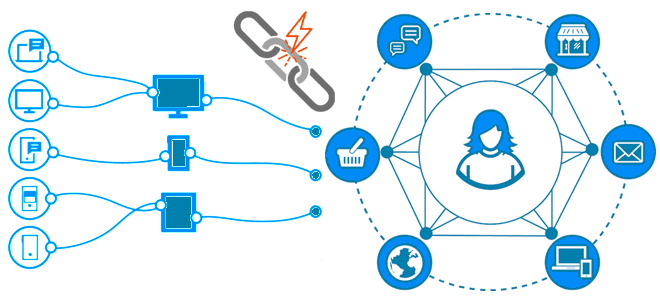
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
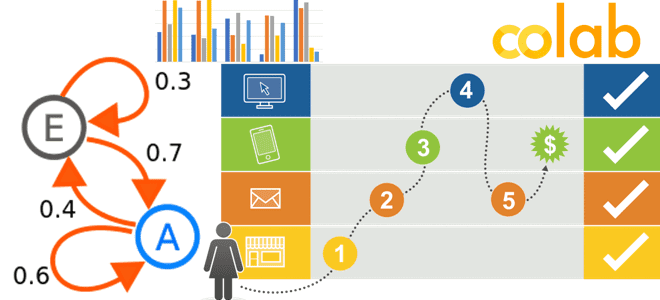
Недавно мы писали, что такое цепь Маркова, как это используется в практических приложениях Data Science и с помощью каких инструментов реализуется этот граф состояний. В продолжение этой полезной для обучения дата-аналитиков темы посмотрим на модели маркетинговой атрибуции как на марковские цепи и разберем пользу этого представления. Практический пример в Google...

Сегодня рассмотрим пример программы лояльности турецкого интернет-магазина Trendyol, где Apache Kafka и документо-ориентированная NoSQL-СУБД Couchbase используются для генерации купонов на скидки. Почему при большом объеме данных случаются проблемы тайм-аутов в Couchbase, как их решить и при чем здесь коннекторы к Apache Kafka. Архитектура системы управления купонами Trendyol – это популярный...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...
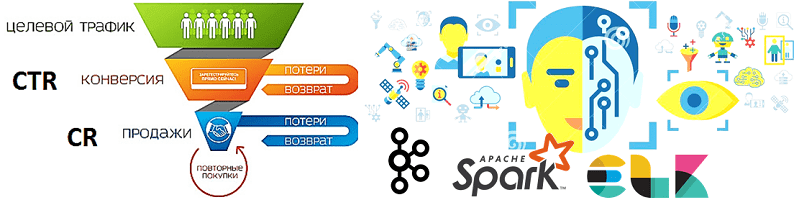
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
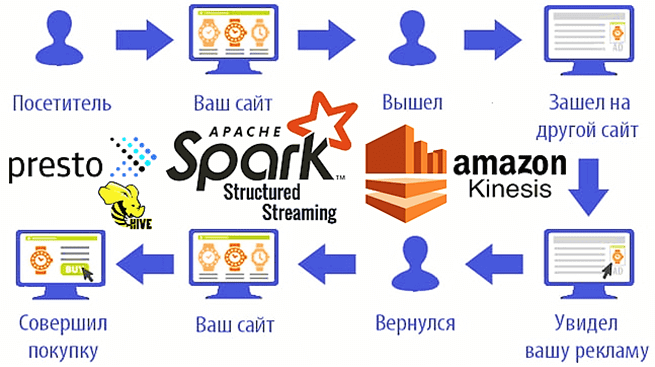
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Современная аналитика больших данных ориентируется на обработку Big Data в реальном времени. Такие вычисления «на лету» позволяют в режиме онлайн узнавать о критически важных производственных показателях и оперативно понимать клиентские потребности. Это существенно ускоряет и автоматизирует цикл принятия управленческих решений в соответствии с требованиями сегодняшнего бизнеса. Обычно для реализации архитектуры...

Сегодня мы расскажем, что такое программная печать, зачем ритейлеры используют эту технологию и как programmatic print связана с Big Data. Читайте в нашей статье, как IKEA, «Рив Гош», «Ив Роше» и Bonprix используют Big Data для персонального маркетинга в своих рекламных кампаниях, а также повышают лояльность клиентов и стимулируют продажи...

В продолжение темы про использование технологий Big Data и Machine Learning в FMCG-бизнесе, сегодня мы поговорим, как распознавание лиц помогает сформировать персональные маркетинговые предложения и насколько это законно. Разбираемся с видеоаналитикой и 152-ФЗ «О персональных данных» на примерах отечественных и зарубежных ритейлеров. От воров до VIP-клиентов: 5 примеров распознавания лиц...