
Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...

Сегодня рассмотрим новое унифицированное решение для хранения потоковых и пакетных таблиц, созданное на основе Apache Spark. Что такое Lakesoul, чем это лучше Apache Iceberg, Hudi и Deta Lake. Также разберем, в чем конкурентные преимущества этого табличного хранилища по сравнению с этими форматами открытых таблиц, включая поддержку upsert, управление метаданными и...
Специально для обучения дата-инженеров и архитекторов DWH сегодня разберем, как построить LakeHouse на Greenplum и объектном хранилище Cloudian HyperStore, совместимом с AWS S3. Что такое Cloudian HyperStore Object Storage, как оно совмещается с Greenplum и при чем здесь Apache Cassandra с интеграционным фреймворком PXF. Что такое объектное хранилище Cloudian HyperStore...

В этой статье для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных разберем пример перевода сервиса Strava с кластера Cassandra в облачное хранилище AWS S3 и какую роль в этом сыграл вычислительный движок Apache Spark. Постановка задачи: слишком дорогая Cassandra Strava – это глобальный сервис отслеживания активности велосипедистов, бегунов...

Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка. Постановка задачи на примере IoT-системы Несмотря на...

Сегодня рассмотрим, как Uber эффективно обрабатывает миллионы запросов на поездки c помощью технологий надежного хранения и быстрой аналитики больших данных. Вас ждет краткий ликбез по системе геопространственной индексации H3 и рассказ о том, почему компания заменила NoSQL-Cassandra c компонентом Saga интеграционного фреймворка Camel на геораспределенную облачную NewSQL-СУБД Spanner от Google....

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое DataStax Enterprise Graph. Читайте далее, как немецкая ИТ-компания Traversals с помощью этой распределенной графовой СУБД построила масштабное аналитическое решение для кибербезопасности, обнаружения мошенничества, анализа конкурентов и оповещения клиентов в реальном времени. Также разберем, при...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...
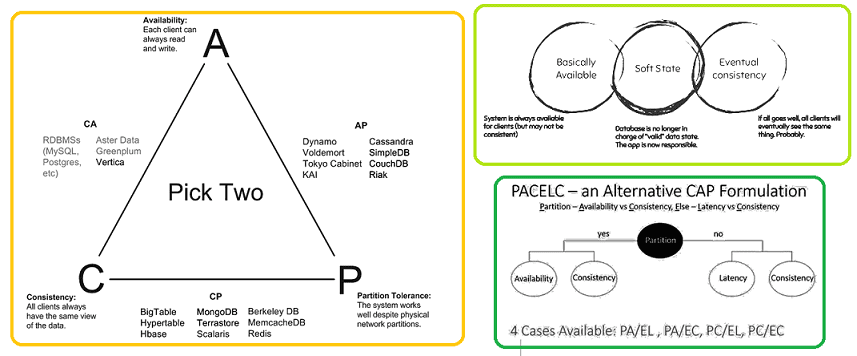
В этой статье мы расскажем про краеугольный камень распределенных Big Data систем – CAP-теорему, в которой одновременно возможно реализовать только 2 свойства из 3-х, по аналогии с треугольником ограничений в проектном менеджменте «Быстро-Качественно-Дешево». Также рассмотрим, за что критикуют модель CAP и почему современные NoSQL-СУБД стоит рассматривать с позиций BASE и...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...
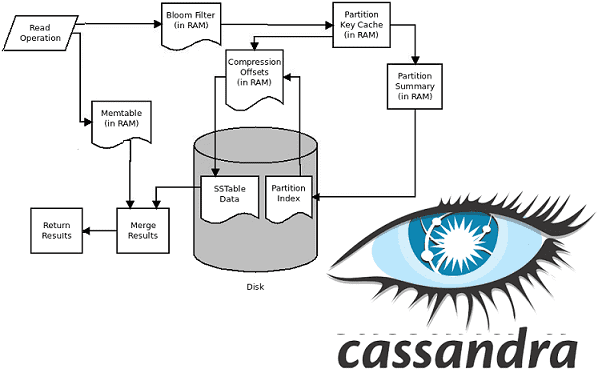
В прошлой статье мы разобрали, как настраиваемые уровни согласованности влияют на скорость работы с данными в Apache Cassandra. Сегодня поговорим, как в этой нереляционной базе данных выполняются операции записи, чтения, уплотнения и удаления. Читайте в нашей статье, что такое memTable, SSTable и Bloom-фильтр, благодаря которым рассматриваемая распределенная NoSQL-СУБД может обработать...
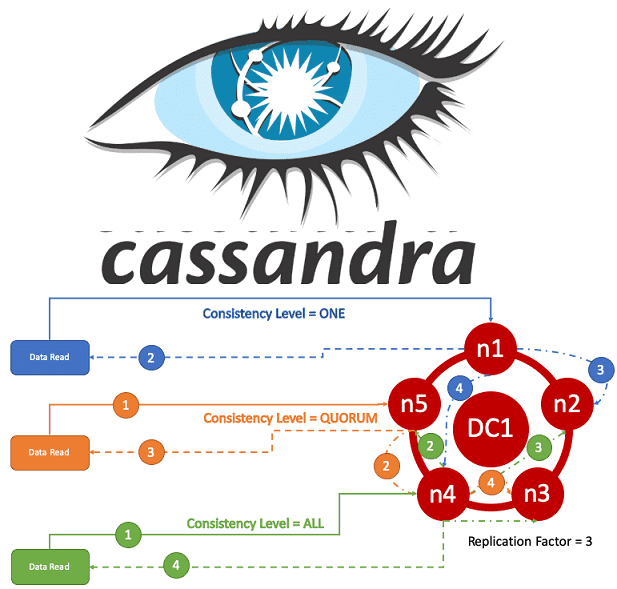
Как мы уже отмечали, одним из преимуществ Кассандры является возможность задания уровня согласованности для операций чтения и записи данных. В этой статье рассмотрим, какие бывают уровни согласованности для этих процессов в Apache Cassandra, и как они влияют на скорость работы распределенной NoSQL-СУБД при ее эксплуатации в реальных Big Data проектах....

Продолжая тему нереляционных хранилищ данных, сегодня мы поговорим о главных плюсах и минусах Apache Cassandra. Читайте в нашем материале, чем хороша эта отказоустойчивая распределенная NoSQL-СУБД и с какими проблемами можно столкнуться при ее использовании в реальном Big Data проекте. Чем хороша Кассандра: 10 ключевых преимуществ Начнем с положительных моментов. Благодаря...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...