633
633 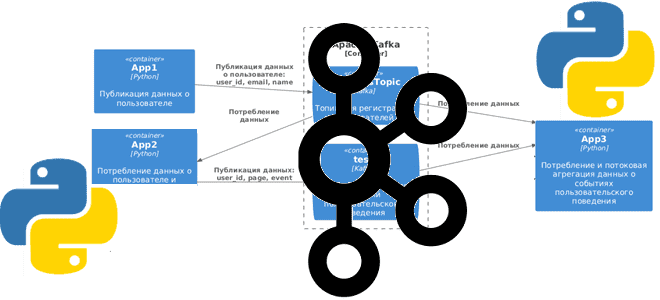
Сегодня я покажу простую демонстрацию потоковой агрегации данных из разных топиков Apache Kafka на примере Python-приложений для соединения событий пользовательского поведения с информацией о самом пользователе.
Постановка задачи
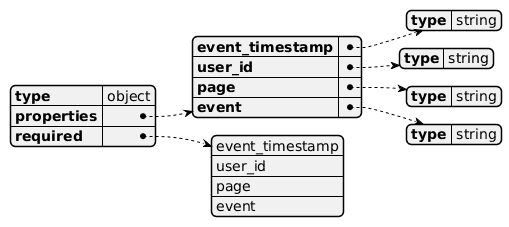
Рассмотрим примере кликстрима, т.е. потокового поступления данных о событиях пользовательского поведения на страницах сайта. Предположим, данные о самом пользователе: его идентификаторе, электронном адресе и имени попадают в топик под названием CorpAppsTopic. JSON-схема полезной нагрузки выглядит так:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Generated schema for Root",
"type": "object",
"properties": {
"event_timestamp": {
"type": "string"
},
"user_id": {
"type": "string"
},
"email": {
"type": "string"
},
"name": {
"type": "string"
}
},
"required": [
"event_timestamp",
"user_id",
"email",
"name"
]
}

Данные о непосредственного событиях пользовательского поведения, т.е. на какой странице сайта он что-то скачал, кликнул, просмотрел и пр., публикуются в топик test. Они тоже представлены в виде JSON-документов следующей структурой:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Generated schema for Root",
"type": "object",
"properties": {
"event_timestamp": {
"type": "string"
},
"user_id": {
"type": "string"
},
"page": {
"type": "string"
},
"event": {
"type": "string"
}
},
"required": [
"event_timestamp",
"user_id",
"page",
"event"
]
}
Данные в оба топика поступают непрерывным потоком, причем один и тот же пользователь может совершить от 1 до 10 событий на любых веб-страницах. Необходимо получить агрегированные данные о том, сколько событий совершил каждый пользователь и сколько видов событий совершено вообще.
Чтобы реализовать эту задачу, прежде всего надо написать код приложений-продюсеров, которые будут публиковать данные в Kafka. А, поскольку, данные о пользователе используются для генерации событий пользовательского поведения, одно и то же приложение будет одновременно и потреблять данные из одного топика Kafka, и публиковать их в другой. Схематично это будет выглядеть так:
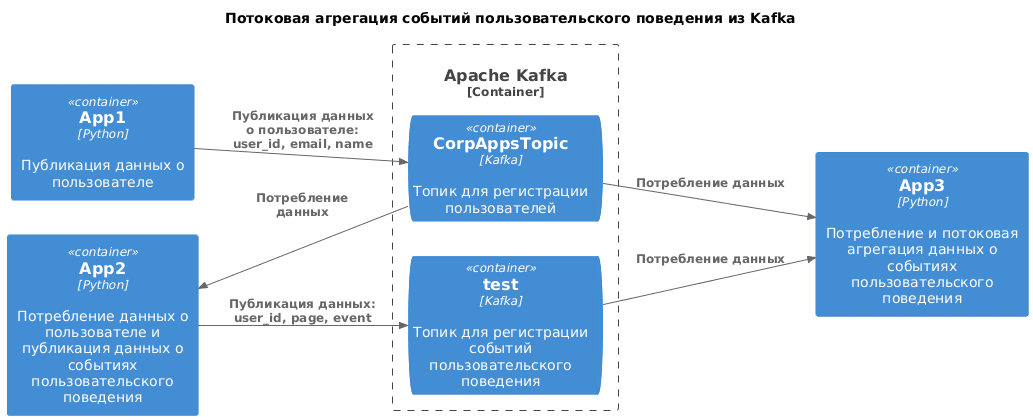
Скрипт PlantUML для отрисовки диаграммы:
@startuml
!include https://raw.githubusercontent.com/plantuml-stdlib/C4-PlantUML/master/C4_Container.puml
LAYOUT_LEFT_RIGHT()
title Потоковая агрегация событий пользовательского поведения из Kafka
Container(app1C, "App1", "Python", "Публикация данных о пользователе")
Container(app2C, "App2", "Python", "Потребление данных о пользователе и публикация данных о событиях пользовательского поведения")
Container(app3C, "App3", "Python", "Потребление и потоковая агрегация данных о событиях пользовательского поведения")
Container_Boundary(Kafka, "Apache Kafka") {
ContainerQueue(kafkaCorpAppsTopic, "CorpAppsTopic", "Kafka", "Топик для регистрации пользователей")
ContainerQueue(kafkaTest, "test", "Kafka", "Топик для регистрации событий пользовательского поведения")
}
Rel(app1C, kafkaCorpAppsTopic, "Публикация данных о пользователе: user_id, email, name")
Rel(kafkaCorpAppsTopic, app2C, "Потребление\nданных")
Rel(app2C, kafkaTest, "Публикация данных: user_id, page, event")
Rel(kafkaTest, app3C, "Потребление данных")
Rel(kafkaCorpAppsTopic, app3C, "Потребление данных")
@enduml
Разобравшись с топологией потоковой системы, далее реализуем код для публикации и потребления данных.
