 1044
1044 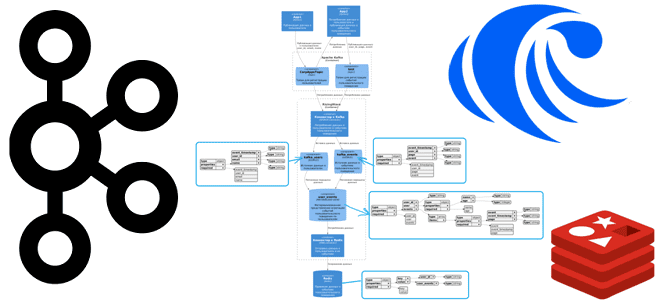
Как SQL-запросами соединить потоки из разных топиков Apache Kafka и отправить результаты в Redis: демонстрация ETL-конвейера на материализованных представлениях в RisingWave.
Постановка задачи и проектирование потоковой системы
Продолжая недавний пример потоковой агрегации данных из разных топиков Kafka с помощью SQL-запросов, сегодня расширим потоковый конвейер в RisingWave, добавив приемник данных – key-value хранилище Redis. RisingWave – это распределенная реляционная СУБД, которая позволяет работать с потоками данных как с обычными таблицами через типовые SQL-запросы. SQL-запросы выполняются над постепенно обновляемым, согласованными материализованными представлениям, которые принимают данные из внешних источников. Результаты выполнения этих запросов можно передавать их во внешние хранилища с помощью коннекторов.
