 723
723 
Содержание
Как написать DAG в Apache AirFlow без программирования, определив его конфигурацию в YAML-файле, и автоматически получить пакетный конвейер обработки данных с помощью Python-библиотеки DAG Factory.
Демократизация разработки ETL-конвейеров или что такое DAG Factory в Apache AirFlow
Хотя Apache AirFlow и так считается довольно простым фреймворком для оркестрации пакетных процессов и реализации ETL-операций благодаря использованию Python, разработчики стараются сделать его еще проще. Это соответствует устойчивому тренду в инженерии данных с фокусированием на бизнес-логике обработки данных, а не фактическом программировании. Например, использование SQL-запросов для потоковых агрегаций и преобразований вместо разработки полноценного приложения потребителя, что я недавно показывала здесь и здесь. Таким образом, проектировать и реализовывать конвейеры обработки данных могут не только опытные дата-инженеры, но и сами потребители этих операций, т.е. аналитики.
В Apache AirFlow тоже реализуется такая тенденция демократизации инженерии данных. Поэтому в июле 2024 года компания Astronomer, которая активно развивает и продвигает этот open-source фреймворк, а также свою коммерческую платформу оркестрации на его основе, объявила об интеграции проекта DAG Factory в AirFlow. Этот проект с открытым исходным кодом, изначально созданный Адамом Боскарино, позволяет генерировать DAG-файлы из YAML-файлов. Это избавляет разработчика ETL-конвейера от необходимости программирования на Python, ведь YAML-формат знаком каждому аналитику по спецификациям OpenAPI.
Разумеется, YAML-файл с описанием пакетного конвейера трансформируется в DAG не сам по себе, а благодаря Python-пакету DAG Factory, который работает с версией языка от 3.8.0+ и Apache Airflow® 2.0+. Чтобы создать DAG из YAML-файла описывающего его конфигурацию, нужно один раз в этой же самой директории создать py-файл, в котором надо указать расположение файла конфигурации и вызвать у объекта dagfactory метод generate_dags(globals()). Как это сделать, я покажу далее на простом примере.
Практический пример генерации DAG из YAML-файла
Рассмотрим простой конвейер из 3-х задач: первая проверяет доступность внешнего веб-сайта, отправляя к нему GET-запрос, а две другие передают результат в Telegram-бот, в зависимости от успеха предыдущей задачи. Пример подобного конвейера я показывала здесь.
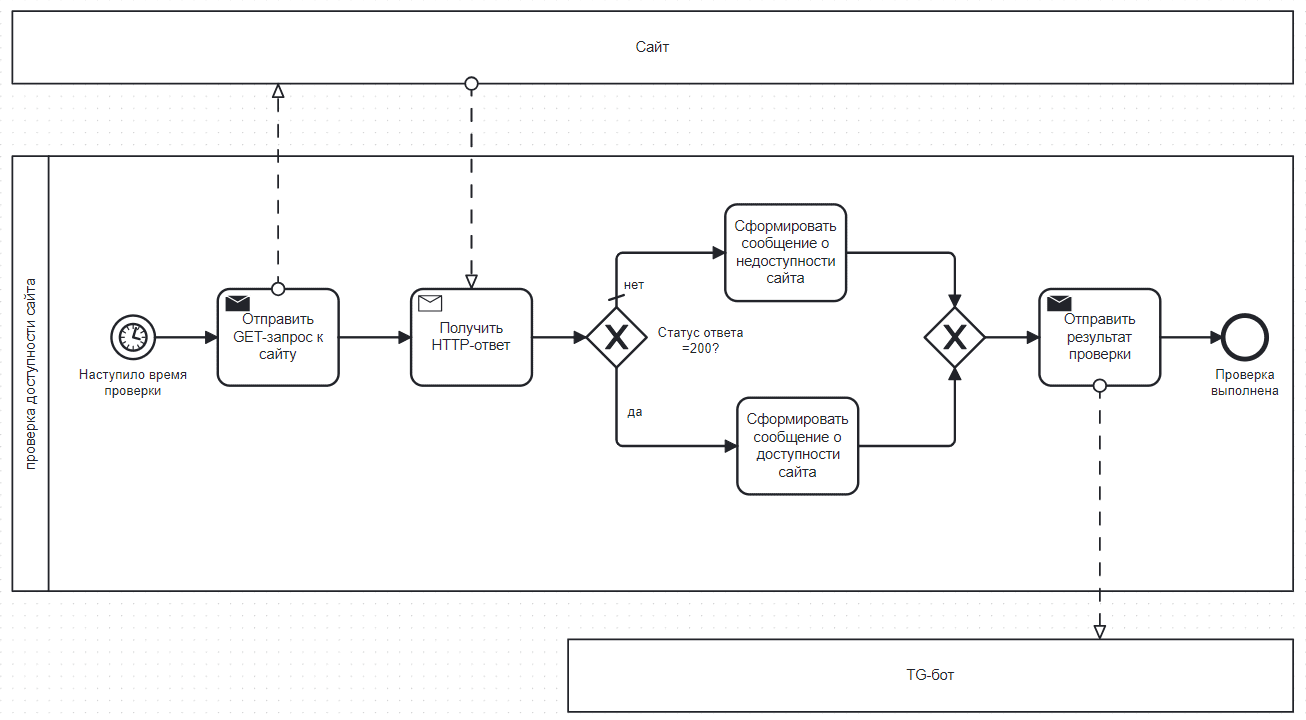
Реализовать эту простую бизнес-логику в AirFlow можно с помощью триггерных правил. По умолчанию в AirFlow задано правило триггера all_success, когда зависимая задача выполняется, если все вышестоящие задачи выполнены успешно. А правило триггера one_failed запустит нижестоящую задачу запускается при сбое хотя бы одной вышестоящей. Эти триггеры отлично подойдут для рассматриваемой задачи.
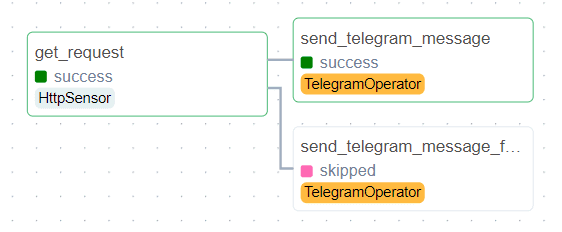
Если писать DAG Airflow на Python, он будет выглядеть так:
from datetime import datetime, timedelta
from airflow import DAG
from airflow.sensors.http_sensor import HttpSensor
from airflow.providers.telegram.operators.telegram import TelegramOperator
default_args = {
'owner': 'anna',
'retries': 1,
'start_date': datetime(2024, 7, 25),
}
with DAG(
'site_check_tg',
default_args=default_args,
description='DAG проверки доступности сайта и отправки результата в TG',
schedule_interval='0 5 * * *',
catchup=False,
) as dag:
get_request = HttpSensor(
task_id='get_request',
http_conn_id='site',
endpoint='',
request_params={},
response_check=lambda response: response.status_code == 200,
poke_interval=5,
timeout=20,
retries=1,
mode='poke'
)
send_telegram_message_success = TelegramOperator(
task_id='send_telegram_message_success',
telegram_conn_id='telegram_default',
token='your token',
chat_id='your chat-id',
text='Сайт доступен!',
trigger_rule='all_success'
)
send_telegram_message_failure = TelegramOperator(
task_id='send_telegram_message_failure',
telegram_conn_id='telegram_default',
token='your-token',
chat_id='your chat-id',
text='Сайт недоступен!',
trigger_rule='one_failed'
)
get_request >> send_telegram_message_success
get_request >> send_telegram_message_failure
Но с помощью DAG Factory можно представить конфигурацию этого конвейера в виде YAML-файла:
site_check_tg:
default_args:
owner: 'anna'
retries: 1
start_date: '2024-07-25'
schedule_interval: '0 5 * * *'
catchup: False
description: 'DAG проверки доступности сайта и отправки результата в TG'
tasks:
get_request:
operator: airflow.sensors.http_sensor.HttpSensor
http_conn_id: 'site'
endpoint: ''
request_params: {}
response_check_lambda: "lambda response: response.status_code == 200"
poke_interval: 5
timeout: 20
retries: 1
mode: 'poke'
send_telegram_message:
operator: airflow.providers.telegram.operators.telegram.TelegramOperator
token: 'your-token'
chat_id: 'your-chait_id'
text: 'Сайт доступен!'
dependencies: [get_request]
trigger_rule: 'all_success'
send_telegram_message_failure:
operator: airflow.providers.telegram.operators.telegram.TelegramOperator
token: 'your token'
chat_id: 'your chat-id'
text: 'Сайт недоступен!'
dependencies: [get_request]
trigger_rule: 'one_failed'
Чтобы Airflow сгенерировал DAG на основе этого YAML-файла конфигурации, надо в рабочую директорию с конвейерами положить следующий py-файл:
from airflow import DAG
import dagfactory
from pathlib import Path
config_file = Path('/opt/airflow/dags/yaml/config_file.yml')
dag_factory = dagfactory.DagFactory(config_file)
dag_factory.clean_dags(globals())
dag_factory.generate_dags(globals())
Функция clean_dags(globals()) очищает текущие DAG-и, удаляя или деактивируя те, которые больше не актуальны. Она может использовать глобальный контекст, что предоставляется через аргумент globals() для доступа к текущему состоянию и переменным. А функция generate_dags(globals()) отвечает за динамическое создание новых DAG-ов на основе определенных конфигураций в YAML-файлах. Она тоже использует глобальный контекст для доступа к данным и переменным. Сами YAML-файлы конфигурации рекомендуется хранить в отдельной папке, доступ к которой надо указать в py-файле.
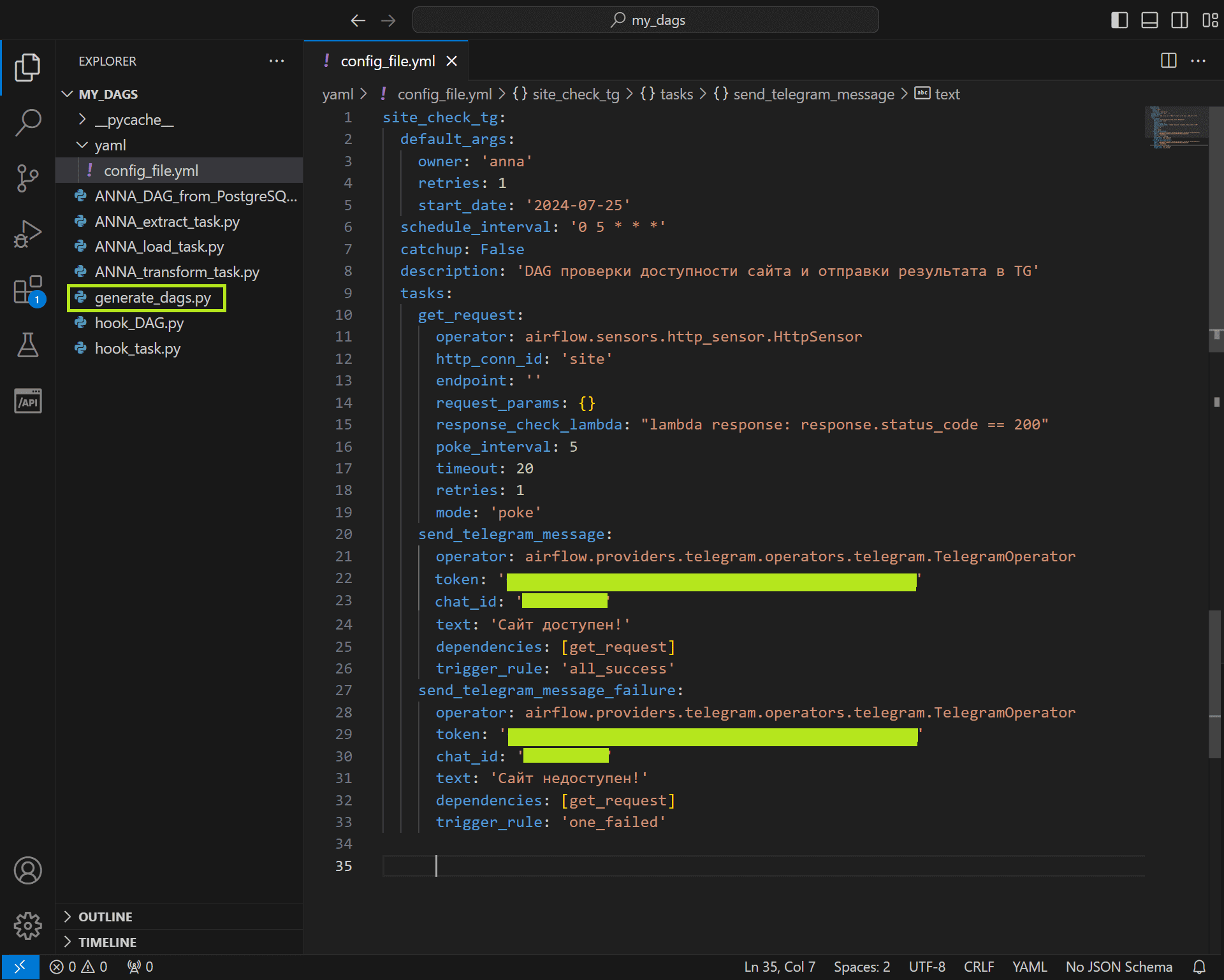
Если ошибок в YAML-файле конфигурации нет, т.е. синтаксис верный и в качестве операторов используются те, которые установлены в среде Airflow, в GUI фреймворка появится DAG, сгенерированный по этому описанию.
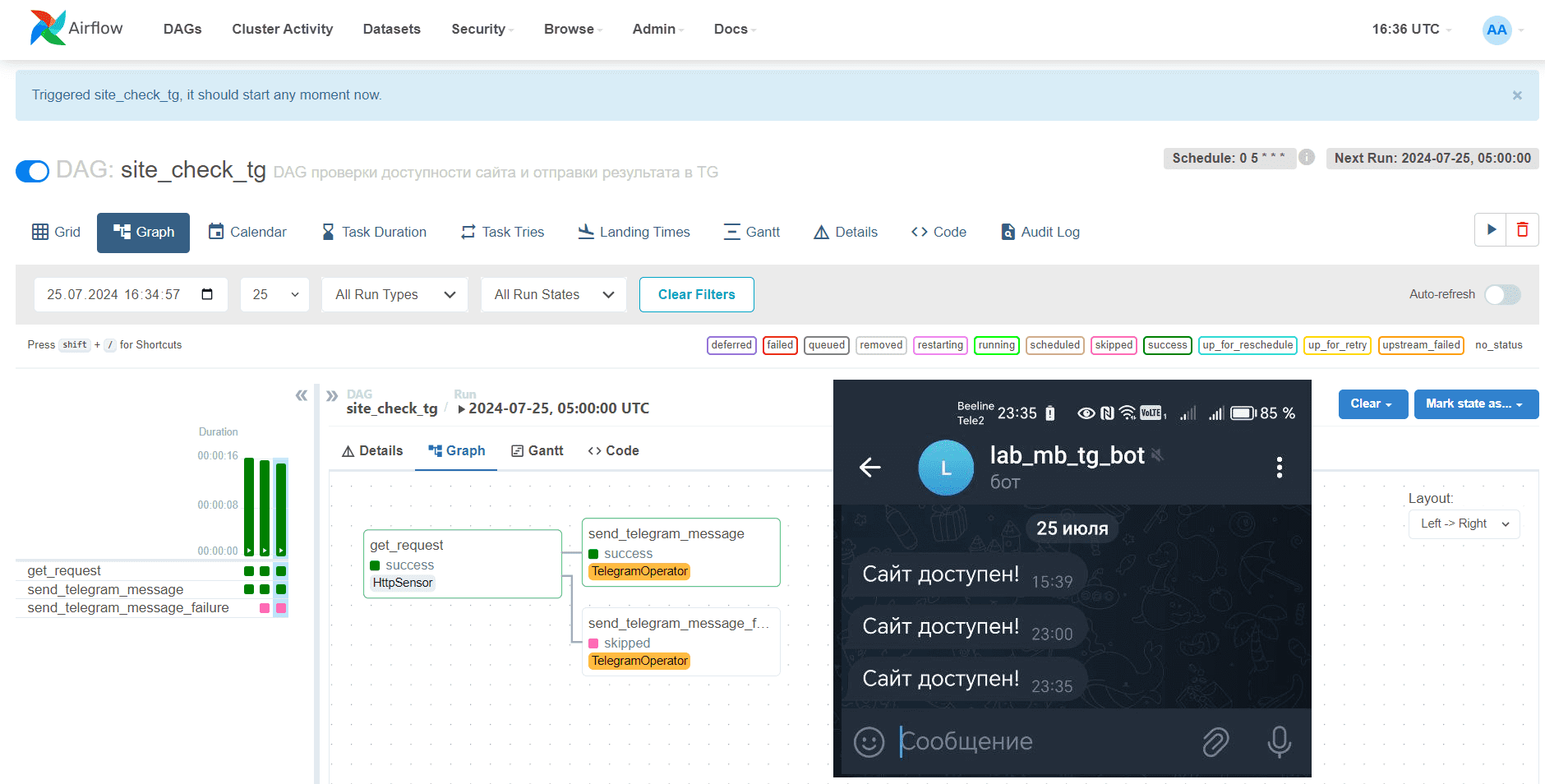
Таким образом, задача проектирования и реализации конвейера в Apache AirFlow с DAG Factory стала еще проще. Кроме использования готовых операторов, эта Python-библиотека также поддерживает использование пользовательских операторов, позволяя задать путь к пользовательскому оператору в ключе operator в файле конфигурации и добавить любые дополнительные параметры.
Наконец, DAG Factory поддерживает планирование DAG с помощью наборов данных (датасетов). Для этого надо указать датасет в ключе outlets YAML-файла конфигурации, определив его местоположение. А в ключе schedule потребительского DAG можно задать датасет, который надо запланировать, чтобы запустить его, когда все наборы данных будут доступны. Если YAML-конфигурация DAG слишком большая, ее можно разделить на несколько файлов. Также можно динамически создавать разное количество задач, используя ключ mapped_tasks в YAML-файле конфигурации, который представляет собой список словарей, где каждый словарь – это задача. Как это сделать, я покажу в следующий раз.
Освойте администрирование и эксплуатацию Apache AirFlow для оркестрации пакетных процессов в задачах реальной дата-инженерии на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Data Pipeline на Apache AirFlow и Apache Hadoop
- AIRFLOW с использованием Yandex Managed Service for Apache Airflow™
Источники

