
В мире Big Data технологии меняются с бешеной скоростью, но слон (Hadoop) все еще в комнате. Несмотря на популярность облачных S3-хранилищ, распределенная файловая система HDFS остается стандартом де-факто для многих корпоративных хранилищ Data Lake и on-premise кластеров. Даже если вы не пишете MapReduce-задачи на Java, ваш Airflow, скорее всего,...

Чем объектное хранилище данных отличается от классической файловой системы POSIX, как это влияет на разработку Spark-приложений, почему операция переименования снижает производительность облачных вычислений и что поможет ее избежать. Еще раз об отличиях объектных и файловых хранилищ и как это влияет на приложения Spark Будучи компонентом экосистемы Apache Hadoop, фреймворк Spark...

24 сентября вышел очередной релиз Apache Spark. Он не содержит новых фичей, но зато в нем есть несколько полезных оптимизаций и исправлений безопасности. Читайте далее о самом главном из них, связанном с утечкой токена делегирования Hadoop. Зачем нужны токены делегирования Hadoop в Spark и как они работают В выпуске Apache...

Зачем делать моментальные снимки состояния распределенной файловой системы Apache Hadoop, почему не стоит создавать снапшоты HDFS в корневом каталоге и как найти оптимальную частоту сохранения состояния больших данных. Как устроен механизм снапшотов в HDFS Чтобы повысить надежность системы, ее состояние необходимо периодически сохранять. Для баз данных и файловых систем эта...

Формат данных в озере или гибридном хранилище типа Data LakeHouse сильно влияет на скорость выполнения аналитических запросов. Сегодня рассмотрим, как Apache CarbonData делает аналитику больших данных в реальном времени еще быстрее. Что такое Apache CarbonData Традиционные форматы данных, часто используемые в проектах Big Data, такие как CSV и AVRO, имеют...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...
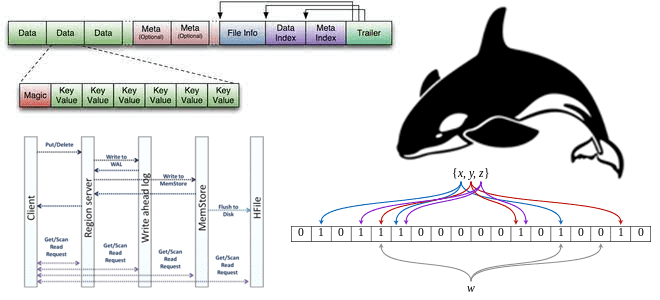
Что такое HFile, как появился этот низкоуровневый файловый формат, каковы его главные принципы работы, как Apache HBase использует его для хранения и быстрой аналитики больших данных, и при чем здесь фильтр Блума. Роль HFile в Apache HBase Apache HBase реализует возможности Google BigTable для Hadoop. Эта NoSQL-СУБД типа «семейство колонок»...

Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...

Сегодня на примере Apache HBase и Redis разберемся со сходствами и отличиями NoSQL-СУБД типа «семейство колонок» и «ключ-значение». Что между ними общего и что выбирать для практического использования в зависимости от сценариев применения. 3 типа NoSQL-хранилищ данных Apache HBase и Redis являются довольно популярными базами данных среди NoSQL-решений. Однако, они...

Метод ближайших соседей активно используется в машинном обучении для решения задач классификации в различных бизнес-приложениях. Познакомимся поближе с этим алгоритмом Machine Learning, а также разберем, почему NoSQL-хранилище Apache HBase отлично подходит для работы с ним. Что такое метод ближайших соседей: ликбез по Machine Learning В проектах Machine Learning и приложениях...

Сегодня в рамках обучения администраторов SQL-on-Hadoop рассмотрим, как защитить данные в кластере Apache HBase от несанкционированного доступа. Аутентификация и авторизация пользователей, операторы управления доступом к таблицам, метки видимости и шифрование данных. Механизмы защиты данных в Apache HBase Как и любое хранилище, колоночно-ориентированная мультиверсионная NoSQL-СУБД типа key-value Apache HBase, которая работает...
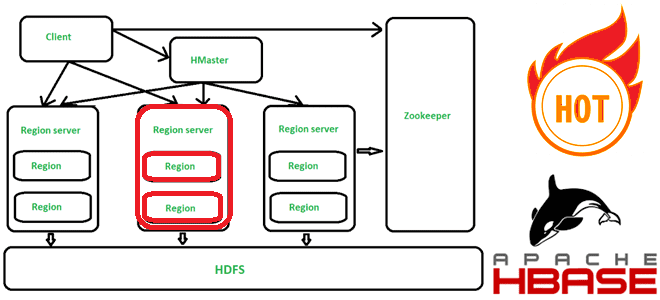
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки. Что такое горячие точки в кластере Apache HBase и почему они случаются Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...
Мы уже писали о важности резервного копирования данных в Apache HBase на примере ИТ-компании Clairvoyant. Сегодня рассмотрим опыт индийской компании Myntra, которая предложила простую методику создания инкрементных бэкапов для Apache HBase 2.1.4 и Hadoop 2.7.3, а также восстановления нужных данных из этих резервных копий в BLOB-хранилищах по требованию пользователя. 5...

Риски и возможности отечественного рынка труда с точки зрения профессиональной сертификации по технологиям больших данных. Как и зачем Школа Больших Данных разрабатывает профессиональную вендор-независимую сертификацию по продуктам и технологиям Big Data для еще лучшей подготовки и оценки ИТ-специалистов на российском рынке, опустевшем после ухода западных вендоров. Как изменился рынок профессиональных...

Хотя Apache Pig сегодня не самый актуальный инструмент для аналитики больших данных в экосистеме Hadoop, дата-инженеру полезно знать его основные принципы работы и ключевые отличия от Hive. Также рассмотрим, чем Hive отличается от Pig в качестве средства SQL-on-Hadoop. Что такое Apache Pig Apache Pig – это высокоуровневый процедурный язык для...
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...
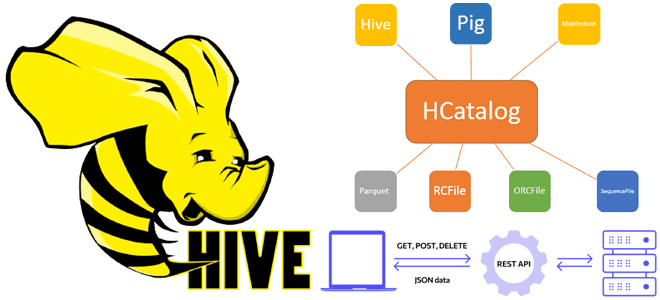
Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton. Принципы работы компонента WebHCat как REST-сервиса Apache Hive Будучи NoSQL-хранилищем класса...

Недавно мы писали про чтение данных из AWS S3 с помощью PySpark-задний. Продолжая разбираться, как перейти от HDFS к облачным объектным хранилищам, сегодня рассмотрим пример чтения и записи файлов из Google Cloud Storage с помощью Apache Spark. От HDFS к GCS Распределенная файловая система Apache Hadoop (HDFS) уже много лет...

16 ноября 2022 года вышел 2-ой альфа-релиз Apache Hive 4.0.0. Какие ошибки в нем исправлены и что за новые функции, важные для дата-инженера и администратора кластера Hadoop, появились. А перед этим вспомним основные принципы работы Apache Hive. Принципы работы Apache Hive Apache Hive является популярным инструментом стека SQL-on-Hadoop, позволяя обращаться...