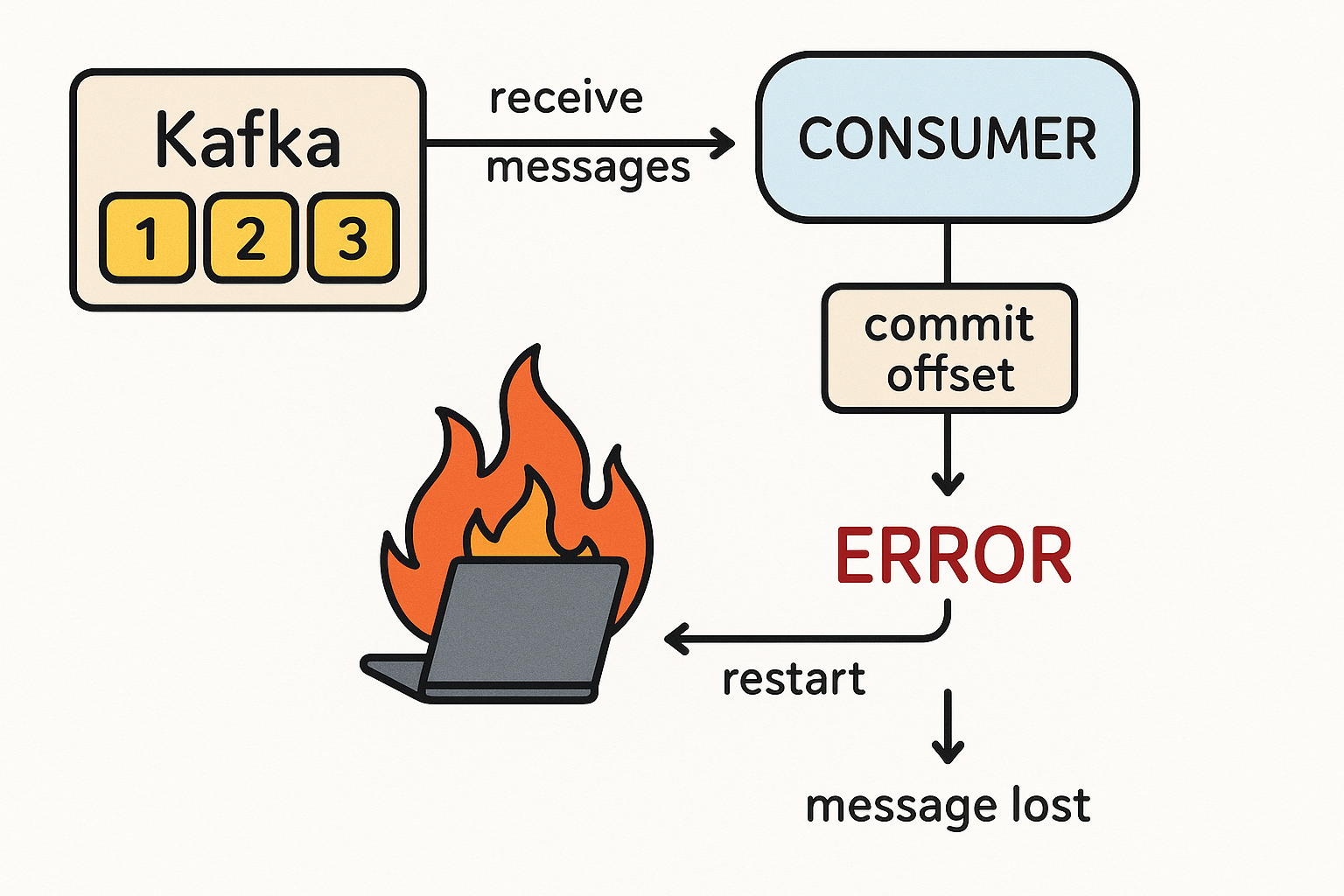
В мире распределенных систем, гарантии доставки сообщений, при передаче данных между сервисами — это фундаментальная задача. Но что происходит, когда мы отправляем сообщение из точки А в точку Б через сеть, которая по своей природе ненадежна? Сетевые задержки, сбои серверов, перезапуски приложений — все это может привести к потере или...
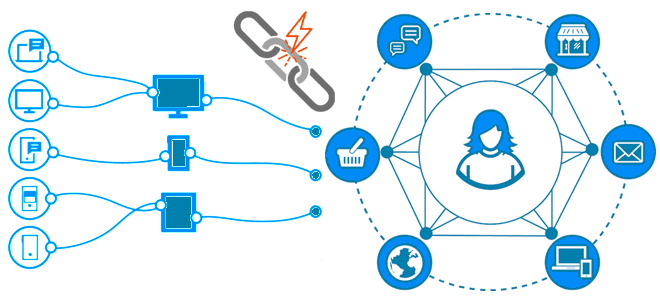
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
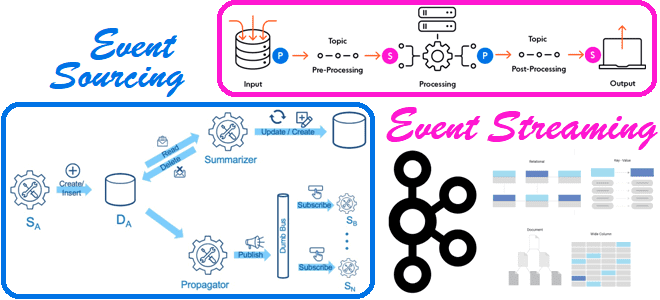
В чем разница между потоковой передачей событий и источником событий и при чем здесь Apache Kafka: разбираемся с паттернами проектирования событийно-ориентированной архитектуры. 2 паттерна проектирования EDA-архитектуры Напомним, что сегодня для построения сложных систем, зачастую состоящих из множества взаимодействующих компонентов, и реактивно реагирующих на события внешнего мира, активно используется идея архитектуры,...
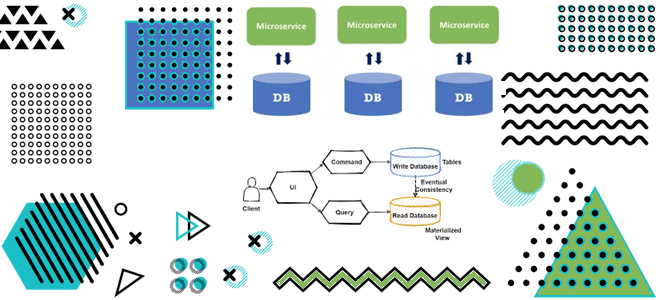
Как материализованные представления в потоковой базе данных с CDC-подходом и шаблоном CQRS позволяют реализовать масштабируемую и высокопроизводительную систему с микросервисной архитектурой для транзакций и аналитики данных в реальном времени. Разбираемся с паттернами проектирования микросервисов на примере интернет-магазина. Что не так с шаблоном композиция API и другие проблемы микросервисной архитектуры в...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...

