Практическая демонстрация потокового SQL-конвейера, который преобразует данные, потребленные из Apache Kafka, и записывает результаты в Elasticsearch, используя Debezium-коннекторы и задания Apache Flink в облачной платформе Decodable.
Потребление сообщений из Apache Kafka
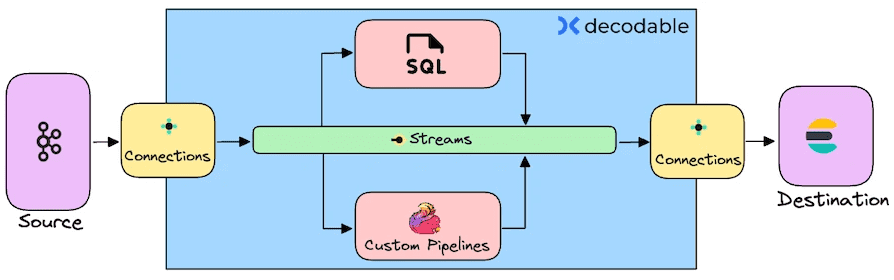
Я уже показывала пример интеграции Apache Kafka и Elasticsearch с помощью sink-коннектора, а также конвейер с ClickHouse Cloud. Сегодня совместим некоторые из этих прежних работ, чтобы протестировать облачную платформу Decodable на базе Apache Flink и Debezium. Она является полностью управляемым сервисом, который обеспечивает обработку данных в реальном времени. С Decodable можно получать данные из различных источников и направлять их в разные системы-приемники, а также преобразовывать и дополнять эти потоковые данные с помощью SQL или языка программирования на основе JVM (Java, Scala). Я буду использовать именно SQL в качестве основного средства построения потокового конвейера, суть которого состоит в извлечении данных из топика Kafka, их преобразовании и записи в Elasticsearch.
Как обычно, данные в Kafka, развернутой на платформе Upstash, буду публиковать с помощью простого Python-приложения, запускаемого в Google Colab, со следующим исходным кодом:
#установка библиотек
!pip install kafka-python
!pip install faker
#импорт модулей
import json
import random
from datetime import datetime
import time
from time import sleep
from kafka import KafkaProducer
# Импорт модуля faker
from faker import Faker
# объявление продюсера Kafka
producer = KafkaProducer(
bootstrap_servers=[kafka_url],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username=username,
sasl_plain_password=password,
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
#batch_size=300
)
topic='test'
# Создание объекта Faker с использованием провайдера адресов для России
fake = Faker()
#списки полей в заявке
products = ['яблоки желтые', 'малина', 'вода', 'хлеб белый','хлеб серый', 'креветки', 'форель', 'апельсины', 'кета','курица','яйцо перепелиное','яйцо куриное','лаваш',
'булка сдобная','булка сахарная','помидоры бакинские','помидоры чери','огурцы','перец сладкий','перец острый','перец болгарский','мандарины','укроп свежий',
'укроп сушеный','клубника свежая','клубника мороженная','мороженое','картошка','морковь', 'свекла','пангасиус','семга','кальмар замороженный','горошек зеленый',
'смородина черная','смородина красная','соль поваренная пищевая йодированная','чай черный байховый','чай зеленый','чай красный','кофе','кофе с молоком','какао',
'молоко','кефир','сыр с плесенью','сыр плавленый','сыр твердый','сыр мягкий','яблоки красные','яблоки зеленые','яблоки сушеные','икра красная',
'икра черная','икра заморская баклажанная','масло сливочное','масло оливковое','масло подсолнечное','масло кокосовое','орех грецкий','орех бразильский',
'лист лавровый','куркума','кукуруза','печенье сладкое','пряники сдобные','тесто слоеное','варенц','ряженка','снежок','шоколад молочный']
questions = ['payment', 'delivery', 'discount', 'vip', 'staff']
#бесконечный цикл публикации данных
while True:
#подготовка данных для публикации в JSON-формате
now=datetime.now()
producer_timestamp=now.strftime("%Y-%m-%d %H:%M:%S")
content = ''
theme = ''
corp = 0
#виды заявок - корпоративная или личная
corp = random.choice([1,0])
if corp==1 :
name=fake.company()
else:
name=fake.name()
#случайный выбор заявка или вопрос
subject=random.choice(['app', 'question'])
# Добавление дополнительных данных для заголовка и тела сообщения в зависимости от темы заявки
if subject == 'question':
theme = random.choice(questions)
content = 'Hello, I have a question about ' + theme
else:
theme = 'app'
kol = random.randint(1, 10) # Число позиций в заказе
items = [] # Инициализация списка для элементов заказа
for i in range(kol):
items.append({'name': random.choice(products), 'quantity': str(random.randint(1, 100))})
content = items
# Создаем полезную нагрузку в JSON
data = {"producer_timestamp": producer_timestamp, "name": name, "subject": subject, "content": content}
#публикуем данные в Kafka
future = producer.send(topic, value=data)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
print(f' [x] Payload {data}')
#повтор через 3 секунды
time.sleep(3)
Этот Python-скрипт каждые 3 секунды генерирует и публикует в Kafka клиентские обращения от компаний или частных лиц: заявки на покупку товаров в интернет-магазине или вопросы по работе магазина.