Предположим, в один топик Kafka публикуются данные о пользователях, а в другой – о событиях их пользовательского поведения. Source-коннектор RisingWave потребляет данные из топиков Kafka, записывая их в потоковые источники, к которым создается SQL-запрос на соединение данных по идентификатору пользователя и сохраняется в материализованном представлении. Это материализованное представление агрегирует данные о пользователе и событиях его поведения на веб-страницах, сохраняя их как JSON-документы в полях этого табличного представления.
Архитектура потоковой системы схематично будет выглядеть так:
Скрипты публикации данных и схемы полезной нагрузки приведены здесь, а SQL-запросы потребления данных из Kafka и создания материализованных представлений по пользователям и событиям приведены в прошлой статье.
Реализация потокового ETL-конвейера
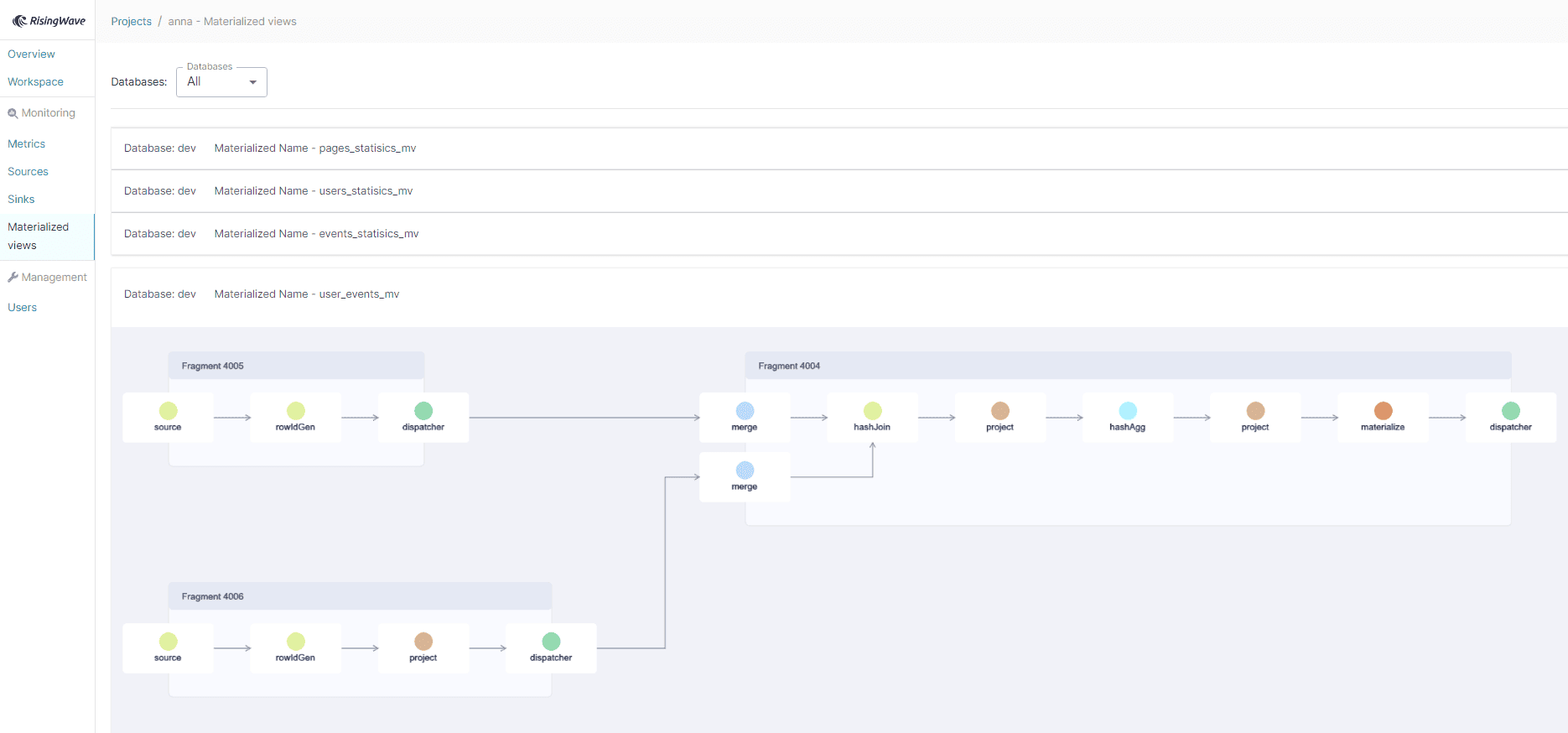
Для соединения данных из разных топиков Kafka и выполнения преобразований над ними в RisingWave надо создать материализованное представление:
CREATE MATERIALIZED VIEW user_events_mv AS
SELECT
