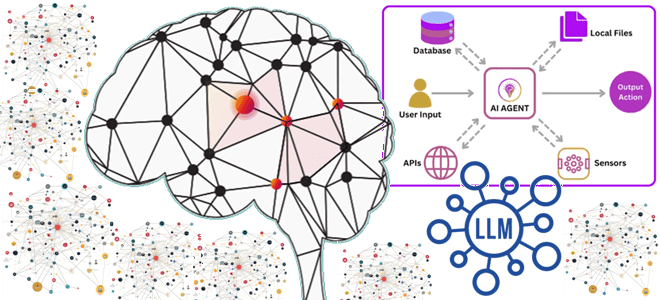
Что не так с векторным RAG: обогащение LLM данными из графовых баз с помощью MCP-протокола, вычислительных движков и коннекторов для построения ML-системы агентского ИИ. Что такое графовый RAG для LLM и ИИ-агентов Большие языковые модели (LLM, Large Language Model) и основанные на них системы агентского ИИ активно используют векторные базы...
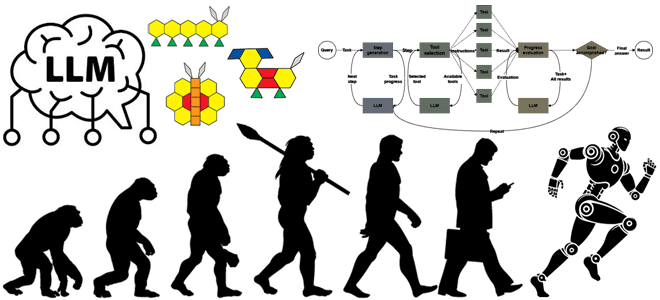
Как развивались системы агентского ИИ, из каких компонентов они состоят, каковы их типовые архитектуры и чем отличаются друг от друга топологии построения рабочих процессов LLM. История развития систем агентского ИИ Развитие и практическое внедрение больших языковых моделей (LLM, Large Language Model) привело к появлению систем агентского ИИ, где LLM динамически...
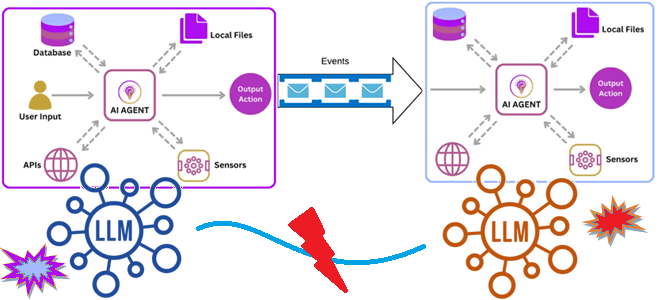
Как связать ИИ-агентов: событийно-ориентированная архитектура и потоковая передача событий для интеграции доменных LLM в мультиагентную систему. Зачем нужна интеграция ИИ-агентов О проблеме изоляции и рассинхронизации данных в корпоративных хранилищах мы уже писали здесь. Похожая ситуация наблюдается и при внедрении систем агентского ИИ, где большие языковые модели (LLM, Large Language Model)...
Почему MCP-серверы с технологиями потоковой передачи событий в LLM стали трендом: примеры обогащения ИИ-агентов контекстом из Kafka. Внедрение MCP в Confluent Cloud для взаимодействия с Apache Kafka Хотя MCP-протокол, позволяющий ML-модели новыми контекстными данными, что необходимо для больших языковых моделей (LLM, Large Language Model), довольно прост с технической точки зрения,...

