Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...
5 уязвимостей Apache Spark за последние 3 года

От межсайтового скриптинга до внедрения вредоносного кода: какие проблемы информационной безопасности были обнаружены и исправлены в Apache Spark в 2023, 2022 и 2021 годах. Последние известные и исправленные проблемы информационной безопасности Apache Spark Недавно мы писали о механизмах обеспечения информационной безопасности в Apache Spark. Однако, несмотря на наличие этих средств,...
Apache Spark 3.4.1: обзор отладочного релиза, выпущенного в июне 2023

23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...
Spark Connect в релизе 3.4: новые возможности для разработчика
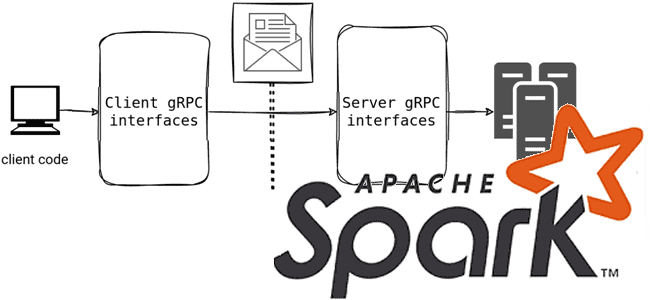
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...
DLQ в Kafka для AVRO-сообщений в Spark-приложении с библиотекой ABRiS
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....
Аккумуляторы в Apache Spark: что это и как их использовать?
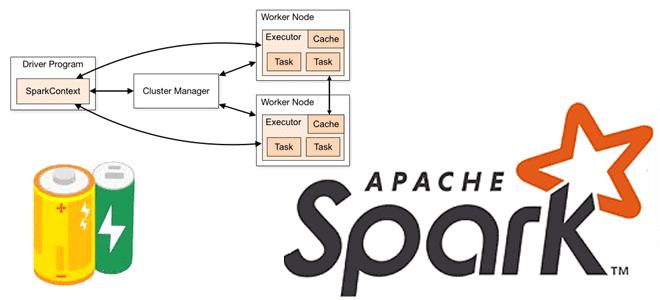
Что такое аккумуляторы в Apache Spark, чем они отличаются от широковещательных переменных и какова польза от этих концепций при разработке распределенных приложений и их использовании в кластере. Широковещательные переменные vs аккумуляторы В любой распределенной среде возникает задача сведения локальных результатов вместе. На практике, ее решение не всегда является простым. Например,...
3 способа прочитать данные из Kafka с помощью Spark

Как Spark-приложение может прочитать данные из топиков Kafka: обзор вариантов и способов их использования. А также рассмотрим, почему Spark Structured Streaming заменила прямой поток и подход на основе приемника. Прямой поток и подход на основе приемника Будучи мощным фреймворком разработки распределенных приложений, Apache Spark позволяет считывать данные в потоковом режиме...
Как посмотреть GUI приложения Apache Spark в Google Colab с ngrok

Сегодня посмотрим, как запустить Spark-приложение в Google Colab и увидеть сведения о его выполнении в веб-интерфейсе на удаленной машине, тунеллированной с помощью утилиты ngrok. Проброска туннеля в Google Colab с ngrok для Spark-приложения Хотя назвать Google Colab удобной средой для разработки приложений или исследования данных, нельзя, им часто пользуются аналитики...
Как механизм AQE выполняет динамическое объединение разделов в Apache Spark
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...
Средства обеспечения безопасности в приложениях Apache Spark

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...