
Мы построили пайплайн, где данные забираются из базы и бережно складываются в HDFS. Теперь они лежат там мертвым грузом. Чтобы превратить сырые CSV в полезные отчеты, их нужно обработать: отфильтровать, агрегировать, джойнить. Делать это внутри самого Airflow (через PythonOperator и Pandas) - плохая идея если: Память: Если файл весит...

В поддержку нашего нового курса для дата-инженеров Школа Больших Данных проводит очередной бесплатный митап для аналитиков, архитекторов, инженеров данных, разработчиков, DataOps- инженеров и тех, кто интересуется современными технологиями обработки данных. Trino – это распределенный SQL-движок с массово-параллельной архитектурой и открытым исходным кодом. Он предназначен для работы с большими объемами данных в...
Почему можно программировать на Python для разработки JVM-приложений: как Java-фреймворки с Python API, такие как Apache Spark и Flink, транслируют Python-код, организуя межпроцессное взаимодействие. Способы трансляции Python-кода для исполнения в JVM Большинство фреймворков для разработки высоконагруженных приложений написаны на Java. Например, Apache Spark или Flink. При этом они предоставляют Python...
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...

Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения. Расширение стратегий развертывания в Kubernetes с Argo Rollouts Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows -...
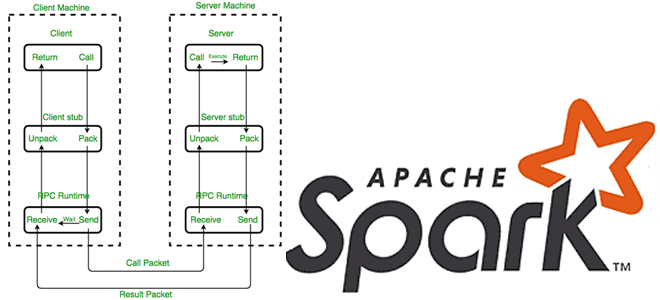
Как Apache Spark использует протокол удаленного вызова процедур для межпроцессного взаимодействия, какие параметры отвечают за эффективное выполнение RPC-запросов и где их настроить. RPC в Apache Spark Распределенный характер Apache Spark предполагает взаимодействие между компонентами, расположенными на разных узлах, например, драйвер на мастер-узле взаимодействует с исполнителями на рабочих узлах. В качестве...
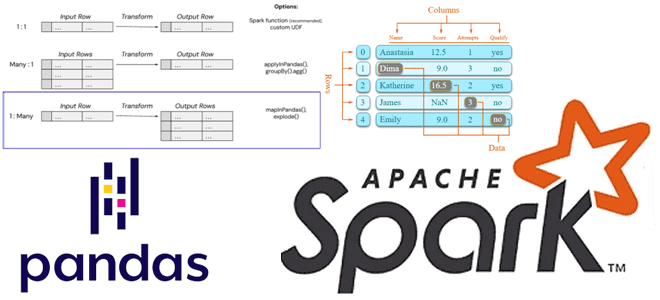
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...

Чем метод applyInPandas() в Spark отличается от apply() в pandas и насколько он быстрее обрабатывает данные: сравнительный тест на датафрейме из 5 миллионов строк. Методы применения пользовательских функций к датафреймам в Spark и pandas Мы уже отмечали здесь и здесь, что Apache Spark позволяет работать с популярной Python-библиотекой pandas, поддерживая...

Зачем включать ротацию лог-файлов потоковых приложений Apache Spark, какие конфигурации помогут ее настроить и для чего сжимать файлы журналов в длительных заданиях. Чем полезна ротация лог-файлов Spark-приложений и как ее настроить Об общих принципах логирования системных событий в приложениях Apache Spark мы уже рассказывали здесь. В этой статье подробнее разберем...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...
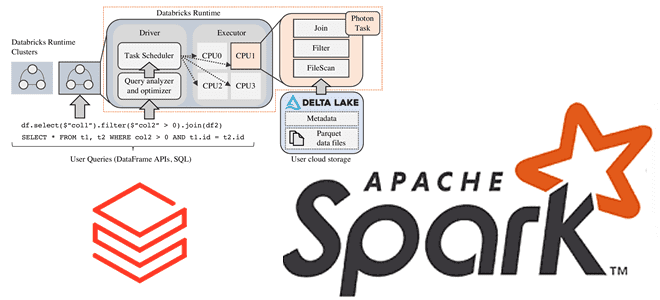
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...