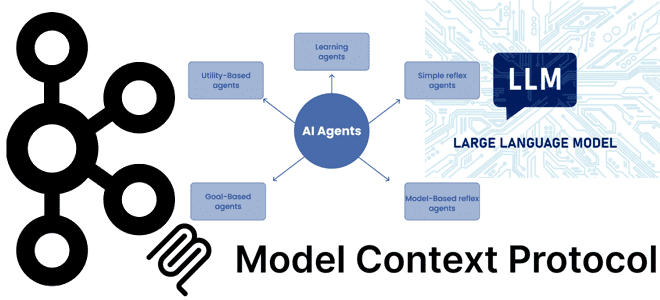
Как улучшить интеграцию LLM в бизнес-процессы и информационные системы через стандартизированную передачу контекстной информации: текстовый MCP-протокол для LLM. Что контекстный протокол модели и почему он важен для LLM Одно из ключевых отличий популярных ИИ-инструментов, больших языковых моделей (LLM, Large Language Model) – это их способность генерировать ответы с учетом контекста....

Как LLM упрощают работу дата-инженера: новые декораторы TaskFlow API в Apache Airflow для внедрения больших языковых моделей в DAG. Обзор Airflow AI SDK на основе Pydantic AI с практическим примером про анализ отзывов. ИИ в инженерии данных Мультимодальность современных инструментов машинного обучения, когда одна ML-модель может принимать на вход данные...

Чем ML-сценарии работы с данными отличаются от типовых аналитических нагрузок и почему колоночные форматы не справляются с ними: сложности Parquet и ORC в хранении данных для машинного обучения. Почему колоночные форматы не справляются со всеми ML-сценариями Хотя колоночный формат хранения данных хорошо подходит для многих современных сценариев, таких как машинное...
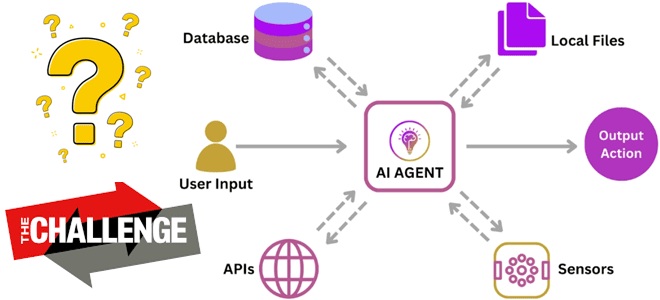
Чем хорош агентский ИИ, какие риски и проблемы с ним связаны, и как их избежать: технические и организационные меры внедрения ML-систем в реальный бизнес. Что сдерживает внедрение агентского ИИ Мы уже писали об агентском ИИ, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без...

Почему генеративный ИИ основан на потоковой обработке данных и EDA-архитектуре, для чего оценивать качество LLM-модели и как построить такую систему мониторинга: подходы и технологии. О важности потоковой обработки данных и EDA-архитектуры для LLM-систем Все больше современных бизнес-приложений включают в себя большие языковые модели (LLM, Large Language Model), чтобы автоматизировать поддержку...
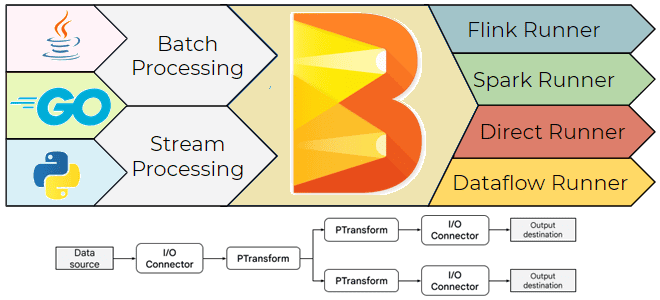
Что такое Apache Beam, зачем он нужен, чем полезен дата-инженеру и как его использовать: архитектура, принципы работы и примеры построения пакетных и потоковых конвейеров обработки данных. Что такое Apache Beam и зачем он нужен Хотя выбор технологического стека – один из важнейших вопросов архитектурного проектирования, иногда требуется универсальное решение построения...
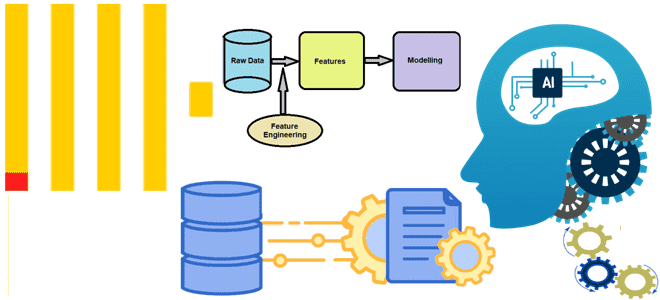
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...

