 1522
1522 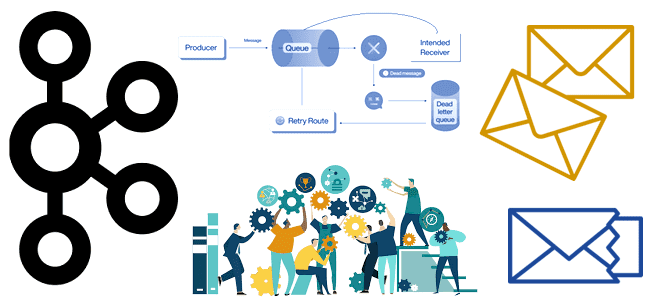
Содержание
Недавно мы писали про очереди недоставленных сообщений в Apache Kafka и RabbitMQ. Сегодня поговорим про стратегии обработки ошибок, связанные с DLQ-очередями в Kafka, а также рассмотрим, какие сообщения НЕ надо помещать в Dead Letter Queue.
4 стратегии работы с DLQ-топиками в Apache Kafka
Напомним, в Apache Kafka в очереди недоставленных сообщений (Dead Letter Queue, DLQ) скапливаются сообщения, которые не могут быть обработаны приложением-потребителем. Поскольку Apache Kafka, в отличие от RabbitMQ, не доставляет сообщения приложениям-потребителям, это обычно происходит из-за некорректного формата или схемы данных.
Таким образом, DLQ-очередь позволяет отделить обработку ошибок данных от обработки событий без остановки потокового конвейера. Существует несколько таких стратегий обработки сообщений, хранящихся в DLQ-очереди:
- повторная обработка, когда некоторые сообщения в DLQ надо обработать снова. Но сперва необходимо решить проблему, т.е. понять, почему сообщения попали в DLQ-очередь. Это можно сделать автоматически с помощью скрипта или разобраться вручную, а затем вернуть ошибку приложению продюсеру с запросом на повторную отправку исправленного сообщения. Здесь же можно применить расширенную аналитику для получения информации о проблемах потока данных в режиме реального времени. Например, использовать ksqlDB для вычислений статистики потока событий в реальном времени, такой как среднее количество сообщений об ошибках в час и других сведений, которые помогут понять характер данных конвейере с Kafka.
- отбрасывание некорректных сообщений после их предварительного анализа;
- остановка рабочего процесса, если некорректные сообщения критичны для бизнеса. Это действие может быть автоматизировано или выполняться дата-инженером вручную;
- игнорирование ошибок, когда DLQ-очередь просто наполняется без принятия каихх-либо мер. Такое бездействие допустимо в некоторых сценариях использования, например, при мониторинге общего поведения приложения Kafka. Но при этом стоит помнить, что топик Kafka не хранит данные вечно, а имеет политику очистки, о чем мы писали здесь и здесь, согласно которой сообщения удаляются из топика по истечении определенного времени. Поэтому стоит следить за DLQ-топиком, чтобы оперативно принимать меры в случае его нетипичного поведения, например, если он начинает наполняться слишком быстро.
Как уже было отмечено выше, помимо использования JMX для мониторинга DLQ-очереди, можно воспользоваться возможностями агрегирования ksqlDB и написать простое потоковое приложение для отслеживания скорости, с которой сообщения записываются в очередь. Создадим потоковую таблицу, используя стандартный синтаксис SQL-команд:
-- Register stream for each dead letter queue topic.
CREATE STREAM dlq_file_sink_06__01 (MSG VARCHAR) WITH (KAFKA_TOPIC='dlq_file_sink_06__01', VALUE_FORMAT='DELIMITED');
CREATE STREAM dlq_file_sink_06__02 (MSG VARCHAR) WITH (KAFKA_TOPIC='dlq_file_sink_06__02', VALUE_FORMAT='DELIMITED');
-- Consume data from the beginning of the topic
SET 'auto.offset.reset' = 'earliest';
-- Create a monitor stream with additional columns
-- that can be used for subsequent aggregation queries
CREATE STREAM DLQ_MONITOR WITH (VALUE_FORMAT='AVRO') AS \
SELECT 'dlq_file_sink_06__01' AS SINK_NAME, \
'Records: ' AS GROUP_COL, \
MSG \
FROM dlq_file_sink_06__01;
-- Populate the same monitor stream with records from
-- the second dead letter queue
INSERT INTO DLQ_MONITOR \
SELECT 'dlq_file_sink_06__02' AS SINK_NAME, \
'Records: ' AS GROUP_COL, \
MSG \
FROM dlq_file_sink_06__02;
-- Create an aggregate view of the number of messages
-- in each dead letter queue per minute window
CREATE TABLE DLQ_MESSAGE_COUNT_PER_MIN AS \
SELECT TIMESTAMPTOSTRING(WINDOWSTART(),'yyyy-MM-dd HH:mm:ss') AS START_TS, \
SINK_NAME, \
GROUP_COL, \
COUNT(*) AS DLQ_MESSAGE_COUNT \
FROM DLQ_MONITOR \
WINDOW TUMBLING (SIZE 1 MINUTE) \
GROUP BY SINK_NAME, \
GROUP_COL;
Эта агрегирующая таблица, которая может быть запрошена в интерактивном режиме, фактически представляет собой топик Kafka, данные из которого можно визуализировать, перенаправив на дэшборд. Также эту ksqlDB-таблицу можно использовать для управления оповещениями. Например, если в DLQ-очередь попадает более 5 сообщений в минуту, дата-инженер должен получать соответствующее уведомление. Для этого создадим топик DLQ_BREACH, на который подписывается сервис оповещения, и при получении любого события посылает уведомление:
CREATE TABLE DLQ_BREACH AS \
SELECT START_TS, SINK_NAME, DLQ_MESSAGE_COUNT \
FROM DLQ_MESSAGE_COUNT_PER_MIN \
WHERE DLQ_MESSAGE_COUNT>5;
Выборка данных из топика DLQ_BREACH c ksqlDB реализуется через простой SQL-запрос SELECT. Например, нужно получить время создания сообщения в DLQ-очереди, ее название и количество сообщений, попавших туда:
SELECT START_TS, SINK_NAME, DLQ_MESSAGE_COUNT FROM DLQ_BREACH;
Пример реализации DLQ-очередей в Kafka для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS смотрите в нашей новой статье.
