 1327
1327 
Содержание
Spark Structured Streaming – это библиотека фреймворка Apache Spark для обработки непрерывных потоковых данных, основанная на модуле Spark SQL и API его основных структур данных – Dataframe и Dataset, поддерживаемыми в языках Java, Scala, Python и R.
Как устроен Apache Spark Structured Streaming: основные принципы работы
Модуль Apache Spark Structured Streaming был впервые выпущен в версии фреймворка 2.0, чтобы устранить недостатки своего предшественника – Spark Streaming. Библиотека структурированной потоковой передачи позволяет работать со стандартным инструментарием SQL-запросов через DataFrame API или операции Scala в DataSet API. Structured Streaming включает масштабируемый и отказоустойчивый механизм потоковой обработки Big Data, представляя собой улучшенный способ обработки непрерывной потоковой передачи больших данных без проблем с обработкой ошибок и сбоев. Движок Spark SQL заботится о том, чтобы поток данных обрабатывался постепенно и непрерывно, обновляя конечный результат по мере поступления новых потоковых данных [1].
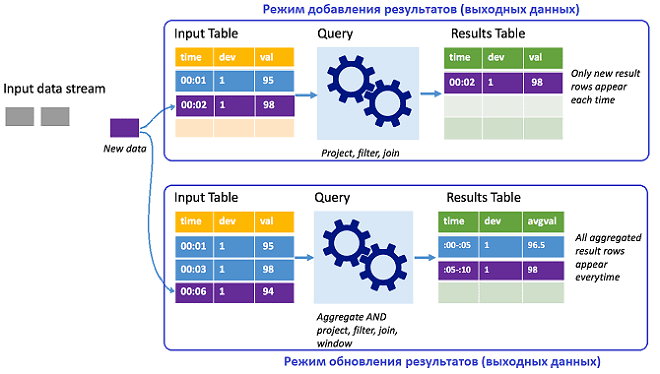
Структурированная потоковая передача Spark представляет поток данных в виде неограниченной по глубине таблицы, которая продолжает увеличиваться по мере поступления новых данных и непрерывно обрабатывается с помощью долго выполняющегося запроса. Результаты обработки записываются в выходную таблицу. В отличие от Spark Streaming, в структурированная потоковая передача не поддерживает микро-пакетный режим, поэтому она гораздо ближе к действительно потоковой обработке данных в реальном времени. Интервал триггера, по умолчанию равный нулю, задает расписание для обработки данных во входной таблице. Таким образом, как только Spark Structured Streaming завершает обработку выполнения предыдущего запроса, запускается следующая обработка новых полученных данных. Задав запуск триггера с временной задержкой, можно обрабатывать потоковые данные в пакетном режиме по расписанию. Представление результатов зависит от режима [2]:
- добавление — выходные таблицы содержат только те данные, которые были новыми с последнего момента обработки запроса;
- обновление – выходная таблица обновляется каждый раз при наличии новых данных и включает всю информацию с момента начала потокового запроса.
Как и в Apache Spark Streaming, отказоустойчивость обеспечивается с помощью механизма контрольных точек, гарантирующего непрерывную обработку потоков даже при сбое узлов. Контрольные точки хранят ход выполнения запроса структурированной потоковой передачи, о чем мы подробно рассказываем здесь и здесь. Также используется упреждающее протоколирование в виде WAL-журнала (Write Ahead Log), куда записываются принятые данные, которые были получены, но еще не обработаны запросом. Таким образом, в случае сбоя, и обработка данных перезапускается из WAL, не допуская потерю событий, полученных от источника [2].
Как работают приложения структурированной потоковой передачи Спарк
Приложение Spark Structured Streaming создает продолжительный запрос, в рамках которого ко входным данным применяются SQL-операции выбора, агрегации, оконные операции, соединения и прочие аналитические вычисления. Результаты выводятся в хранилище файлов или данных, а также в консоль для отладки в локальной среде и в таблицу в памяти. Как и в случае Spark Streaming, приложение структурированной потоковой передачи чаще всего создается локально в JAR-файле, а затем развертывается в кластере или запускается через POST-операцию в REST API Apache Livy [2].
Главные плюсы структурированной потоковой передачи по сравнению со Spark Streaming
Основными преимуществами, которые модуль Spark Structured Streaming предоставляет разработчику распределенных приложений потоковой обработки Big Data, по сравнению со своим предшественником, являются следующие:
- API DataFrame обеспечивает более высокий уровень абстракции, позволяя пользователям гибко манипулировать данными, включая поддержку всех этапов оптимизации SQL-запросов в Spark;
- наличие данных о времени, когда событие случилось в реальном мире повышает точность вычислений и позволяет обрабатывать события, поступившие с опозданием;
- повышенная надежность и отказоустойчивость распределенных приложений благодаря гарантии строго однократной семантики доставки сообщений (exactly once) за счет не только механизма контрольных точек, но и условий восстановления после любой ошибки – воспроизводимость источника данных и поддержка идемпотентных операций повторной обработки у потребителей в случае сбоя;
- отсутствие деления на микро-пакеты ускоряет обраотку данных и еще более приближает ее к по-настоящему потоковому режиму в реальном времени практически без задержек.
Подробнее об отличиях Structured Streaming от Spark Streaming читайте здесь.
Источники
- https://www.upsolver.com/blog/apache-spark-and-spark-structured-streaming-compared
- https://docs.microsoft.com/ru-ru/azure/hdinsight/spark/apache-spark-structured-streaming-overview