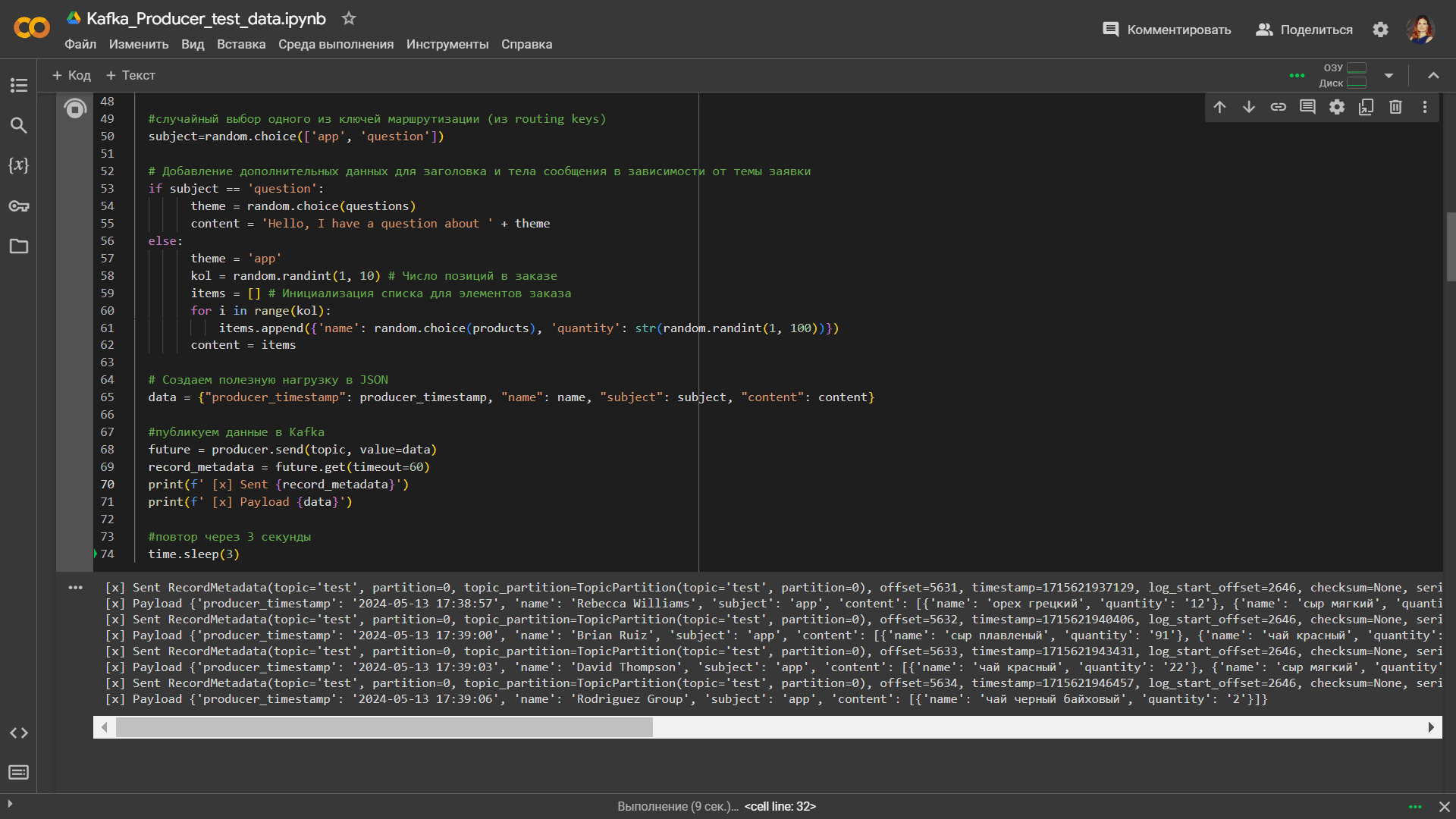
Схема полезной нагрузки сообщения в формате JSON выглядит так:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Generated schema for Root",
"type": "object",
"properties": {
"producer_timestamp": {
"type": "string"
},
"name": {
"type": "string"
},
"subject": {
"type": "string"
},
"content": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"quantity": {
"type": "string"
}
},
"required": [
"name",
"quantity"
]
}
}
},
"required": [
"producer_timestamp",
"name",
"subject",
"content"
]