u.user_id,
JSONB_BUILD_OBJECT(
'email', u.email,
'name', u.name,
'registrated', u.event_timestamp
) AS user,
JSONB_AGG(
JSONB_BUILD_OBJECT(
'event_timestamp', e.event_timestamp,
'event', e.event,
'page', e.page
)
) AS events
FROM
kafka_users u
LEFT JOIN
kafka_events e
ON
u.user_id = e.user_id
GROUP BY
u.user_id, u.email, u.name, u.event_timestamp;
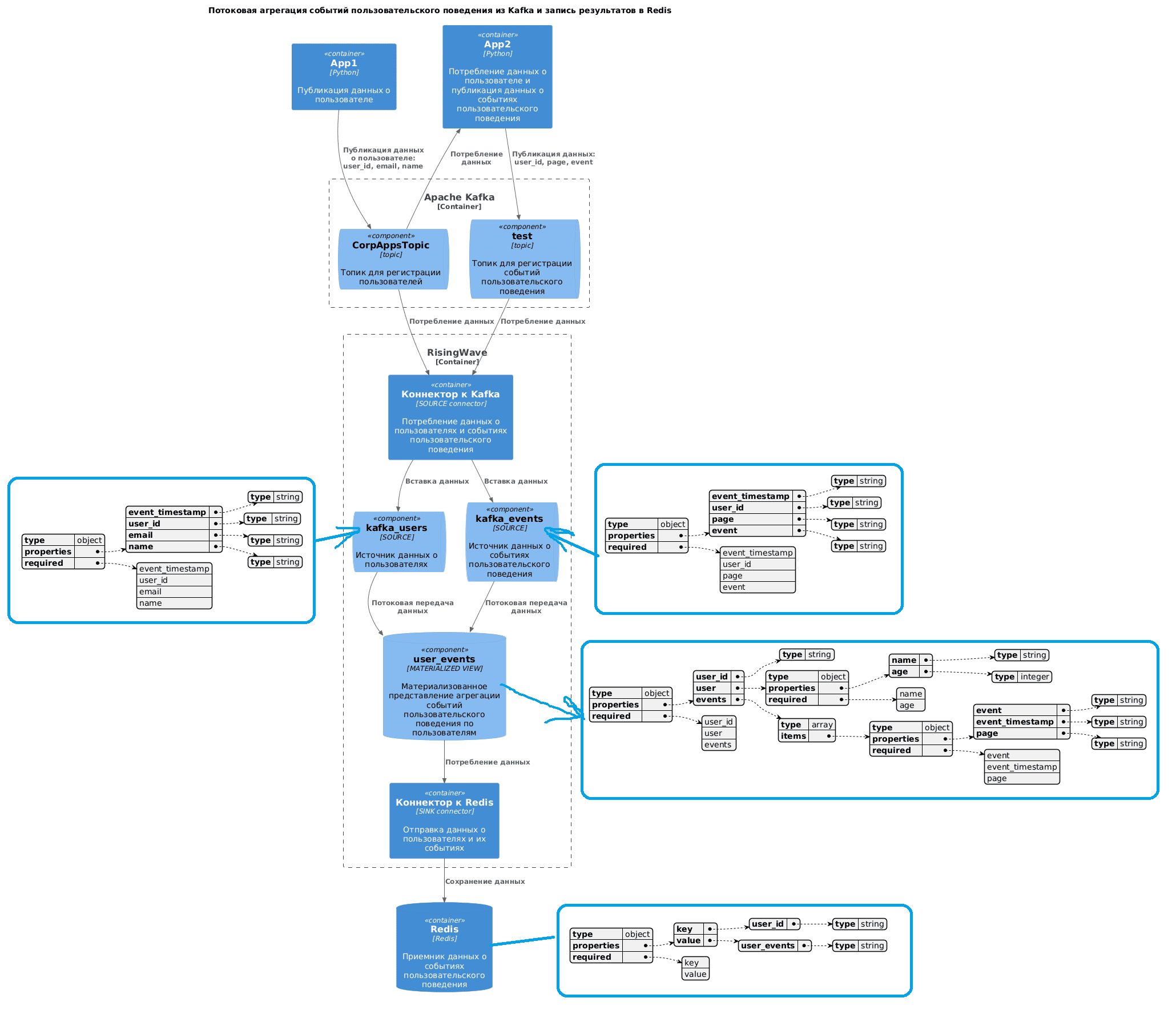
Чтобы передавать во внешнюю систему данные о всех зарегистрированных пользователях, даже если они не совершали никаких событий, в этом запросе используется LEFT JOIN. Группировка данных по user_id, email, name и event_timestamp, нужна чтобы обеспечить правильное агрегирование событий для каждого пользователя. Результат SELECT-запроса к матпредставлению user_events_mv в RisingWave выглядит так:
Чтобы передать данные в Redis, надо сперва создать приемник данных (sink), используя соответствующий коннектор, а также указав, что будет ключом, а что – значением. RisingWave передает данные