
Оркестратор сам по себе бесполезен. Apache Airflow - это дирижер, а не музыкант. Его задача - не хранить данные и не (всегда) обрабатывать их, а говорить другим системам, что делать. "Postgres, выполни этот запрос", "Spark, посчитай эту витрину", "S3, отдай файл". Но чтобы сказать "Postgres, выполни запрос", Airflow должен...
Зачем нужен каталог метаданных и как он работает: построение платформы данных и управление метаданными по DAMA DMBOK. Unity Catalog и другие решения для учета источников данных и непрерывного обеспечения их актуальности. Управление метаданными по DMBOK Методологически создание и внедрение платформ данных основано на положениях DAMA DMBOK – своде знаний по...

Что общего у ClickHouse и StarRocks, чем они отличаются, и что выбирать для аналитики больших данных в реальном времени: сравнение колоночных OLAP-СУБД с векторным движком. Чем похожи ClickHouse и StarRocks: 7 главных сходств Хотя ClickHouse сегодня считается одной из наиболее популярных СУБД для аналитики больших данных в реальном времени с...

Что общего у StarRocks с Trino, чем они отличаются, когда и что выбирать для практического использования: сравниваем движки для быстрой аналитики больших данных из Data Lake. Чем похожи StarRocks и Trino Вчера мы разбирали, что такое StarRocks, как устроена и где пригодится эта высокопроизводительная аналитическая база данных с открытым исходным...

Вместо Trino и ClickHouse: что такое StarRocks и как оно устроено, архитектура и принципы работы, сценарии использования и место в корпоративной архитектуре данных. Архитектура и принципы работы StarRocks Хотя ClickHouse сегодня считается одним из наиболее популярных колоночных хранилищ для аналитики больших объемов данных в реальном времени, это не единственный представитель...

22 апреля 2025 вышел долгожданный крупный релиз Apache Airflow. Знакомимся с главными новинками версии 3.0: изменения архитектуры и пользовательского интерфейса для повышения устойчивости и безопасности фреймворка. Еще раз про версионирование DAG в Apache AirFlow 3.0 Недавно мы писали про бета-релиз Apache AirFlow 3.0. Теперь мажорная версия вышла официально и доступна...
Как сократить затраты на хранение исторических данных в ClickHouse для ИИ-сценариев, сохранив высокую скорость аналитики по широким таблицам и озеру данных: эволюция колоночной СУБД в новом проекте с исходным кодом Antalya от Altinity. Проблемы совмещения ClickHouse с озерами данных и способы их решения Благодаря колоночной структуре хранения данных ClickHouse не...

Что такое Apache Wayang, чем он похож на Beam и в чем разница с Trino: архитектура и принципы работы еще одного распределенного фреймворка интеграции данных. Что такое Apache Wayang и чем это отличается от Trino Trino – это мощный, но далеко не единственный инструмент распределенного выполнения аналитических запросов, способный обрабатывать...

Как LLM упрощают работу дата-инженера: новые декораторы TaskFlow API в Apache Airflow для внедрения больших языковых моделей в DAG. Обзор Airflow AI SDK на основе Pydantic AI с практическим примером про анализ отзывов. ИИ в инженерии данных Мультимодальность современных инструментов машинного обучения, когда одна ML-модель может принимать на вход данные...
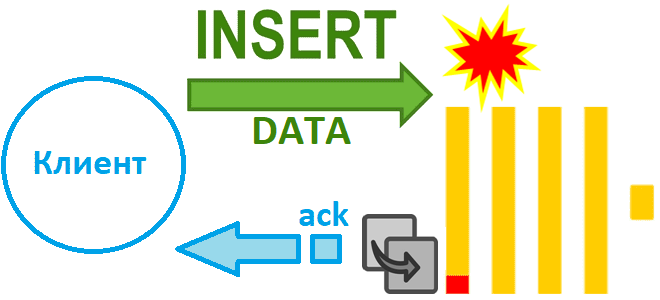
Как избежать потери данных при асинхронной вставке в Clickhouse при сбое сервера и зачем в версию 24.2 добавлен адаптивный тайм-аут очистки буфера: тонкости ETL с колоночной СУБД. Асинхронная вставка с возвратом подтверждения Недавно мы рассказали, чем хороши асинхронные вставки в ClickHouse и отметили, что при их использовании можно настроить параметр...
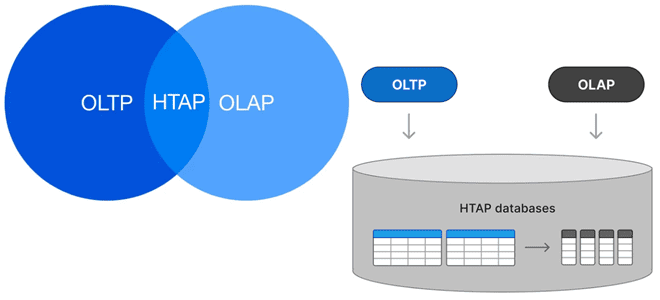
Можно ли сочетать OLAP и OLTP-нагрузки в едином хранилище и как это сделать: гибридная транзакционно-аналитическая обработка в базах данных, возможности и проблемы этой архитектуры. Что такое HTAP Исторически хранилища данных принято делить на OLAP и OLTP с учетом их оптимизации для аналитических и транзакционных нагрузок. OLTP-системы (Online Transaction Processing) оптимизированы...
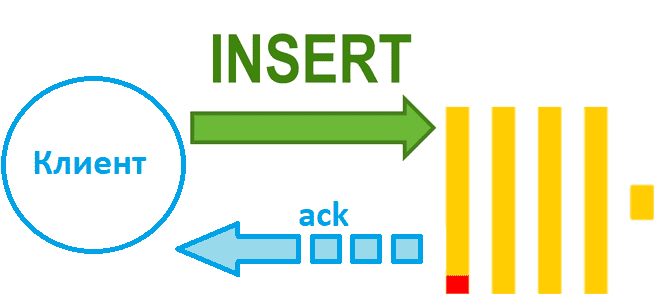
Чем синхронная вставка в ClickHouse отличается от асинхронной и как это настроить: лучшие практики и риски загрузки данных в колоночное хранилище. Синхронная вставка данных в ClickHouse Хотя скорость вставки данных в ClickHouse зависит от множества факторов, ее можно ускорить за счет асинхронных вставок, если предварительное пакетирование на стороне клиента невозможно....
Как именно формат, сортировка, сжатие и интерфейс передачи данных в ClickHouse влияют на скорость операций загрузки: бенчмаркинговое сравнение от разработчиков колоночной СУБД. В каком формате данные быстрее всего вставляются в ClickHouse Продолжая недавний разговор про вставку данных в ClickHouse, сегодня рассмотрим, ключевые факторы, которые особенно сильно влияют на скорость загрузки...

