Почему репортеры мониторинга системных метрик Flink, отправляющие данные в Prometheus, не решают проблемы предварительной обработки измерений с IoT-устройств, и как новый коннектор расширяет сферу применения фреймворка потоковой обработки. Встроенные средства мониторинга системных метрик Flink В декабре 2024 года вышел новый коннектор Apache Flink к Prometheus – популярной базе данных временных...
Чем базы данных временных рядов отличаются от реляционных и key-value хранилищ, какова модель данных для хранения метрик, значения которых меняются во времени, какие решения этой категории NoSQL-СУБД сегодня популярны на рынке и для чего они используются. Что такое база данных временных рядов и где она используется Как и следует из...
В прошлой статье про обновление Apache NiFi мы писали, что в новой версии 1.18.0 улучшено взаимодействие с протоколом MQTT, который активно используется в системах интернета вещей. Сегодня разберем более подробно, как наладить сбор и публикацию данных в MQTT-топики с помощью процессоров Apache NiFi, а также разберем, что такое брокер HiveMQ....

Сегодня рассмотрим опыт международной компании Emumba, которая специализируется на инженерии и аналитике больших данных. Читайте далее, как выгодно масштабировать конвейер потоковой передачи данных от миллионов устройств интернета вещей, используя Apache Kafka, KStream и Druid в облачной инфраструктуре AWS. Архитектура PoC для потоковой передачи событий от миллионов IoT-устройств Миллионы устройств интернета...

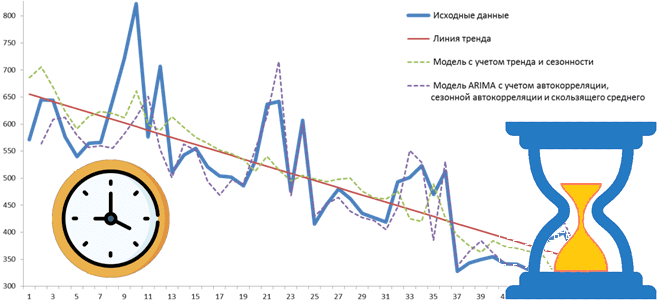
В этой статье для дата-инженеров и аналитиков рассмотрим пример мониторинга состояния электрогенераторов с помощью анализа данных временных рядов и ранжирования в pandas для предупреждения выхода оборудования из строя. А также разберем основы анализа временных рядов на больших данных с открытой библиотекой Flint для Apache Spark. Постановка задачи: температура и производительность...

Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка. Постановка задачи на примере IoT-системы Несмотря на...

Сегодня поговорим про совместное использование Apache NiFi с его легковесным агентом – MiNiFi. Преимущества для ETL-процессов в IoT-системах и не только, ограничения практического применения, а также пример контейнеризации и выполнения Docker-образа на Raspberry PI4 ARM64. Internet of Things и Apache NiFi на периферии Интернет вещей (Internet of Things, IoT) приводит...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...
Завершая серию статей по IoT-платформе компании Tesla на базе Apache Kafka, сегодня рассмотрим проблемы пиковой загрузки системы и особенности обработки высокоприоритетных событий. Читайте далее, как оптимально определить ключ раздела, чтобы снизить затраты на передачу данных, избежать перегрузки в пиковые моменты и отделить пользователей данных от разработчиков и дата-инженеров. Тонкости обработки...

Мы уже упоминали, что Apache Kafka не слишком хорошо обрабатывает сообщения чрезмерно большого размера. Сегодня рассмотрим, как эта проблема решается в конвейерах потоковой обработки IoT-инфраструктуры Tesla. Читайте далее про модификацию синтаксического анализатора данных от множества устройств интернета вещей с поиском компромисса между скоростью и надежностью с помощью коннектора Alpakka к...
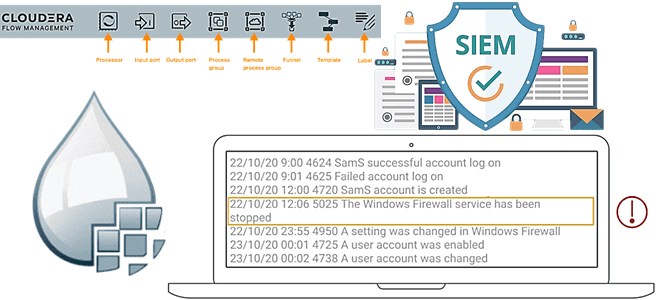
В этой статье для дата-инженеров рассмотрим, что такое Cloudera Flow Management и как это позволяет ускорить аналитику больших данных в кейсах информационной безопасности. Читайте далее о преимуществах SIEM-анализа, преобразования и распределения security-событий с помощью Apache NiFi и его легковесного агента MiNiFi для устройств интернета вещей (Internet Of Things, IoT). Что...

Продолжая разбирать кейс компании Tesla по организации централизованного управления устройствами интернета вещей (Internet of Things, IoT), сегодня разберем, как выполняется обработка сообщений в топиках Apache Kafka с помощью Confluent Schema Registry и Kafka Streams. Читайте далее, как определить потоковый процессор для парсинга данных в CSV и JSON-форматах с использованием схемы...

Являясь лидером отрасли, IoT-устройства Tesla обрабатывают триллионы событий в день, чтобы повысить эффективность своих электроавтомобилей. Однако, такая производительность была получена не сразу: чтобы достичь ее, инженерам компании пришлось решить множество проблем из области интернета вещей (Internet of Things, IoT). Сегодня рассмотрим, как часть из них была решена с помощью Apache...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...

Вчера мы говорили про наиболее перспективные технологии 2020 с точки зрения исследовательского агентства Gartner и их влияние на цифровую трансформацию. Сегодня продолжим разбирать современные тенденции изменения рабочего пространства с учетом эпидемиологической напряженности и тренда на дистанционное взаимодействие. Читайте далее, что такое Desktop as a Service, как выглядит интеллектуальное рабочее пространство,...

В этой статье рассмотрим, как технологии Industry 4.0 помогают российскому нефтехимическому холдингу СИБУР повысить операционную эффективность производства и обеспечить безопасность труда. Сегодня мы собрали для вас 5 примеров практического использования различных методов и инструментов Big Data, Machine Learning, Industrial Internet of Things (IIoT), а также XR (AR+VR). Зачем нефтехимикам технологии...

В продолжение темы про озера данных (Data Lake) и Apache Hadoop, сегодня мы рассмотрим еще 3 примера использования этих технологий Big Data для аналитики больших данных в промышленности. Читайте в нашей статье, как косметический гигант L’Oréal создает новые продукты с помощью платформы Talend Data Fabric, «УРАЛХИМ» прогнозирует объемы продукции и...

Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB. IoT и не...

В этой статье мы рассмотрим резидентные (In-Memory) базы данных на примере Tarantool и Arenadata Grid: что это, как они работают и где используются. Еще поговорим, каким образом эти Big Data системы могут ускорить работу распределенных приложений без замены существующих СУБД, а также при чем здесь промышленный интернет вещей и экосистема...