в Redis в виде строк, хранящих пары ключ-значение в указанном формате (JSON или TEMPLATE), поэтому первичный ключ всегда должен быть указан. В моем случае логично использовать в качестве ключа идентификатор пользователя user_id, а вся остальная информация о пользователе и его событиях будет значением. И ключ и значение в redis будут являться строками. SQL-запрос на передачу данных в Redis из RisingWave выглядит так:
CREATE SINK IF NOT EXISTS redis_sink
FROM user_events_mv WITH (
connector = 'redis',
primary_key = 'user_id',
redis.url= 'redis://your-redis:password@host:port'
) FORMAT PLAIN ENCODE TEMPLATE (
force_append_only='true',
key_format = '{user_id}',
value_format = '{user},{events}'
);
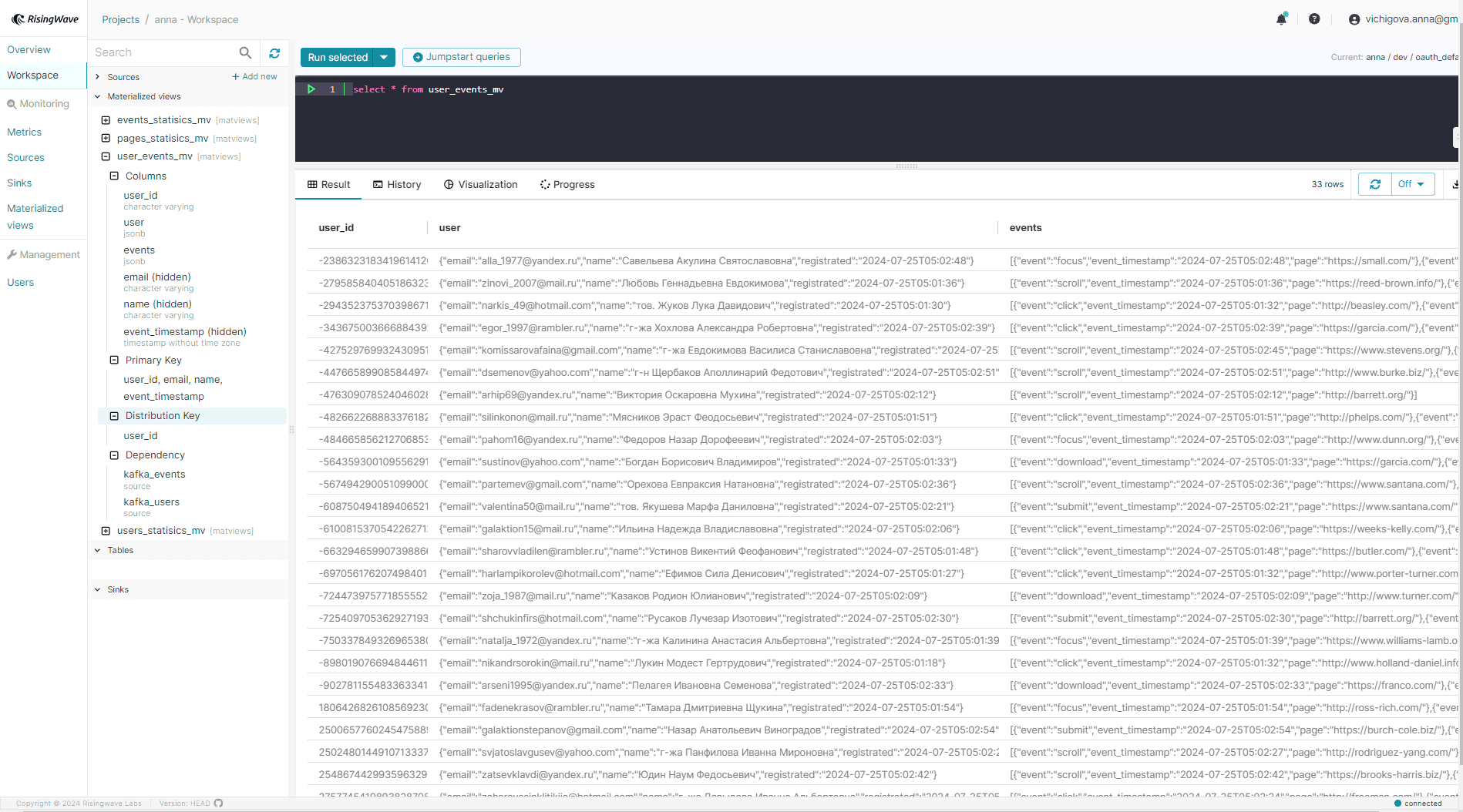
После выполнения этой инструкции в Redis появятся потребленные из Kafka, соединенные и агрегированные данные:
Граф потокового запроса в RisingWave состоит из 3-х фрагментов, каждый из которых представляет собой цепочку SQL-операторов.
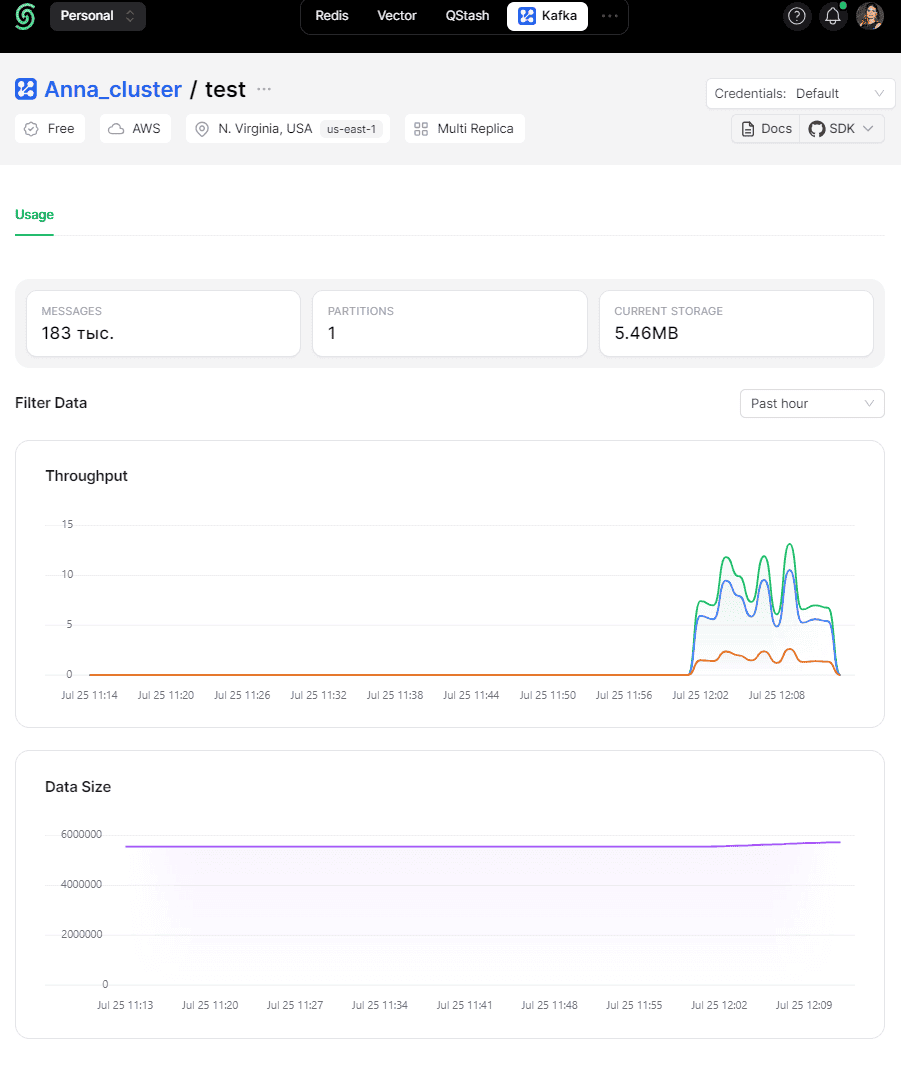
Информация о публикации и потреблении данных также отображается в интерфейсе Kafka.
Таким образом, потоковые базы данных с широким набором коннекторов позволяют строить интересные ETL-конвейеры обработки данных, выполняя над ними различные преобразования. Однако, они не отличаются высокой надежностью и устойчивостью, по крайней мере, их бесплатные инстансы. В частности, в работе над этим конвейером я часто сталкивалась с отказом платформы RisingWave, потерей соединения с моим экземпляром и сложностями с подключением ко внешним система. Например, не удалось передать данные в Elasticsearch, хотя экземпляр этой документо-ориентированной БД отлично работает и доступен извне, что подтверждает подобная разработка на платформе Decodable, о которой я писала здесь.
Тем не менее, подобные потоковые платформы, позволяющие оперировать с потоками данных как с таблицами через SQL-запросы, знакомые каждому аналитику, отлично позволяют этим специалистам проверить гипотезу или быстро получить какие-то данные, не отвлекая инженеров.
Как делать это эффективно с учетом всех особенностей Apache Kafka, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