Как быстро и эффективно с помощью Neo4j выявить преступников, незаконно ввозящих в страну контрафактные товары. Почему графовая СУБД Neo4j обошла документо-ориентированную MongoDB, из чего состоит алгоритм поиска рецидивистов средствами технологий аналитики больших данных и как это может пригодиться в других бизнес-приложениях. Постановка задачи: сложности отслеживания контрафакта Каждый день практически в...
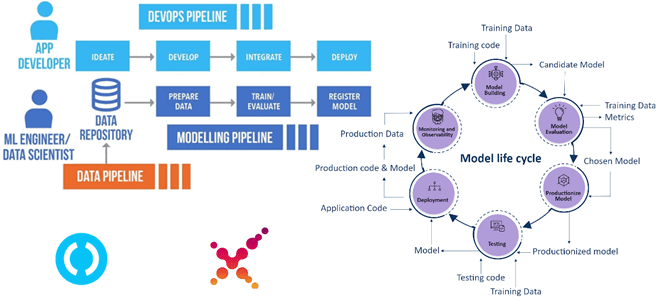
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...
Недавно мы писали про Yandex Managed Service for Apache Kafka. Продолжая тему импортозамещения, сегодня рассмотрим, как этот и другие полностью управляемые сервисы Яндекса помогли отечественному маркетплейсу KazanExpress построить эффективное BI-решение. Что такое Yandex DataLens и как он способен заменить зарубежные системы бизнес-аналитики типа Tableau с Power BI, а также открытый Apache...