Лучшие практики для очереди недоставленных писем в Apache Kafka
В реальности часто бывает так, что работа с DLQ-очередями в конвейерах Apache Kafka уходит на последний план и дата-инженеры не обрабатывают сообщения, попавшие в Dead Letter Queue. Или оповещения об ошибках получает только дежурный дата-инженер. Однако, согласно DataOps-подходу, знать об этом должны владельцы данных, а не только команда инфраструктуры. Поэтому оповещение должно уведомлять команду приложения-продюсера о том, что в конвейер поступили некорректные данные, и их нужно повторно отправить, предварительно исправив.
Если же в этом нет необходимости, и получение некорректных данных фактически не влияет на ход и результат бизнес-процессов, встает вопрос о целесообразности существования DLQ-топика в Kafka. Вместо сбора таких сообщений их можно сразу проигнорировать в исходном приложении-потребителе, чтобы сократить нагрузку на сеть, инфраструктуру и другие ресурсы.
Таким образом, при работе с DLQ-очередями в Kafka можно выделить следующие лучше практики:
- создать дэшборд с оповещениями, которые будут получать все заинтересованные лица (дата-инженер, владелец данных, команда приложения-продюсера) по используемым каналам (электронная почта, оповещения в Slack или другом мессенджере);
- определить стратегию обработки ошибок для каждого DLQ-топика Kafka, чтобы своевременно остановить конвейер данных, удалить некорректные сообщения или обработать их повторно;
- отправлять в DLQ только сообщения о фактических ошибках с данными, а не все ошибки. Например, за проблемы с подключением отвечает само приложение-потребитель, а продюсер и Kafka здесь не причем.
- сохранять исходные сообщения и записывать их в DLQ с дополнительными заголовками, такими как уровень ошибки и время ее возникновения, имя приложения-продюсера и прочие метаданные, которые упростят процессы отладки и повторной обработки событий;
- определить оптимальное количество DLQ-очередей, поскольку каждый топик Kafka занимает ресурсы. Хранить все ошибок в одном DLQ не удобно для дальнейшего анализа и повторной обработки, однако чрезмерное множество DLQ-топиков тоже сложно поддерживать. Более того, концепция DLQ фактически изменяет порядок обработки входящих данных и значительно усложняет автоматические конвейеры. Поэтому количество и варианты использования DLQ в Kafka надо подбирать под каждый конвейер с учетом его специфики и критичности для бизнеса. В частности, вместо DLQ-топиков в Apache Kafka можно использовать реестр схем для управления данными и предотвращения ошибок. Schema Registry от Confluent позволяет обеспечить очистку данных, чтобы предотвратить ошибки в полезной нагрузке от приложений-продюсеров, предоставляя корректную структуру сообщений и реализуя проверку схемы на стороне клиента. Например, Confluent Server обеспечивает дополнительную проверку схемы на стороне брокера, чтобы отклонить некорректные сообщения от приложения-продюсера, который не использует реестр схем. Подробнее о реестре схем Kafka мы писали здесь.
В заключение рассмотрим пару случаев, когда НЕ надо использовать DLQ-очередь в Kafka. К примеру, DLQ для регулирования пропускной способности конвейера данных, отправляя в очередь недоставленных сообщений часть данные в режиме пиковой нагрузки, нельзя назвать хорошей идеей. Поскольку Kafka не доставляет сообщения приложениям-потребителям, они сами потребляют их в своем темпе. Если объем входящих данных вырос, следует масштабировать потребителей и/или наращивать емкость хранилища Kafka, т.е. увеличивать объем дискового пространства, а не настраивать DLQ.
Аналогично, не следует использовать DLQ для хранения сведений о неудачных подключениях приложения-потребителя к Kafka. Вместо этого нужно решить проблему с подключением, а сообщения будут храниться в обычном топике согласно политике его очистки.
Освойте администрирование и эксплуатацию Apache Kafka и Flink для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Администрирование кластера Kafka
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

