 1627
1627 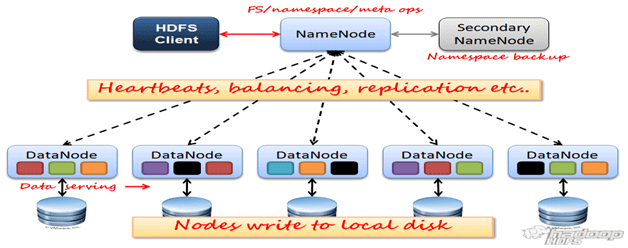
Содержание
HDFS (Hadoop Distributed File System) — распределенная файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера [1], который может состоять из произвольного аппаратного обеспечения [2]. Hadoop Distributed File System, как и любая файловая система – это иерархия каталогов с вложенными в них подкаталогами и файлами [3].
Применение Hadoop Distributed File System
HDFS – неотъемлемая часть Hadoop, проекта верхнего уровня Apache Software Foundation, и основа инфраструктуры больших данных (Big Data). Однако, Hadoop поддерживает работу и с другими распределёнными файловыми системами, в частности, Amazon S3 и CloudStore. Также некоторые дистрибутивы Hadoop, например, MapR, реализуют свою аналогичную распределенную файловую систему – MapR File System [1].
HDFS может использоваться не только для запуска MapReduce-заданий, но и как распределённая файловая система общего назначения, обеспечивая работу распределённых СУБД (HBase) и масштабируемых систем машинного обучения (Apache Mahout) [1].
Архитектура HDFS
Кластер HDFS включает следующие компоненты [3]:
- Управляющий узел, узел имен или сервер имен (NameNode) – отдельный, единственный в кластере, сервер с программным кодом для управления пространством имен файловой системы, хранящий дерево файлов, а также мета-данные файлов и каталогов. NameNode – обязательный компонент кластера HDFS, который отвечает за открытие и закрытие файлов, создание и удаление каталогов, управление доступом со стороны внешних клиентов и соответствие между файлами и блоками, дублированными (реплицированными) на узлах данных. Сервер имён раскрывает для всех желающих расположение блоков данных на машинах кластера.
- Secondary NameNode — вторичный узел имен, отдельный сервер, единственный в кластере, который копирует образ HDFS и лог транзакций операций с файловыми блоками во временную папку, применяет изменения, накопленные в логе транзакций к образу HDFS, а также записывает его на узел NameNode и очищает лог транзакций. Secondary NameNode необходим для быстрого ручного восстанавления NameNode в случае его выхода из строя.
- Узел или сервер данных (DataNode, Node) – один их множества серверов кластера с программным кодом, отвечающим за файловые операции и работу с блоками данных. DataNode – обязательный компонент кластера HDFS, который отвечает за запись и чтение данных, выполнение команд от узла NameNode по созданию, удалению и репликации блоков, а также периодическую отправку сообщения о состоянии (heartbeats) и обработку запросов на чтение и запись, поступающих от клиентов файловой системы HDFS. Стоит отметить, что данные проходят с остальных узлов кластера к клиенту мимо узла NameNode.
- Клиент (client) – пользователь или приложение, взаимодействующий через специальный интерфейс (API – Application Programming Interface) с распределенной файловой системой. При наличии достаточных прав, клиенту разрешены следующие операции с файлами и каталогами: создание, удаление, чтение, запись, переименование и перемещение. Создавая файл, клиент может явно указать размер блока файла (по умолчанию 64 Мб) и количество создаваемых реплик (по умолчанию значение равно 3-ем).
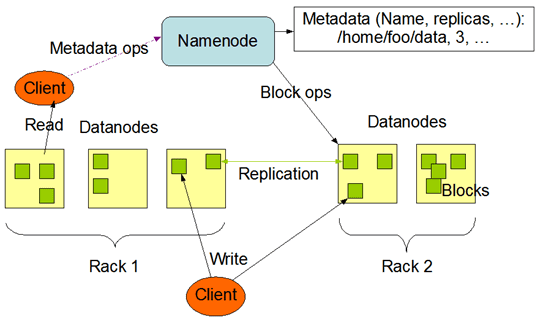
Взаимодействие узлов имен, узлов данных и клиентов осуществляется по протоколам на основе TCP/IP.
Отличительные характеристики распределенной файловой системы хадуп
Благодаря репликации блоков по узлам данных, распределенная файловая система Hadoop обеспечивает высокую надежность хранения данных и скорость вычислений. Кроме того, HDFS обладает рядом отличительных свойств [4]:
- большой размер блока по сравнению с другими файловыми системами (>64MB), поскольку HDFS предназначена для хранения большого количества огромных (>10GB) файлов;
- ориентация на недорогие и, поэтому не самые надежные сервера – отказоустойчивость всего кластера обеспечивается за счет репликации данных;
- зеркалирование и репликация осуществляются на уровне кластера, а не на уровне узлов данных;
- репликация происходит в асинхронном режиме – информация распределяется по нескольким серверам прямо во время загрузки, поэтому выход из строя отдельных узлов данных не повлечет за собой полную пропажу данных;
- HDFS оптимизирована для потоковых считываний файлов, поэтому применять ее для нерегулярных и произвольных считываний нецелесообразно;
- клиенты могут считывать и писать файлы HDFS напрямую через программный интерфейс Java;
- файлы пишутся однократно, что исключает внесение в них любых произвольных изменений;
- принцип WORM (Write-once and read-many, один раз записать – много раз прочитать) полностью освобождает систему от блокировок типа «запись-чтение». Запись в файл в одно время доступен только одному процессу, что исключает конфликты множественной записи.
- HDFS оптимизирована под потоковую передачу данных;
- сжатие данных и рациональное использование дискового пространства позволило снизить нагрузку на каналы передачи данных, которые чаще всего являются узким местом в распределенных средах;
- самодиагностика — каждый узел данных через определенные интервалы времени отправляет диагностические сообщения узлу имен, который записывает логи операций над файлами в специальный журнал;
- все метаданные сервера имен хранятся в оперативной памяти.
Недостатки файловой системы HDFS
- сервер имен является центральной точкой всего кластера и его отказ повлечет сбой системы целиком;
- отсутствие полноценной репликации Secondary NameNode;
- отсутствие возможности дописывать или оставить открытым для записи файлы в HDFS;
- отсутствие поддержки реляционных моделей данных;
- отсутствие инструментов для поддержки ссылочной целостности данных, что не гарантирует идентичность реплик. HDFS перекладывает проверку целостности данных на клиентов. При считывании файла клиент обращается к данным и контрольным суммам. В случае их несоответствия происходит обращение к другой реплике [5].
Подробно о том, как работает HDFS, читайте в нашей отдельных статьях: взаимодействие компонентов и файловые операции (запись, чтение, удаление и репликации).</p>
Практика работы с HDFS, настройка, администрирование и использование всей инфраструктуры Hadoop для больших данных и машинного обучения на наших компьютерных курсах для пользователей, инженеров, администраторов и аналитиков Big Data и Machine Learning в Москве:</p>
- INTR: Основы Hadoop;
- HADM: Администрирование кластера Hadoop;
- HIVE: Hadoop SQL Hive администратор.
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
Источники
- https://ru.wikipedia.org/wiki/Hadoop#HDFS
- https://microsoftbi.ru/basics/bigdata/hdfs/
- https://www.codeinstinct.pro/2012/08/hdfs-design/?m=1
- http://www.taskdata.com/index.php?id=26&Itemid=5&option=com_content&view=article&lang=ru
- https://habr.com/ru/post/42858/