Публикация и потребление данных в Kafka
Как обычно, экземпляр Kafka у меня развернут в облачной платформе Upstash, а писать приложения я буду на Python, используя библиотеку kafka-python. Код приложения-продюсера, которое каждые 3 секунды генерирует фейковые данные о пользователях, выглядит так:
#установка библиотек
!pip install kafka-python
!pip install faker
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
from kafka import KafkaProducer
# Импорт модуля faker
from faker import Faker
from faker.providers.person.ru_RU import Provider
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
#batch_size=300
)
topic='CorpAppsTopic'
# создание объекта Faker с локализацией для России
fake = Faker('ru_RU')
fake.add_provider(Provider)
#бесконечный цикл публикации данных
while True:
#подготовка данных для публикации в JSON-формате
now=datetime.now()
event_timestamp=now.strftime("%Y-%m-%d %H:%M:%S")
email=fake.ascii_free_email()
name=fake.name()
user_id=str(hash(email))
# Создаем полезную нагрузку в JSON
data = {"event_timestamp": event_timestamp, "user_id": user_id, "email": email, "name": name}
#публикуем данные в Kafka
future = producer.send(topic, value=data)
print(f' [x] Опубликовано {data}')
#повтор через 3 секунды
time.sleep(3)
Идентификатор пользователя вычисляется как строка от результата применения хэш-функции к его емейлу.
Код приложения, которое потребляет эти данные о пользователе и случайным генерирует события на веб-страницах, выглядит так:
#установка библиотек
!pip install kafka-python
from kafka import KafkaProducer, KafkaConsumer
!pip install faker
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
# Импорт модуля faker
from faker import Faker
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
#batch_size=300
)
topic_to='test'
# Создание объекта Faker с использованием провайдера адресов для России
fake = Faker()
#списки веб-страниц
k=100 #количество веб-страниц
pages = [] # Инициализация списка для элементов заказа
us=[]
for i in range(k):
wpage=fake.url()
pages.append(wpage)
#объявление потребителя Kafka для чтения данных пользователей
consumer = KafkaConsumer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
group_id='a',
auto_offset_reset='earliest',
enable_auto_commit=True
)
topic_from='CorpAppsTopic'
#списки событий
events=['click', 'scroll', 'submit', 'download', 'focus']
consumer.subscribe([topic_from])
#бесконечный цикл потребления и публикации данных
for message in consumer:
try:
# распаковка сообщения
payload = message.value.decode("utf-8")
data_consumed = json.loads(payload)
print(f' [x] Получено {data_consumed}')
# парсинг сообщения
user_id = data_consumed['user_id']
email = data_consumed['email']
name = data_consumed['name']
x=random.randint(1,10) #случайное количество событий
for i in range(x):
#подготовка данных для публикации в JSON-формате
now=datetime.now()
event_timestamp=now.strftime("%Y-%m-%d %H:%M:%S")
