
Представьте, что вы работаете в e-commerce. У вас есть 50 таблиц в Postgres (заказы, товары, пользователи, отзывы...), и каждую из них нужно переливать в ClickHouse по одной и той же схеме: Скачать -> Очистить -> Загрузить. Новичок создаст 50 файлов: dag_orders.py, dag_users.py, dag_items.py... В каждом файле будет одинаковый код,...

Если Postgres - это надежный банковский сейф, где каждая транзакция на вес золота, то ClickHouse - это промышленная мясорубка. Ему все равно, уникальны ли ваши записи (по умолчанию), он не поддерживает классические транзакции, но зато он умеет делать SELECT count(*) FROM hits по миллиарду строк за доли секунды. Для...

До этого момента все наши DAG-и жили по расписанию. schedule_interval='@daily' - это классика. Но современный бизнес не хочет ждать "утреннего отчета". Если данные прилетели в 14:00, отчет должен быть готов в 14:10, а не на следующее утро. Здесь мы сталкиваемся с фундаментальным конфликтом: Airflow - это Batch-инструмент (запускает задачи...

В прошлых статьях мы выяснили: если задача тяжелая и требует Java (Spark), мы используем SparkSubmitOperator. Но что делать, если у вас "тяжелый" Python? Типичная ситуация когда вы написали отличный код на Pandas внутри PythonOperator. На тестовом файле в 100 Мб все летало. В продакшене пришел файл на 10 Гб. Как...
Запуск по требованию Jupyter notebook и сохранение данных блокнотов .ipynb Этот гайд предназначен для тех кто использует эпизодически Jupyter Notebook и хочет иметь к ним доступ из Windows при этом оставляя возможность иметь доступ ко всем файлам блокнота и погасить Jupyter следующего раза. Итак приступим! Шаг 1: Подготовка...

Зачем в Apache AirFlow 3.0 добавлена поддержка Go и как работает этот экспериментальный SDK: возможности и ограничения разработки и запуска задач на компилируемом языке программирования. Мультиязычность в Apache AirFlow 3.0 Одной из ключевых новинок недавно выпущенного Apache AirFlow 3.0, о котором мы писали здесь, стала его мультиязычность. Теперь фреймворк поддерживает...

Как LLM упрощают работу дата-инженера: новые декораторы TaskFlow API в Apache Airflow для внедрения больших языковых моделей в DAG. Обзор Airflow AI SDK на основе Pydantic AI с практическим примером про анализ отзывов. ИИ в инженерии данных Мультимодальность современных инструментов машинного обучения, когда одна ML-модель может принимать на вход данные...

Можно ли при разработке конвейера Apache Beam использовать преобразования из SDK разных языков программирования и как это сделать, избежав типичных ошибок. Кросс-языковые преобразования и мультиязычные конвейеры Beam Как и многие популярные фреймворки для создания распределенных приложений обработки данных (Apache Flink, Spark и другие движки), Apache Beam поддерживает несколько языков. В...

Изоляция рабочих процессов и универсальное выполнение на удаленных машинах в обновленной клиент-серверной архитектуре, версионирование DAG, активы данных и изменения интерфейсов: главные новинки Apache AirFlow 3.0. Изоляция рабочих процессов и универсальное выполнение В марте 2025 года ожидается выпуск бета-релиза Apache AirFlow, а общедоступная версия (GA) выйдет в середине апреля. До этого...

Как библиотека PemJa реализует потоковый режим выполнения Flink-заданий, где UDF-функции Python выполняются в JVM, ускоряя обработку данных за счет исключения межпроцессного взаимодействия. Выполнение PyFlink-приложения в JVM Хотя Flink-приложение работает в JVM-среде, фреймворк позволяет писать код не только на Java и Scala. О том, как работает PyFlink, Python-интерфейс для Apache Flink,...
Почему можно программировать на Python для разработки JVM-приложений: как Java-фреймворки с Python API, такие как Apache Spark и Flink, транслируют Python-код, организуя межпроцессное взаимодействие. Способы трансляции Python-кода для исполнения в JVM Большинство фреймворков для разработки высоконагруженных приложений написаны на Java. Например, Apache Spark или Flink. При этом они предоставляют Python...
Как Apache Beam распараллеливает потоковые и пакетные конвейеры обработки данных, добавляя собственные операции к пользовательским преобразованиям. Смотрим на примере простого пакетного конвейера с ограниченным параллелизмом. Распараллеливание операций в Apache Beam Напомним, Apache Beam представляет собой унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить в любой...
Как получить спецификацию AsyncAPI из кода с помощью декораторов функций публикации и потребления сообщений средствами Python-библиотеки FastStream: простой пример потокового конвейера на Apache Kafka. Еще раз про FastStream и спецификацию AsyncAPI Вчера я рассказывала про Python-библиотеку FastStream для разработки потоковых конвейеров на Apache Kafka, RabbitMQ, NATS и Redis. Помимо мощного,...