}
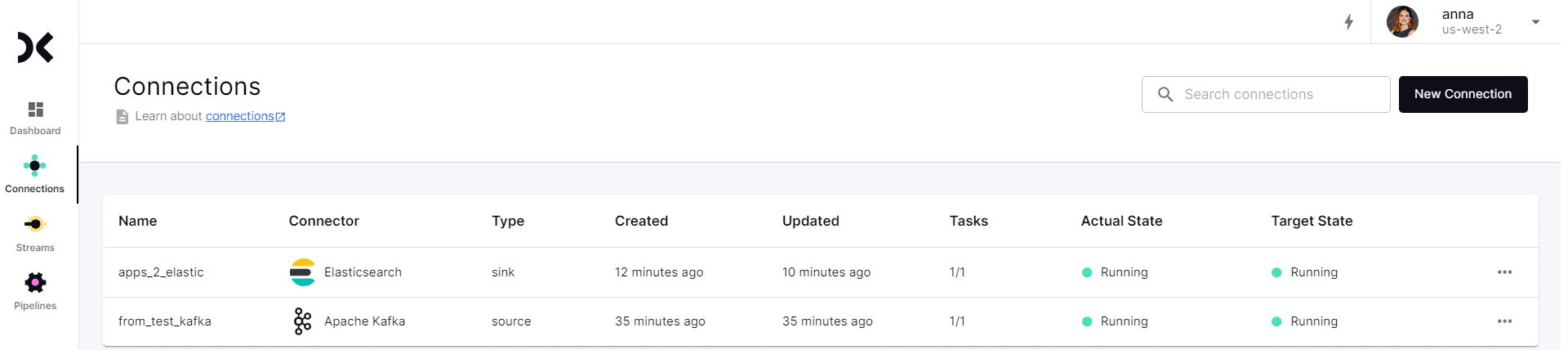
Далее получим эти данные с помощью Debezium-коннектора в платформе Decodable. Поскольку Decodable основана на Apache Flink, она использует именно его термины при создании потокового конвейера. В частности, сперва нужно создать коннекторы к источникам и приемникам данных, настроив учетные записи подключения к внешним системам. Decodeable создает сетевые подключения к ресурсам, которые указаны в подключениях. Я создала 2 коннектора: Kafka как источник данных и Elasticsearch как приемник.
Преобразование потока данных и публикация в Elasticsearch
Предположим, нужно отправлять в индекс Elasticsearch под названием apps_index не все подряд обращения, а только те, которые являются заявками на покупку, а также количество позиций в каждой заявке. Чтобы сделать это, необходимо создать новый поток, который извлекает данные из исходного потока from_test_kafka, немного преобразует и обогащает их с помощью следующего SQL-запроса:
insert into apps_from_kafka select producer_timestamp, name, CARDINALITY(content) AS items_quantity, content from from_test_kafka WHERE subject='app'
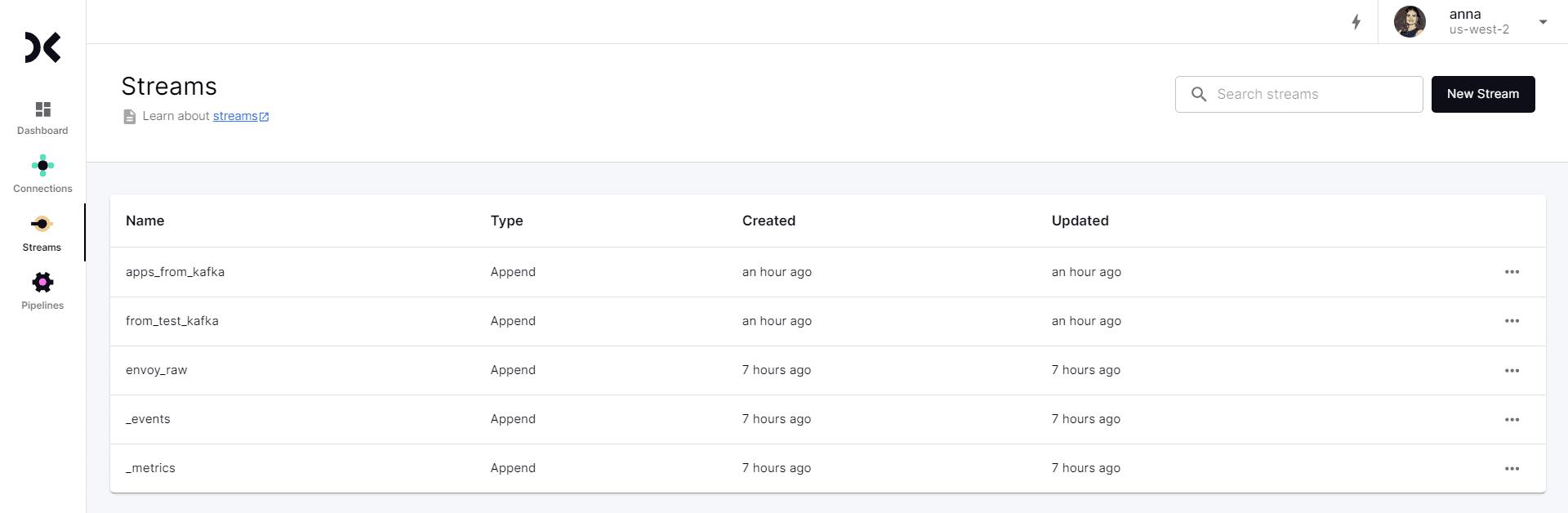
Протестировав и настроив источник и приемник данных, следует запустить оба подключения и сам настроенный конвейер, чтобы он работал непрерывно.