Мы уже рассказывали о победителях российского ИТ-конкурса «Проект Года 2020» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», где «Газпром нефть» и банк ВТБ делятся опытом применения российских продуктов Arenadata. Сегодня рассмотрим кейс призера 2021 года - проект «Фабрика данных» в АО «Народный банк Казахстана», в результате которого...

Поскольку тема импортозамещения сейчас стала особенно актуальной, сегодня рассмотрим отечественный программно-аппаратный комплекс для хранения и аналитической обработки данных СКАЛА-Р МБД8. Что это такое, как использовать и при чем здесь продукты Arenadata. Машины больших данных СКАЛА-Р МБД8 и Arenadata Разработчиком программно-аппаратного комплекса «Машина больших данных» СКАЛА-Р МБД8 является российская компания ООО...
Сегодня обсудим ключевые тренды развития дата-инженерии и инструментальные средства их реализации. Как это применяется на практике, рассмотрим на примере эволюции хранилища данных в индонезийской ИТ-компании Bukalapak, от локального кластера Apache HBase до Лямбда-архитектуры в облаке Google Cloud Platform с Kafka, Spark и AirFlow. 7 главных драйверов развития дата-инженерии В наши...

Мы уже писали, что Apache Hadoop 3.3.1 поддерживает технологию кодирования со стиранием (Erasure Coding, EC), которая экономит место на жестком диске по сравнению с репликацией. Однако, беспечное применение этой новой фичи может обернуться настоящей катастрофой. Кейс соцсети «Одноклассники» от ведущего разработчика Дениса Ефарова, представленный на конференции Smart Data для инженеров данных в...
Недавно мы писали про пользу snapshot’ов Apache HBase на примере компании Vimeo. Сегодня рассмотрим кейс корпорации Box, которая специализируется на облачных enterprise-продуктах совместного управления контентом и файлами. Переход от локальной HBase к Google Cloud BigTable: сложности миграции и способы их обхода. Сходства и различия Apache HBase с Google Cloud BigTable...
В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka. Проблема микросервисов при множестве обращений...

Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию...

Развивая наши курсы для дата-инженеров по Apache AirFlow, сегодня рассмотрим, как автоматизировать развертывание сложных DAG’ов с помощью Docker и Kubernetes на примере управления конвейерами обработки данных. Лучшие практики и советы от инженеров данных DataOps-компании Databand. 4 вопроса дата-инженера к production-развертыванию конвейеров Apache Airflow Apache AirFlow считается одним из самых популярных...

Сегодня рассмотрим, как индийская ИТ-компания Razorpay с помощью Apache Flink и Kafka свела к минимуму время простоя своего главного продукта - платежного шлюза для интернет-магазинов. Как всего 2 задания Flink могут быстро обнаруживать простои более 50 когорт событий на уровне платежного шлюза и 200+ когорт разных интернет-магазинов. Работать нельзя остановиться:...
Добавляя в наши курсы для дата-инженеров еще больше полезных примеров, сегодня рассмотрим, как Airbnb развивает Apache AirFlow и на практике используют эту платформу для создания, планирования и мониторинга конвейеров данных. Что такое Smart Sensor и как умные датчики экономят ресурсы на выполнение долгосрочных легковесных задач. Легкие, долгие и ресурсоемкие: проблемы...

Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим пример анализа данных о путешествиях средствами графовой СУБД Neo4j и ее языка запросов Cypher. Читайте далее, где взять данные о путешествиях цифровых кочевников и как определить самое популярное направление. Цифровые кочевники и графы их путешествий Хотя...