Чем хороша Python-библиотека FastStream и как ее использовать для потоковой публикации данных в Apache Kafka: практический пример асинхронной отправки JSON-сообщений. О библиотеке FastStream Для Python-разработчиков есть довольно много библиотек, позволяющих взаимодействовать с Apache Kafka: kafka-python, confluent-kafka, Quix Streams и другие клиенты. О сравнении kafka-python и confluent-kafka я писала здесь, а...

Чем Apache Beam отличается от Apache Flink, что и когда выбирать, зачем их совмещать для реализации сложных конвейеров обработки больших объемов данных с помощью распределенных stateful-приложений, и как это работает. Сходства и отличия Apache Beam и Flink Хотя Apache Beam является унифицированной моделью определения пакетных и потоковых конвейеров параллельной обработки данных,...
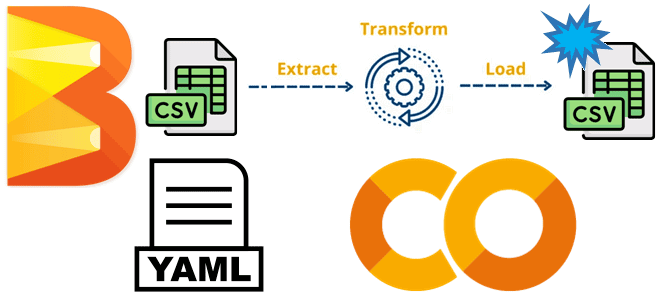
Как написать конвейер обработки данных Apache Beam, задав цепочку преобразований в YAML-конфигурации: практический пример фильтрации и агрегации платежей из CSV-файла. Пример разработки и запуска YAML-конвейера Apache Beam в Google Colab Недавно я рассказывала про Apache Beam – унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить...
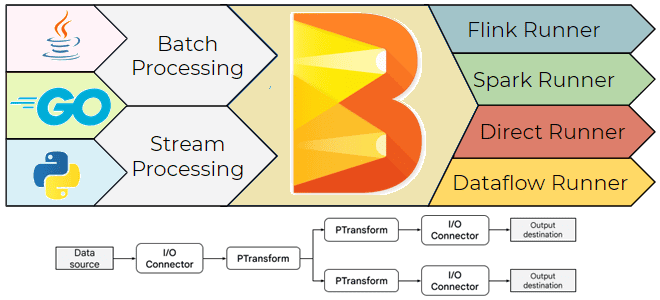
Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных. Что такое Apache Beam и зачем он нужен Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения...
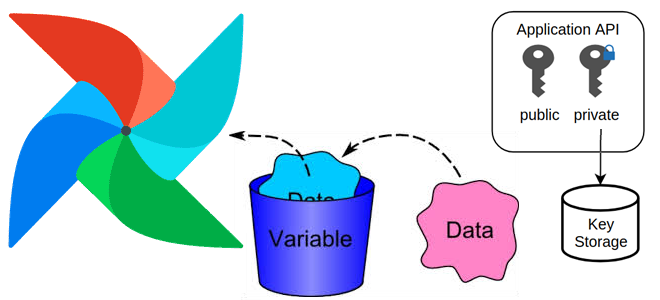
Зачем нужны переменные в Apache AirFlow, какие они бывают, как создать переменную и использовать ее: примеры и рекомендации для эффективной дата-инженерии. Зачем нужны переменные в Apache AirFlow, и какие они бывают Чтобы хранить информацию, которая редко меняется, например, ключи API, пути к конфигурационным файлам, в Apache Airflow используются переменные. Переменные...

Как Quix Streams реализует отказоустойчивую stateful-обработку потоковых датафреймов из топиков Kafka с помощью встроенного key-value хранилища состояний RocksDB: практический пример. Потоковый stateful-конвейер на Apache Kafka и Quix Streams Продолжая знакомиться с библиотекой Quix Streams, которая позволяет получить потоковые датафреймы из данных в топиках Kafka, сегодня разберем, как здесь организована работа...

Быстрая и простая обработка потоков сообщений в одном приложении с Quix Streams вместо Kafka Streams: практический пример на Python с обогащением и фильтрацией данных. Практический пример потокового конвейера с Apache Kafka и Quix Streams Сегодня я познакомилась с Quix Streams - очередной замечательной библиотекой для создания потоковых конвейеров обработки данных...