page=random.choice(pages)
event=random.choice(events)
# Создаем полезную нагрузку в JSON
data_publish = {"event_timestamp": event_timestamp, "user_id": user_id, "page": page, "event": event}
#публикуем данные в Kafka
future = producer.send(topic_to, value=data_publish)
print(f' [x] Опубликовано {data_publish}')
except Exception as e:
# запись ошибок в лог-файл на Google Диске
error_str = f"Error: {str(e)}, Offset: {message.offset}, Value: {message.value}\n"
with open("dlq.txt", "a") as f:
f.write(error_str)
print(f"Error: {str(e)}")
Для потоковой агрегации данных из 2-х топиков надо написать еще одно приложение. Потреблять данные оно будет одновременно из разных топиков. Его код выглядит так:
# Установим необходимые библиотеки
!pip install kafka-python
from kafka import KafkaConsumer
!pip install kafka-python pandas
import json
import pandas as pd
# Объявление потребителя Kafka для чтения данных пользователей и событий
consumer = KafkaConsumer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
group_id='yx',
auto_offset_reset='earliest',
enable_auto_commit=True
)
# Подписываемся на топики
topic_from = 'CorpAppsTopic'
topic_to = 'test'
consumer.subscribe([topic_from, topic_to])
# Инициализация списков для хранения сообщений
messages_from = []
messages_to = []
# Бесконечный цикл потребления данных
for message in consumer:
try:
# Распаковка сообщения
payload = message.value.decode("utf-8")
data = json.loads(payload)
# Сортировка сообщений по топикам
if message.topic == topic_from:
messages_from.append(data)
elif message.topic == topic_to:
messages_to.append(data)
# Преобразуем сообщения в DataFrame
df_users = pd.DataFrame(messages_from)
df_events = pd.DataFrame(messages_to)
# Проверяем наличие столбцов 'id' и 'user_id'
if 'user_id' in df_users.columns and 'user_id' in df_events.columns:
# Объединяем данные по пользователям и событиям
merged_df = pd.merge(df_events, df_users, left_on='user_id', right_on='user_id')
# Агрегация по пользователям
user_event_counts = merged_df.groupby(['user_id', 'name', 'email']).size().reset_index(name='event_count')
# Агрегация по видам событий
event_counts = df_events.groupby('event').size().reset_index(name='count')
# Вывод результатов
print("\nСобытия по пользователям:")
print(user_event_counts)
print("\nКоличество видов событий:")
print(event_counts)
except Exception as e:
# Запись ошибок в лог-файл на Google Диске
error_str = f"Error: {str(e)}, Offset: {message.offset}, Value: {message.value}\n"
with open("dlq.txt", "a") as f:
f.write(error_str)
print(f"Error: {str(e)}")
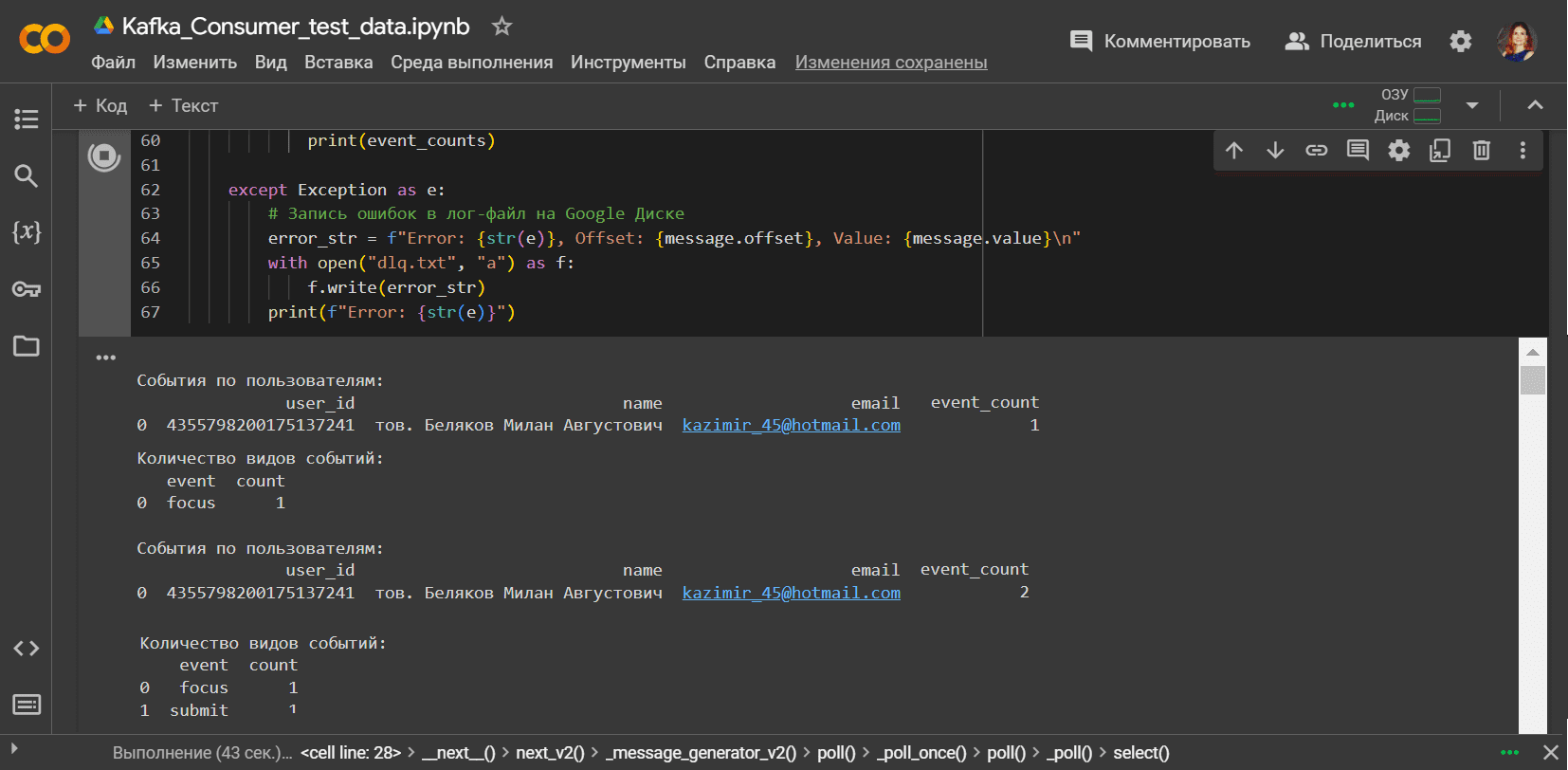
Чтобы вычислить, сколько событий совершил каждый пользователь, надо соединить данные из топика CorpAppsTopic с данными из топика test по ключу user_id. А чтобы понять, сколько событий каждого вида совершено, нужно сделать агрегацию данных из топика test с группировкой по полю event.
