
Чем Apache Beam отличается от Apache Flink, что и когда выбирать, зачем их совмещать для реализации сложных конвейеров обработки больших объемов данных с помощью распределенных stateful-приложений, и как это работает. Сходства и отличия Apache Beam и Flink Хотя Apache Beam является унифицированной моделью определения пакетных и потоковых конвейеров параллельной обработки данных,...
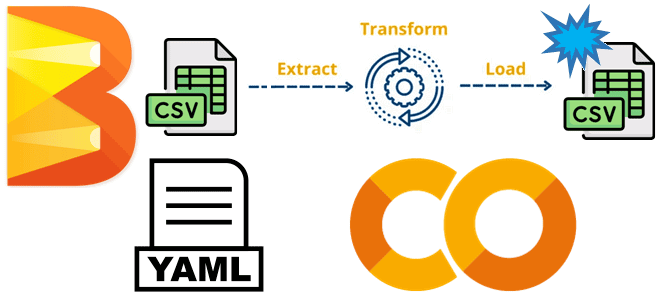
Как написать конвейер обработки данных Apache Beam, задав цепочку преобразований в YAML-конфигурации: практический пример фильтрации и агрегации платежей из CSV-файла. Пример разработки и запуска YAML-конвейера Apache Beam в Google Colab Недавно я рассказывала про Apache Beam – унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить...
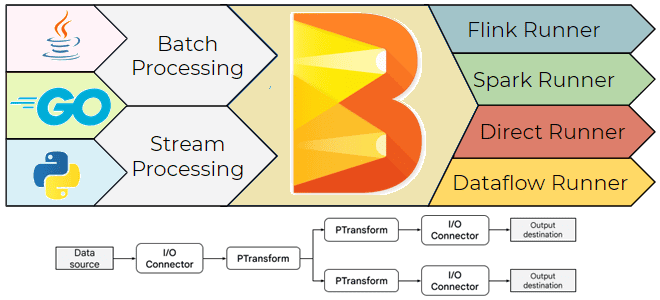
Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных. Что такое Apache Beam и зачем он нужен Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения...

Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения. Расширение стратегий развертывания в Kubernetes с Argo Rollouts Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows -...
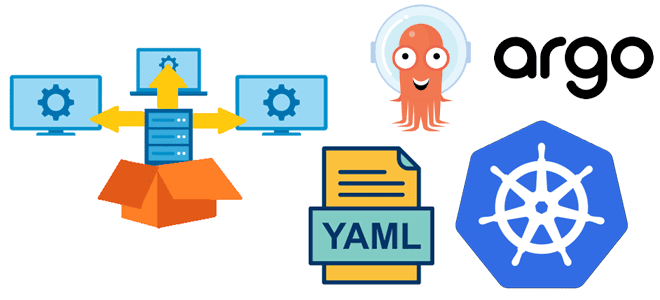
В чем сложности оркестрации параллельных заданий в Kubernetes и как их решить с помощью Argo Workflows: обзор фреймворка и практический пример YAML-спецификации шаблона рабочего процесса для развертывания веб-приложения. Что такое Argo Workflows и зачем он нужен Оркестрация параллельных заданий на платформе Kubernetes довольно сложна из-за их внутренних зависимостей друг от...

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
Почему DevOps-подходы не так просто внедрить в инженерию данных, что не так с реестром Apache NiFi и зачем расширять набор инструментов Toolkit собственным Java-приложением для автоматизированной миграции потоковых конвейеров в разные среды развертывания. Что не так с реестром Apache NiFi с точки зрения DevOps-инженера Изначально Apache NiFi был создан как...
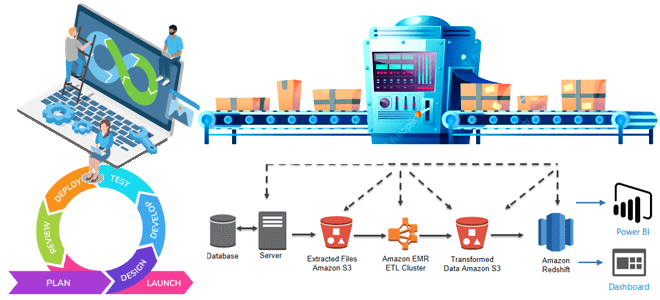
Чем инженерия данных отличается от разработки ПО, как организовать оркестрацию конвейеров обработки данных и внедрить лучшие практики CI/CD. Почему дата-инженерия отличается от разработки ПО При том, что между инженерией данных и разработкой программного обеспечения (ПО) очень много общего, эти ИТ-дисциплины довольно сильно отличаются. Хотя в обоих направлениях используется облачная инфраструктура,...

Сегодня рассмотрим, как развернуть модель машинного обучения в конвейере Apache Kafka, используя потоковый API технологии удаленного вызова процедур от Google под названием gRPC и сервер ML-моделей TensorFlow Serving. Краткий ликбез по gRPC Напомним, gRPC – это технология интеграции систем, включая клиентский и серверный компоненты, основанная на удаленном вызове процедур в...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...

Мы уже делали краткий обзор некоторых исполнителей задач Apache AirFlow. Сегодня рассмотрим более подробно механизмы запуска удаленных задач и разберемся, чем Celery Executor отличается от CeleryKubernetes Executor и как они работают. Виды и назначение исполнителей Apache AirFlow Напомним, Apache AirFlow состоит из нескольких компонентов: Веб-сервер, предоставляющий GUI для настройки DAG...

Как MLOps-инженеры платформы онлайн-курсов Udemy ускорили цикл разработки и внедрения проектов машинного обучения, используя возможности Amazon SageMaker для создания и отладки Spark-приложений в удаленном облачном кластере. MLOps на AWS Чтобы воспользоваться преимуществами бесшовной интеграции процессов разработки и развертывания машинного обучения согласно концепции MLOps, совсем не обязательно выстраивать собственную платформу из...