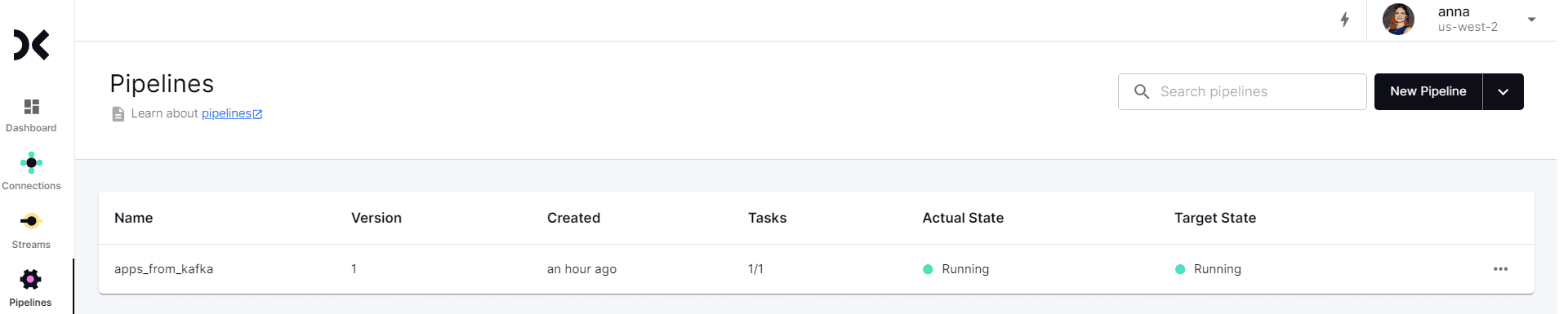
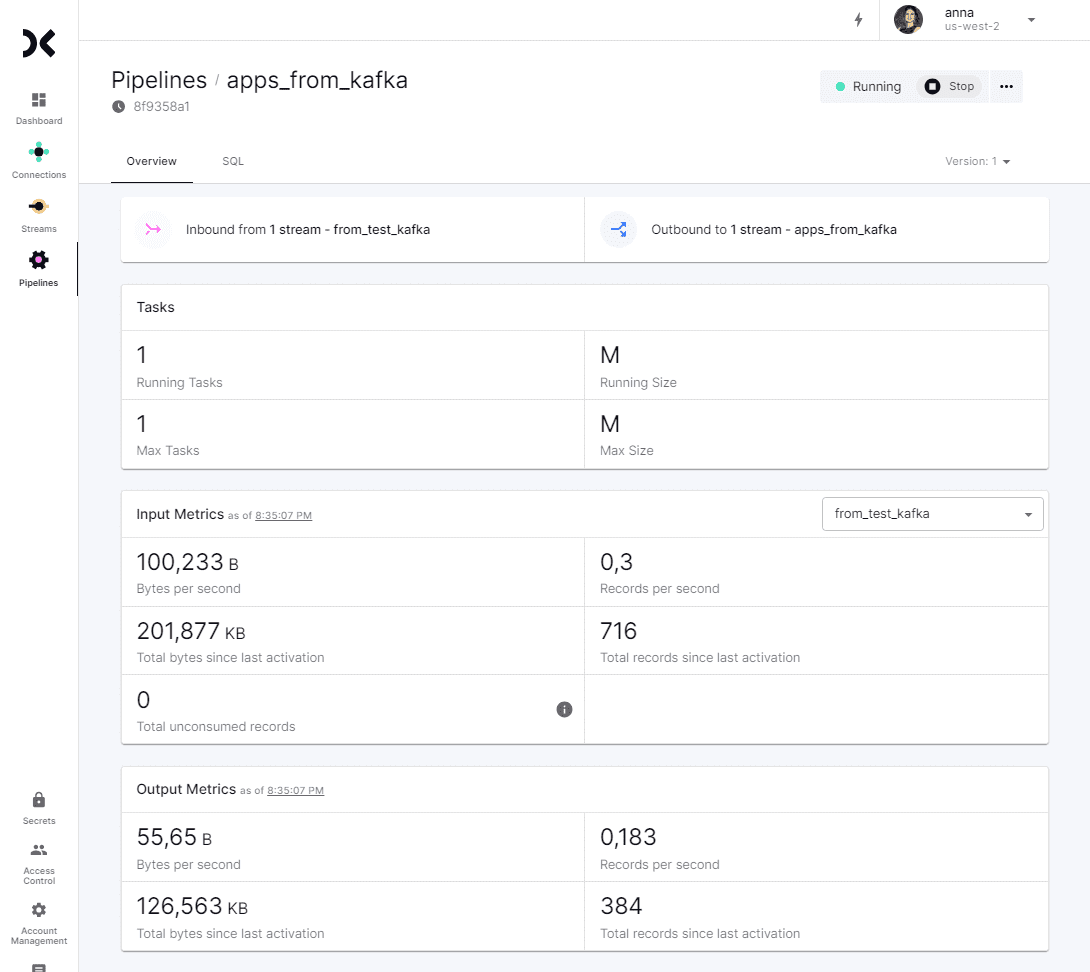
Статистика по принятым из источника и отправленным в приемник данным отображается в свойствах созданного конвейера.