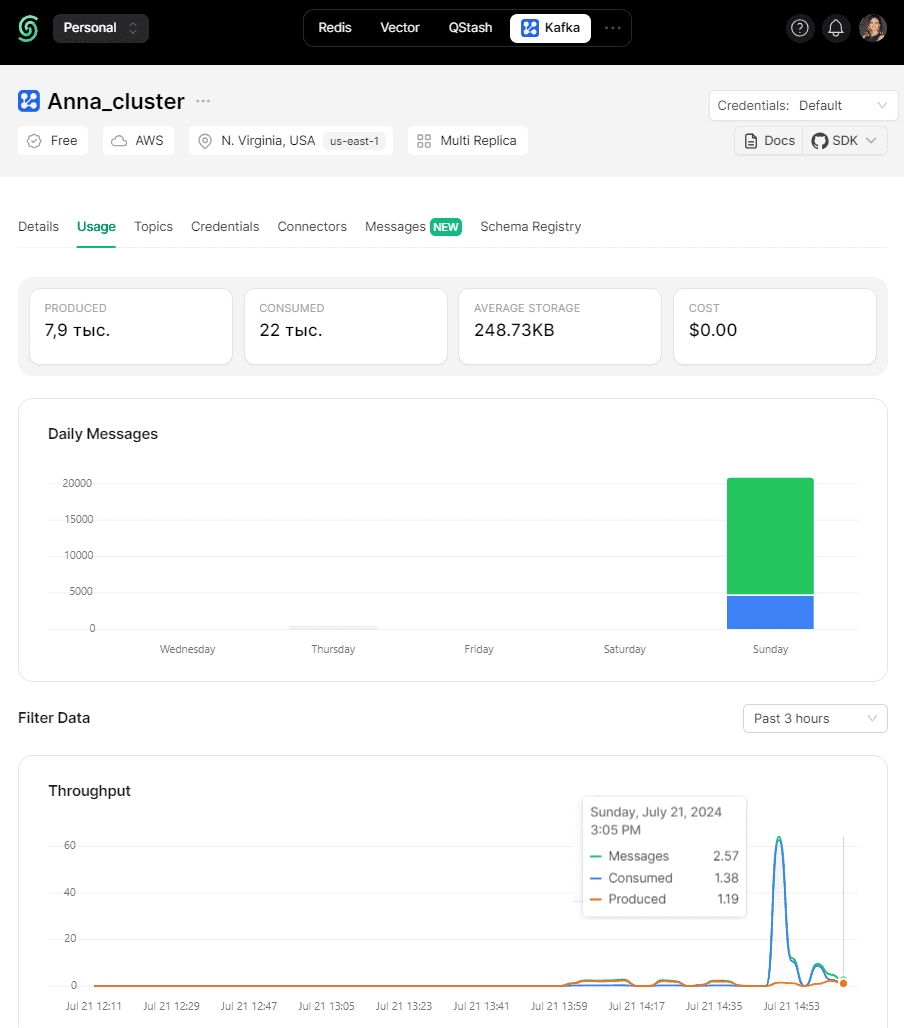
Разумеется, все события публикации и потребления данных можно посмотреть в GUI платформы Upstash, на которой развернут экземпляр Kafka.
Таким образом, чтобы реализовать эту довольно простую с точки зрения бизнес-постановки задачу, пришлось писать полноценный потребитель. Вместо этого можно использовать коннекторы потоковой базы данных RisingWave, о которой я писала здесь. Как это сделать, покажу завтра в новой статье.
Освойте все тонкости работы с Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: