
Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...

В рамках обучения разработчиков распределенных Spark-приложений, сегодня рассмотрим, как добавить функции из пользовательских JAR-файлов в кластер AWS EMR. Достоинства и недостатки действия начальной загрузки EMR с переопределением конфигурации Spark, а также расширенное управление зависимостями через spark-submit. Трудности обращения к пользовательским JAR в Amazon EMR с Apache Spark и Livy На...

Сегодня разберем типовые ошибки, которые часто возникают в системах аналитики больших данных на базе Apache Hadoop YARN, Spark и RESTful-интерфейсу Livy, а также каким образом их избежать. В качестве практического примера используем ранее рассмотренный кейс интерактивной аналитики о пользовательском поведении в фотохостинге Pinterest. Интерактивная аналитика больших данных в Pinterest Недавно...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...

Сегодня рассмотрим инструмент, который облегчает практическое использование Apache Spark, позволяя дата-аналитику и разработчику распределенных приложений быстро писать и выполнять SQL-запросы в рамках удобного веб-редактора. Читайте далее, что такое Hue, как он связан со Spark SQL и Hive, а также причем здесь Livy. Что Hue и при чем здесь Apache Livy...

Дополняя наши курсы дата-инженеров полезными примерами, сегодня рассмотрим, как упростить разработку и мониторинг ETL-конвейеров с помощью дополнительных технологий Big Data, совместимых с Apache Spark. Читайте далее, когда и зачем инженеру данных пригодятся SaaS-продукт Prophecy.io, движок StreamSets Transformer и REST-интерфейс Apache Livy, а также как все они связаны со Spark. 3...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
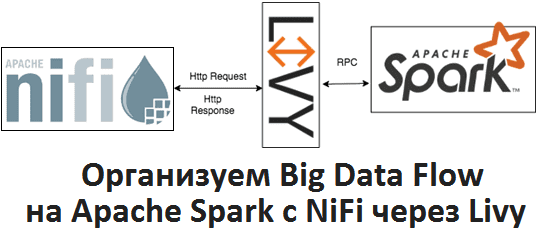
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...