Как решать задачи машинного обучения в Greenplum с агентом gpMLBot и расширением PostgresML: возможности, ограничения и примеры. Что такое gpMLBot: Greenplum Automated Machine Learning Agent Чтобы использовать Greenplum как хранилище данных в задачах машинного обучения, в этой БД поддерживаются соответствующие механизмы. Одним из них является библиотека Apache MADlib, о которой...
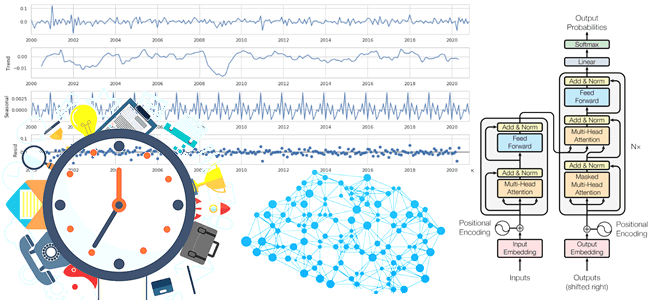
Почему генеративный ИИ хорошо подходит для прогнозирования временных рядов, как архитектура трансформеров учитывает влияние внешних переменных и сезонных факторов на измерения, и какие нейросетевые модели можно попробовать для этих задач. Проблемы прогнозирования временных рядов и их нейросетевые решения Прогнозирование временных рядов всегда было востребованной задачей в различных отраслях бизнеса. Временной...
Зачем Databricks выпустил Arc, чем это отличается от Splink, и как эти инструменты позволяют решать проблему связывания данных с помощью алгоритмов машинного обучения. Как работает связывание данных Продолжая разговор про качество данных и разрешение сущностей (entity resolution) , сегодня подробно рассмотрим этап связывания записей с использованием логики на основе правил...
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
Что такое барьерный режим выполнения в Apache Spark, чем он отличается от вычислительной модели MapReduce, как связан с глубоким машинным обучением и где используется на практике. Что такое барьерный режим выполнения в Apache Spark Способ выполнения заданий Spark определяется режимом выполнения приложения, заданным на уровне фреймворка. На платформе. Именно от...
Что такое алгоритм k-medoids, чем он отличается от k-means и как этот метод кластеризации применяется для анализа графов: принципы и инструменты. Что такое медоид и как устроен алгоритм кластеризации k-medoids Кластеризация — это метод машинного обучения для поиска кластеров или сообществ в наборе данных. Цель в том, чтобы найти кластеры,...
Почему безопасность ML-систем становится все более важным вопросом и как ее обеспечить: MLOps-подходы, практики и технологии защиты данных, моделей машинного обучения, а также вычислительных и инфраструктурных конвейеров. Защита данных для машинного обучения В связи с активным внедрением система машинного обучения в производственное использование, вопрос безопасности становится все более актуальным. ML-системы...

Зачем управлять трансферным обучением больших языковых моделей и что входит в это управление: знакомимся с расширением MLOps для LLM под названием LLMOps. Что такое LLMOps Большие языковые модели, воплощенные в генеративных нейросетях (ChatGPT и прочие аналоги), стали главной технологией уходящего года, которая уже активно используется на практике как частными лицами,...

Что представляет собой MLOps-платформа Tecton и как запустить на ней конвейеры машинного обучения, используя провайдер Tecton-AirFlow, чтобы управлять ресурсами Tecton в этом ETL-оркестраторе. Что такое Tecton и при чем здесь MLOps Поскольку концепция MLOps направлена на безбарьерную автоматизацию всех этапов жизненного цикла систем машинного обучения, для этого нужны специализированные средства....