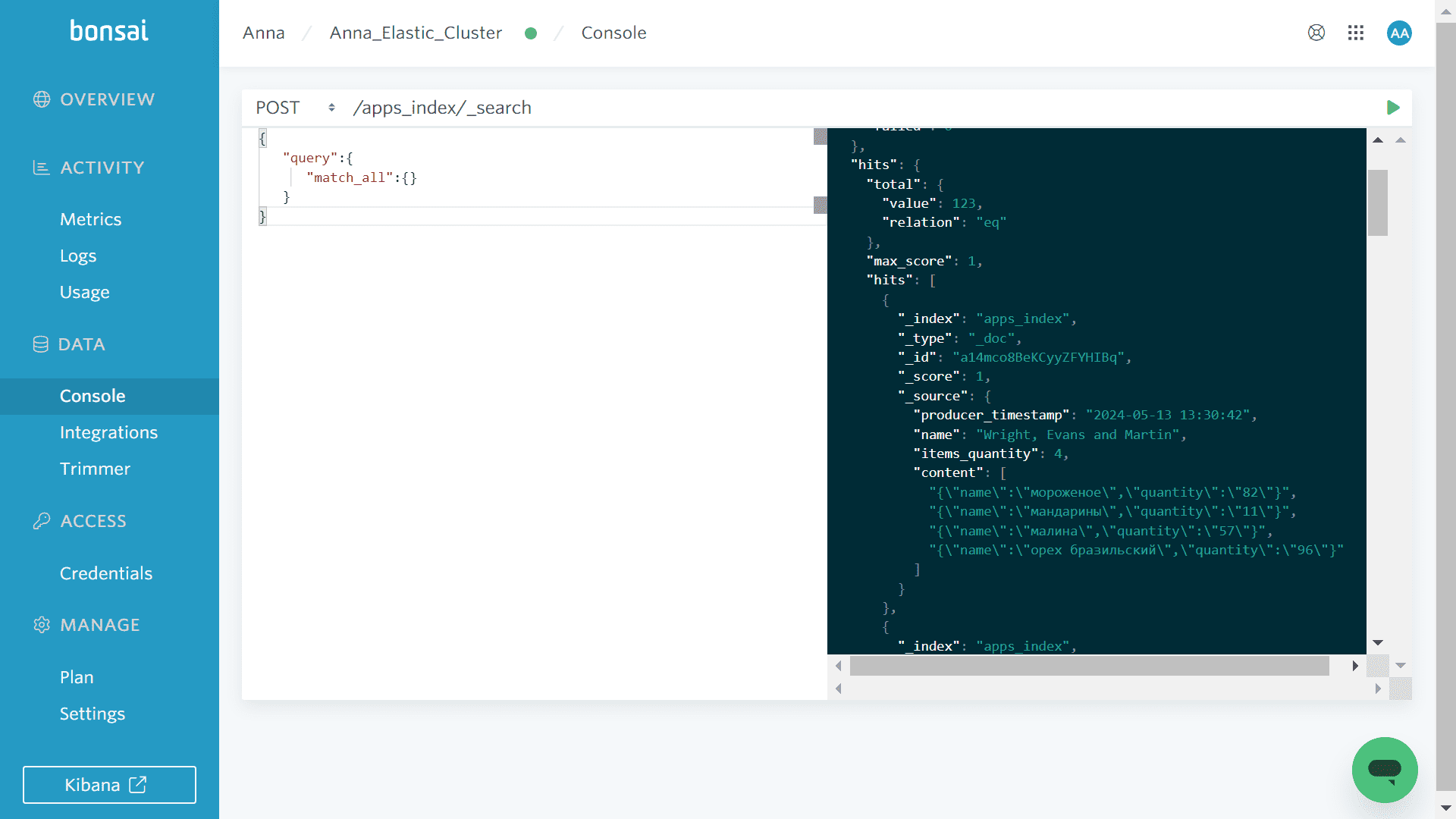
Проверить, что данные, потребленные из Kafka, попадают в систему-приемник, т.е. Elasticsearch, можно из интерфейса самой это NoSQL-СУБД с помощью API поиска, отправив POST-запрос к /apps_index/_search с полезной нагрузкой для просмотра всех результатов:
{
"query":{
"match_all":{}
}
}
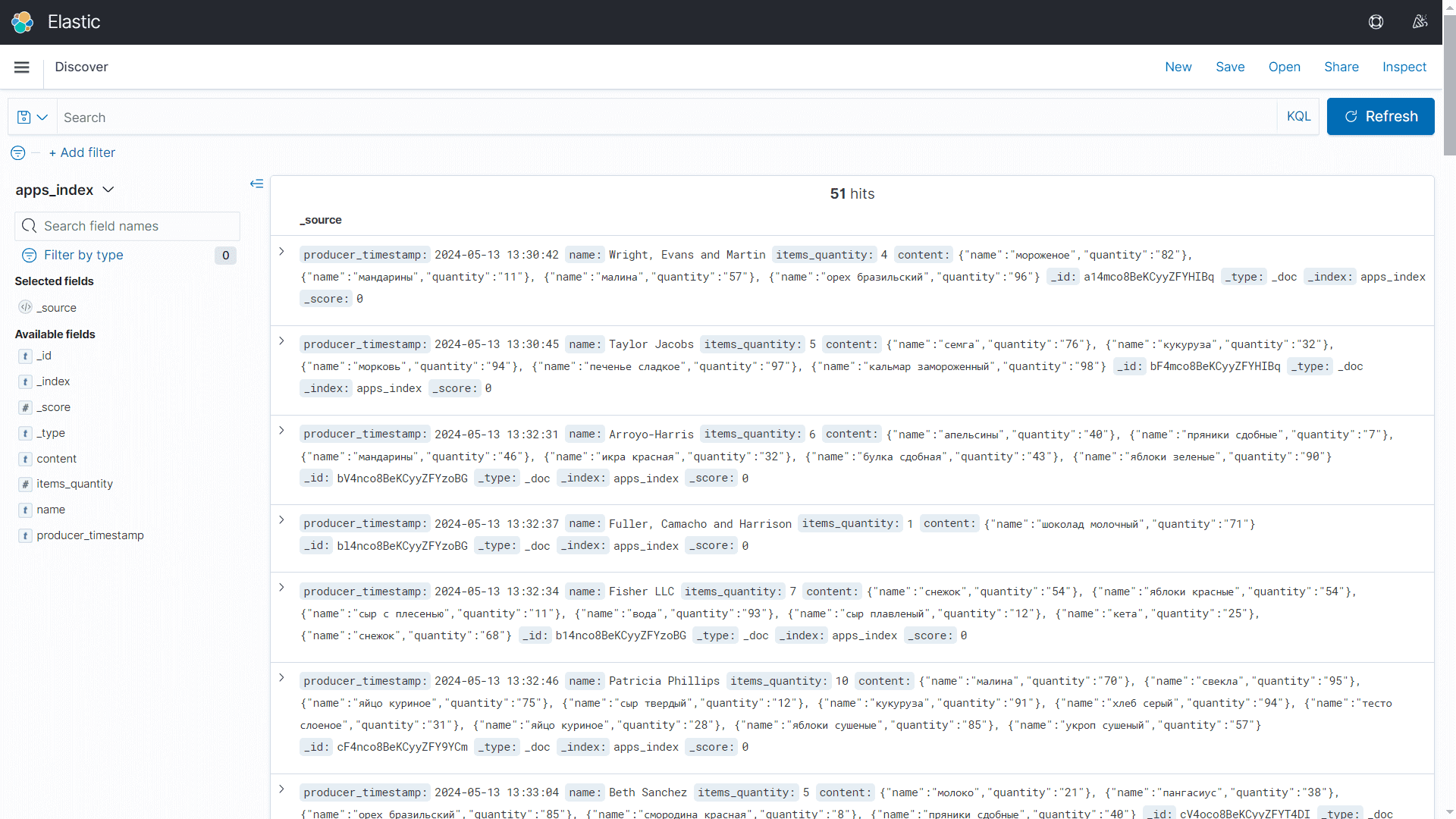
Более наглядный вид содержимого индекса показывает веб-интерфейс панелей Kibana, интегрированный с Elasticsearch
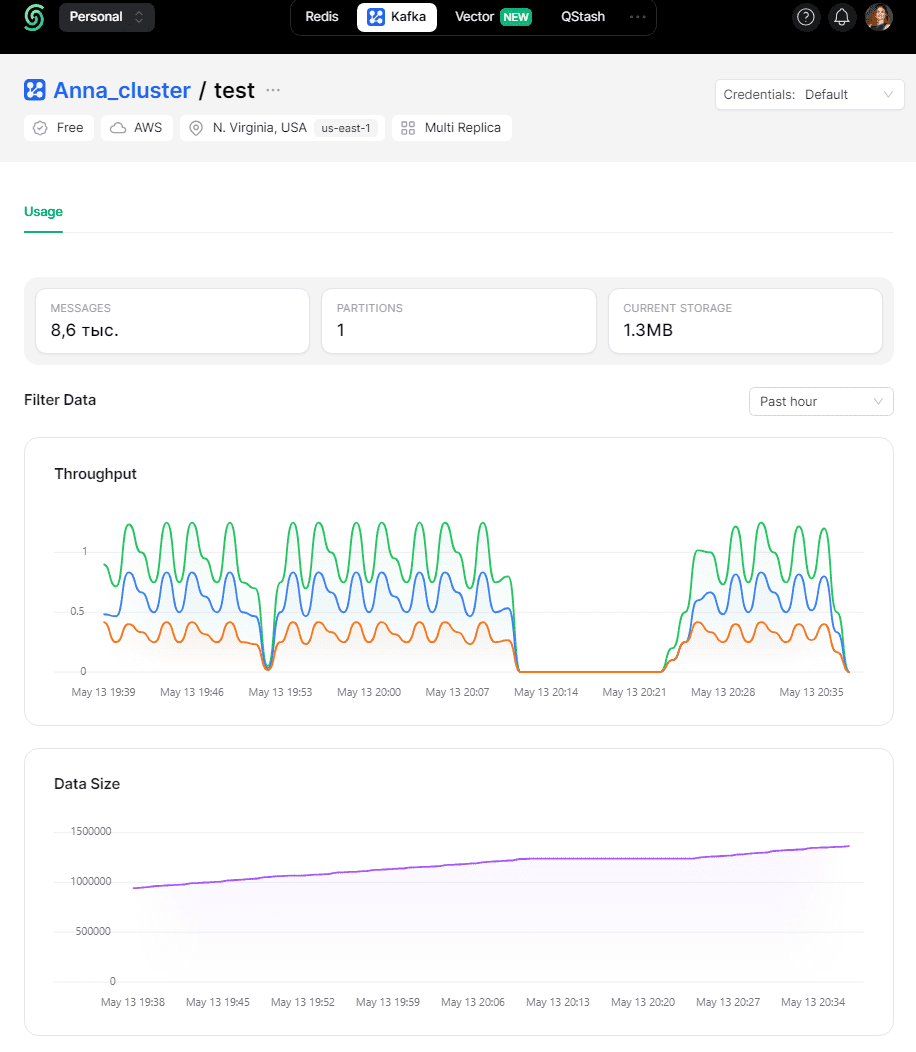
Разумеется, вся информация о публикации и потреблении данных отображается в GUI веб-развертывания Kafka.
Разумеется, для практического использования полученной из Kafka информации, конвейер должен включать больше операций преобразования данных. В частности, чтобы построить поминутную или почасовую гистограмму получения заявок в Kibana, необходимо преобразовать типы полей индекса, чтобы поле producer_timestamp было не строкой, а датой и временем. Кроме того, следует преобразовать поле content, рассматривая его как документ, чтобы выполнять поиск по названию и количеству заказанных продуктов, а также строить по ним различные визуализации. Для этого SQL-запрос, преобразующий поток исходных данных из Kafka, будет намного сложнее. Аналогичный практический пример потоковой агрегации данных из Kafka с помощью SQL-запросов читайте в моей новой статье про потоковую базу данных RisingWave.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Основы Apache Kafka
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
Источники