Школа Больших Данных проводит еще один бесплатный митап для архитекторов платформ данных, инженеров данных, разработчиков, DevOps-, DataOps-инженеров и просто интересующихся о модели Dataflow, API Apache Beam, а также паттернах управления приложениями распределенной обработки данных на Kubernetes. Apache Beam – унифицированный API с открытым исходным кодом, реализующий модель Dataflow, предоставляет единый...

Школа Больших Данных проводит очередной бесплатный митап для архитекторов платформ данных, инженеров данных, разработчиков, DevOps-, DataOps-инженеров и просто интересующихся о моделях и ключевых паттернах управления распределенными приложениями Apache Spark и Apache Flink на Kubernetes. Apache Spark и Flink - это популярные Big Data фреймворки с открытым исходным кодом для распределённой...
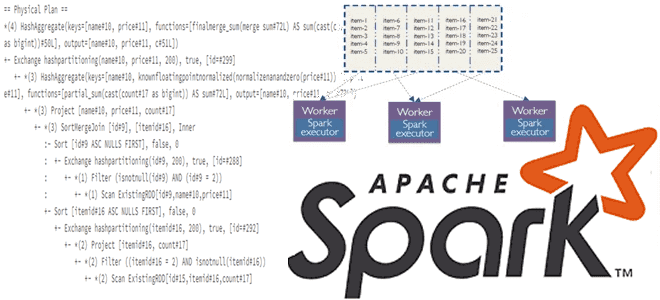
Что такое Dynamic Partition Pruning в Spark SQL, как работает этот метод оптимизации пакетных запросов, зачем его использовать в задачах аналитики больших данных, и каким образом повысить эффективность его практического применения. Что такое Dynamic Partition Pruning и зачем это нужно в Spark SQL Параллельная обработка данных в Apache Spark обеспечивается...
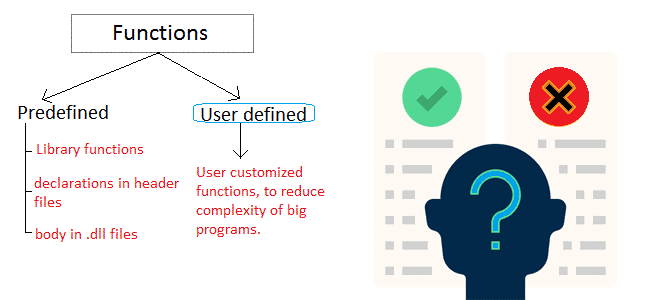
Почему пользовательские функции лучше применять как можно реже, каковы их возможности и ограничения: краткий обзор особенностей разработки и эксплуатации UDF в Apache Spark SQL, ksqlDB, Flink SQL, Greenplum и ClickHouse. Чем полезны и опасны пользовательские функции в обработке больших данных? Пользовательские функции (User-Defined Functions, UDF) позволяют разработчику расширить возможности фреймворка,...

Как устроен потоковый запрос Spark Structured Streaming на уровне кода: интерфейсы, их методы и как их настроить, создание и запуск StreamingQuery. Создание потокового запроса в Spark Structured Streaming Хотя структурированная потоковая передача Spark основана на SQL-движке этого фреймворка, в ней гораздо больше сложных абстракций. Например, с точки зрения программирования потоковый...
Почему параллельное выполнение заданий в Apache Spark зависит от языка программирования и как можно обойти однопоточную природу Python в PySpark. Что не так с параллельным выполнением заданий PySpark и как это исправить? Apache Spark позволяет писать распределенные приложения благодаря инструментам для распределения ресурсов между вычислительными процессами. В режиме кластера каждое...

Как размер пакета, режим вывода и интервал срабатывания триггера потоковой обработки влияют на скорость вычислений в приложении Apache Spark Structured Streaming и как настроить эти параметры. Размер пакета при потоковой обработке данных в Spark Streaming Хотя скорость обработки данных средствами Apache Spark Streaming зависит от многих факторов, включая саму структуру...
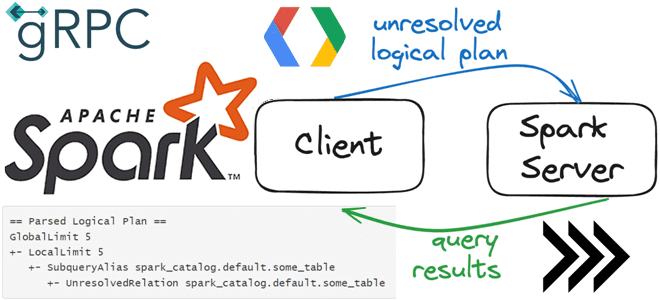
Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения. Как работает Spark Connect О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться...