
Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

Сегодня рассмотрим ключевые достоинства и недостатки резидентных СУБД для больших данных на примере Tarantool. Читайте в нашей статье про основные сценарии использования In-Memory Database (IMDB) в области Big Data с конкретными кейсами из реального бизнеса от Альфа-Банка, Аэрофлота, Тинькофф-Банка и Мегафона. Где и как используются In-Memory в Big Data: 4...
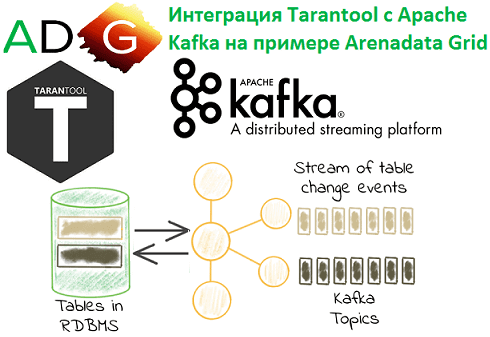
Продолжая разбираться с In-Memory СУБД Tarantool и Arenadata Grid, сегодня рассмотрим, как эти резидентные базы данных интегрируются с Apache Kafka. Читайте в нашей статье, что такое коннекторы и процессоры, а также как записать в топик Кафка сообщение, SQL-запрос или часть таблицы. Arenadata Grid и Apache Kafka: коннектор + процессоры Напомним,...

Вчера мы разбирали In-Memory СУБД на примере Tarantool. Сегодня поговорим про Arenadata Grid: что это такое, чем хороша эта база данных, каким образом она связана с Тарантул и чем от него отличается. Также рассмотрим, как Arenadata Grid интегрируется с внешними Big Data системами, в т.ч. основными компонентами инфраструктуры Apache Hadoop...

В этой статье мы рассмотрим резидентные (In-Memory) базы данных на примере Tarantool и Arenadata Grid: что это, как они работают и где используются. Еще поговорим, каким образом эти Big Data системы могут ускорить работу распределенных приложений без замены существующих СУБД, а также при чем здесь промышленный интернет вещей и экосистема...