Почему в одной организации возникает рассогласование данных, чем опасна такая рассинхронизация, как ее обнаружить и устранить: подходы и решения для повышения качества данных. Что такое data silos и как найти локальные «болота данных» Рассогласование в данных возникает при разной логике обработки одной и той же информации. Это мешает принимать объективные...

Как выполняется вставка данных в ClickHouse, от чего зависит ее скорость и каким образом ее повысить: последовательность операций загрузки и ее оптимизации. От чего зависит скорость вставки данных в ClickHouse Поскольку ClickHouse часто используется для построения хранилищ или витрин данных, скорость загрузки данных в эту базу очень важна. Хотя на...
Пишем собственный плагин Trino для работы с пользовательским типом данных: практический пример создания и регистрации своих классов и pom-файла. Пример реализации своего плагина Trino О том, что гибкость Trino обеспечивается благодаря его плагинной архитектуре, я недавно писала здесь. Сегодня рассмотрим пример создания своего плагина, который реализует возможность работы с пользовательским...
Почему Trino такой гибкий: плагинная архитектура SQL-движка, зависимости SPI-интерфейса и последовательность создания пользовательского плагина. Плагинная архитектура Trino и как она работает Благодаря настраиваемым коннекторам Trino может подключаться к любым источникам, от реляционных баз данных до NoSQL-хранилищ. При этом коннекторы – это частный случай плагина. С точки зрения проектирования ПО, Trino...

Изоляция рабочих процессов и универсальное выполнение на удаленных машинах в обновленной клиент-серверной архитектуре, версионирование DAG, активы данных и изменения интерфейсов: главные новинки Apache AirFlow 3.0. Изоляция рабочих процессов и универсальное выполнение В марте 2025 года ожидается выпуск бета-релиза Apache AirFlow, а общедоступная версия (GA) выйдет в середине апреля. До этого...
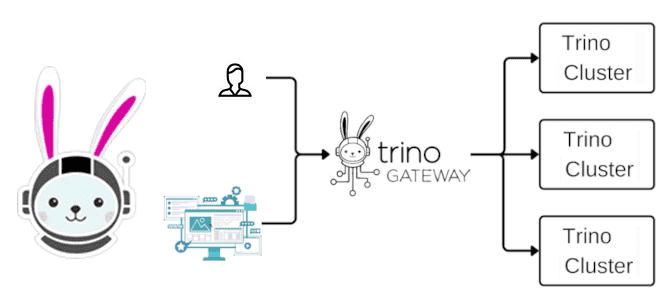
Что такое Trino Gateway, зачем он нужен и как работает: для чего делить один большой кластер Trino на несколько маленьких и как к ним обращаться без изменений на стороне клиентов. Проблемы бесконечного масштабирования кластера Благодаря горизонтальному масштабированию, о котором мы говорили вчера, кластер Trino можно расширять, добавляя новые рабочие узлы....
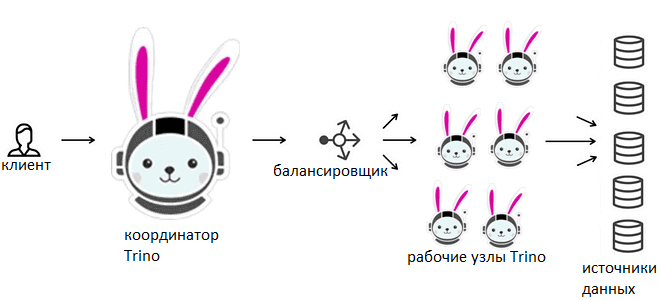
Как ускорить работу Trino при росте нагрузки и сэкономить на кластере при ее сокращении: автомасштабирование рабочих узлов и операций записи, а также настройка групп ресурсов. Масштабирование кластера Классическим способом справиться с растущими вычислительными нагрузками в гомогенной распределенной системе является горизонтальное масштабирование кластера. Это сводится к добавлению новых узлов, которые отвечают...