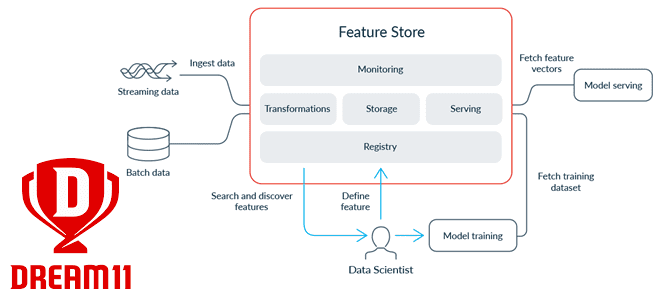
Современные ML-системы представляют собой сложные комплексные платформы из множества компонентов, одним из которых является хранилище фичей для моделей машинного обучения. Индийская gamedev-компания Dream11 делится своим опытом, как построить такое Feature Store на базе Apache HBase с Phoenix, а также RonDB и Kafka. Что такое хранилище фичей и зачем это Dream11...

Недавно на примере ИТ-компании Salesforce мы рассказывали про вторичную индексацию таблиц Apache HBase с помощью Phoenix – средства обращения к NoSQL-хранилищу через SQL-запросы. В продолжение этого кейса, сегодня рассмотрим, как были перепроектированы глобальные вторичные индексы для обеспечения более высокого уровня согласованности, чем предлагает Apache Phoenix. Реализация вторичных индексов в таблицах...

В Apache HBase индексация таблиц возможна только по одному полю. Обойти это ограничение позволяет Apache Phoenix - инструмент обращения к NoSQL-хранилищу средствами SQL-запросов. В этой статье для дата-инженеров, архитекторов ИТ-решений и аналитиков данных рассмотрим типы вторичной индексации таблиц HBase в Phoenix и проблемы согласованности вторичных индексов, с которыми столкнулись специалисты...

Для дата-инженеров и аналитиков про манипулирование данными в Apache Hadoop HDFS средствами SQL-запросов с помощью удобных инструментов. Apache Phoenix для обращения к таблицам NoSQL-хранилища HBase через SQL-запросы из графического интерфейса Hue. Как обратиться к таблицам HBase через SQL-запросы с Phoenix Apache HBase как хранилище данных над Hadoop HDFS предоставляет множество...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...

Сегодня мы рассмотрим еще один инструмент стека SQL-on-Hadoop: Apache Phoenix, позволяющий выполнять SQL-запросы к нереляционной СУБД HBase. Читайте в нашей статье, что представляет собой этот исполнительный механизм, как он работает и чем отличается от других Big Data решений подобного класса (Cloudera Impala, Apache Hive и Drill). Также мы собрали для...