Что общего у FastAPI с BentoML, чем они отличаются и почему только один из них является полноценным MLOps-инструментом. Смотрим на примере операций разработки и развертывания API сервисов машинного обучения. Что общего у FastAPI с BentoML и при чем здесь MLOps С точки зрения промышленной эксплуатации, в проектах машинного обучения следует...
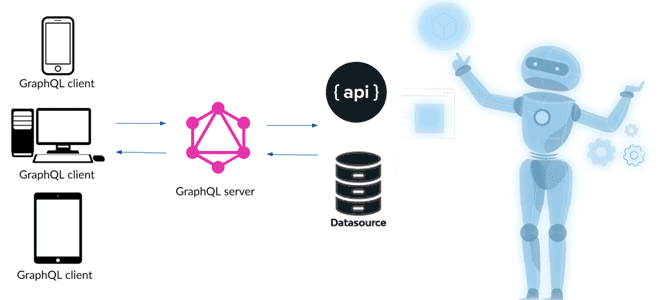
Недавно мы упоминали GraphQL как мощный и гибкий язык запросов к данным, хранящимся в графовых СУБД. Сегодня рассмотрим, чем эта технология может быть полезна в проектах Machine Learning, какие сложности с ней связаны и как их решить с помощью MLOps. GraphQL для ML: возможности и примеры Не будучи в чистом...
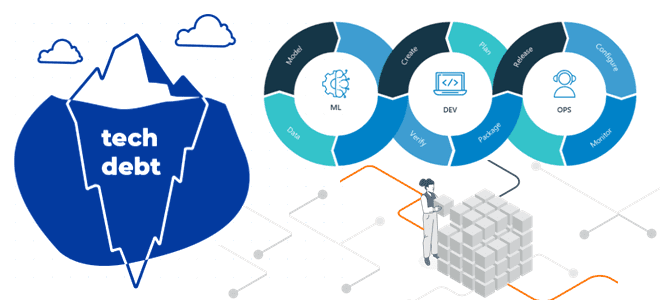
Почему в проектах машинного обучения накапливается технический долг, каковы главные факторы его появления и каким образом MLOps устраняет проблемы, связанные с разработкой, тестированием, развертыванием и сопровождением систем Machine Learning. Скрытый технический долг в ML-системах Технический долг означает дополнительные затраты, возникающие в долгосрочной перспективе, с которыми сталкивается команда, в результате выбора...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...
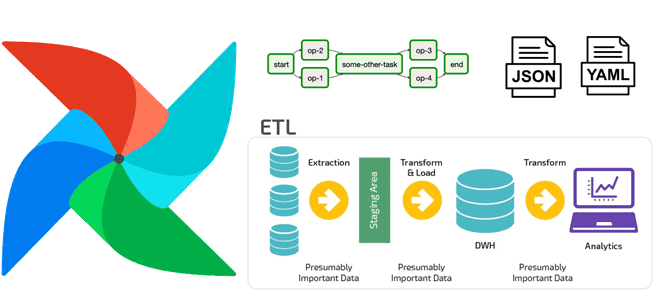
Дата-инженеры часто сталкиваются с изменением структуры конвейера обработки данных в Apache AirFlow, например, когда добавляются новые источники или приемники данных. Однако, менять DAG каждый раз при изменении внешних условий довольно утомительно. Читайте далее, как автоматизировать реорганизацию DAG, используя JSON, YAML-файл или другую плоскую структуру данных для хранения динамической конфигурации рабочего...

В этой статье для обучения дата-инженеров и администраторов кластера Apache AirFlow рассмотрим, как обновить этот ETL-планировщик, используя концепцию сине-зеленого развертывания. Также рассмотрим, с какими ошибками можно столкнуться, выполняя миграцию базы данных метаданных и как их решить. Сине-зеленое развертывание для обновления AirFlow Как и любое программное обеспечение, Apache AirFlow нужно периодически...
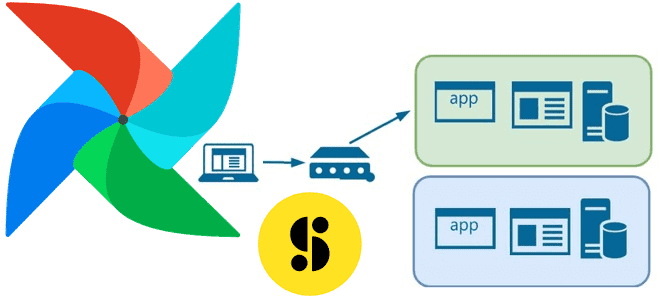
В этой статье для обучения дата-инженеров рассмотрим, как крупнейший медиа-банк Storyblocks добился обновления данных в корпоративном хранилище без простоев с помощью DevOps-идеи сине-зеленого развертывания и механизма TaskGroup в Apache Airflow. Проблемы ETL при массовой загрузке данных в Data Lake и DWH Storyblocks – это крупнейший в мире банк данных, включающий...
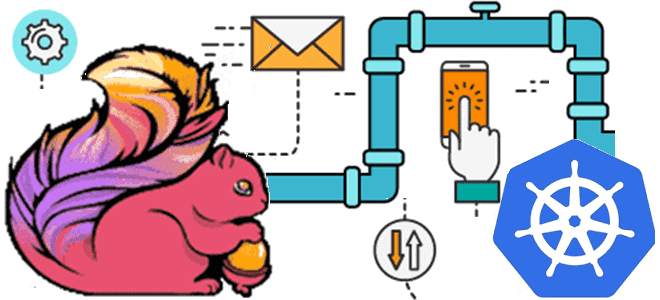
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...